
Overview#
Important
Please note that this tutorial is for learning purposes only. See Solution | Maintenance Performance and Planning for a pre-built project capability of solving problems in this industry.
Business case#
We’re part of the data team of an important OEM company working on a predictive maintenance use case. Our goal is to create a system that, based on the vehicle’s sensor data, will trigger some preventive maintenance actions.
Unexpected problems on the road are inconvenient to customers. With this in mind, the company wants to send a message to those cars that are more likely to break down before a problem occurs, thereby minimizing the chance of a car breaking down on a customer. At the same time, requesting otherwise healthy vehicles too often would not be cost-effective either.
The company has some information on past failures, as well as on car usage and maintenance. As the data team, we’re here to offer a data-driven approach. More specifically, we want to use the information we have to answer the following questions:
What are the most common factors behind these failures?
Which cars are most likely to fail?
These questions are interrelated. As a data team, we’re looking to isolate and understand which factors can help predict a higher probability of vehicle failure. To do so, we’ll build end-to-end predictive models in Dataiku. We’ll see an entire advanced analytics workflow from start to finish. Hopefully, its results will end up as a data product that promotes customer safety and has a direct impact on the company’s bottom line!
Supporting data#
We’ll need three datasets in this tutorial. Find their descriptions and links to download below:
usage: number of miles the cars have been driven, collected at various points;
maintenance: records of when cars were serviced, which parts were serviced, the reason for service, and the quantity of parts replaced during maintenance;
failure: whether a vehicle had a recorded failure (not all cases are labelled).
An Asset ID, available in each file, uniquely identifies each car. Some datasets are organized at the vehicle level. Others aren’t. A bit of data detective work might be required!
Workflow overview#
By the end of this walkthrough, your workflow in Dataiku should mirror the one below.
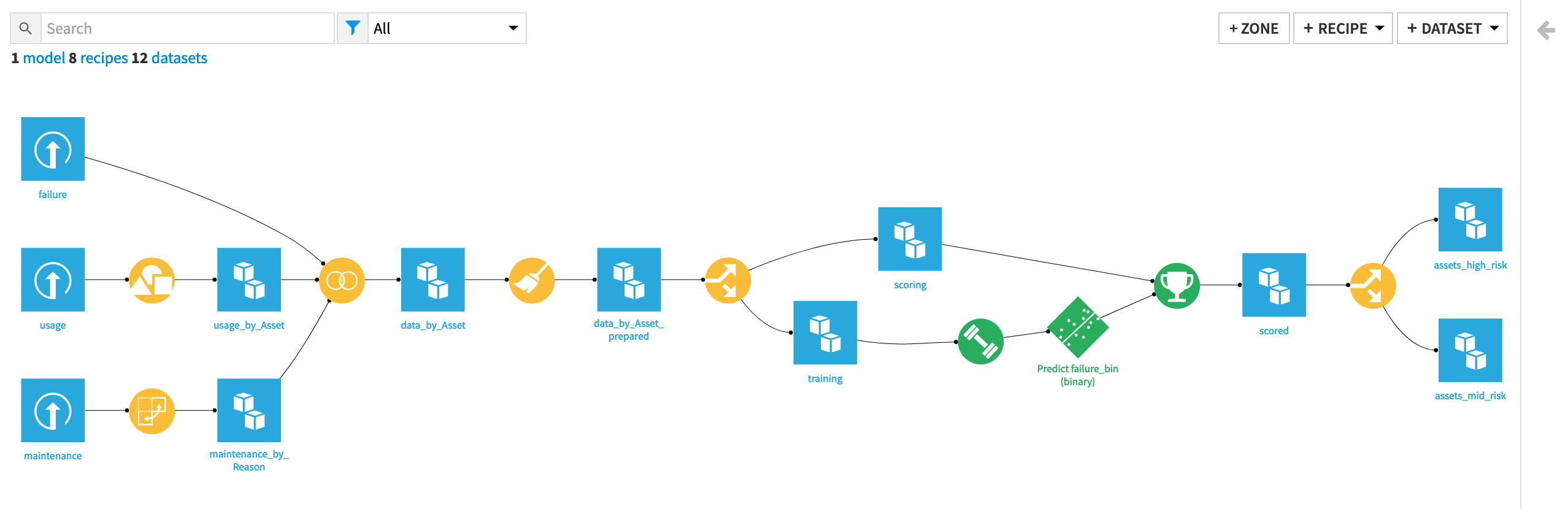
To achieve this workflow, we will complete the following high-level steps:
Import the data.
Clean, restructure and merge the input datasets together.
Generate features.
Split the data by whether outcomes are known and unknown (that is, labelled and unlabelled).
Train and analyze a predictive model on the known cases.
Score the unlabelled cases using the predictive model.
Batch deploy the project to a production environment (optional).
Prerequisites#
You should be familiar with:
Dataiku basics (Core Designer or equivalent)
Visual machine learning in Dataiku, such as in ML Basics
Technical requirements#
To complete this walkthrough, the following requirements need to be met:
Have access to a Dataiku instance–that’s it!
If you plan to also batch deploy the project (the final step in our end-to-end pipeline), you’ll also need an Automation node connected to your Design node.