
Defining the problem and creating the target#
When building a churn prediction model, a critical step is to define churn for your particular problem, and determine how it can be translated into a variable that can be used in a machine learning model. The definition of churn is totally dependent on your business model and can differ widely from one company to another.
For this tutorial, we’ll use a simple definition: a churner is someone who hasn’t taken any action on the website for 4 months. We have to use a short time frame here, because our dataset contains a limited history (1 year and 3 months of data). Since many customers visit the website only once, we will focus on the “best” clients, those who generate most of the company revenue.
Our definition of churn can then be translated into the following rules:
The target variable (i.e the one we want to model) is built by looking ahead over a 4 month period from a reference date, and flagging the customers with a “1” if they purchased a product on this time frame and “0” otherwise.
We’ll restrict our data to the customers who made at least one purchase in the previous 4 months, and total purchases at least 30 in value. This rule is to make sure we only look at the high value customers.
To create our first training dataset, we will first need to join the Products_psql and Events_psql datasets that have been synced to PostgreSQL. To do so, you can either create a new SQL recipe and write a join query yourself, or use a visual Join recipe and let Dataiku do the work for you.
For this tutorial, we will use the visual Join recipe. From the Flow screen, left click on Events_psql. From the right panel, choose the Join with recipe. When prompted, choose Products_sql as the second dataset, name the output events_complete, and make sure it will be written in your PostgreSQL connection again. Run the recipe.
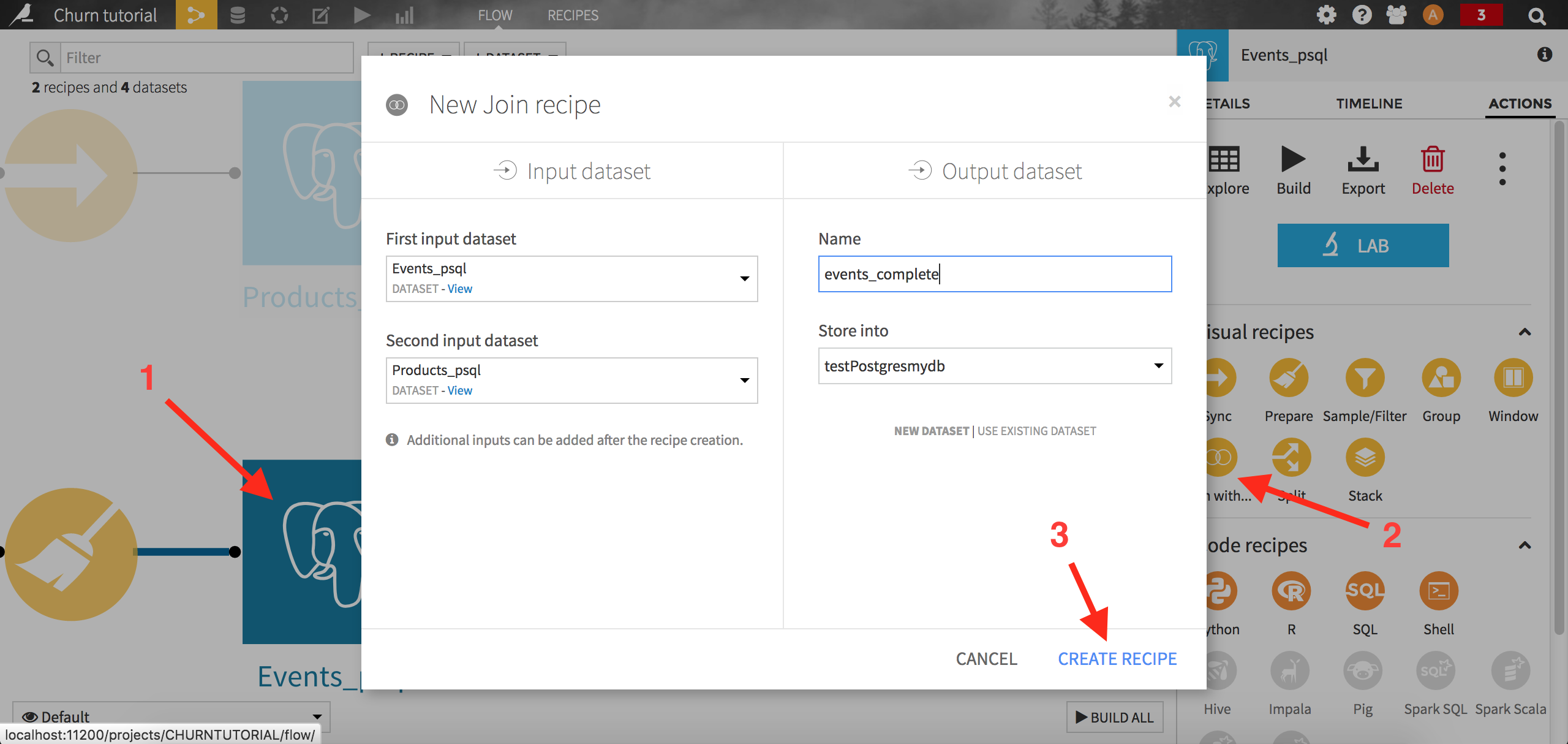
Note that you may have been able to convert the visual Join recipe into an editable SQL code recipe, by navigating to the output section (from the left bar) of the recipe, clicking on View query, then Convert to SQL recipe:
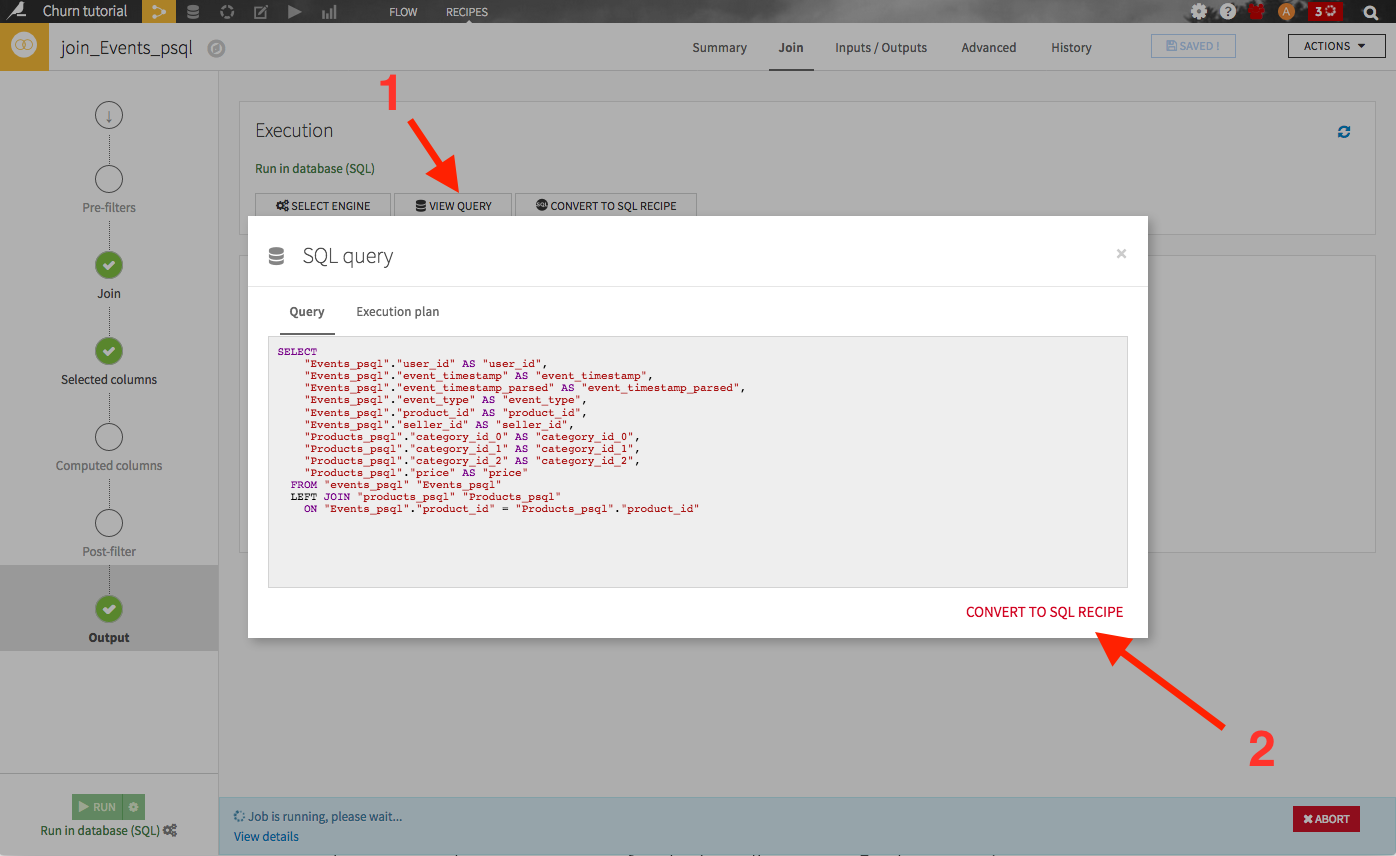
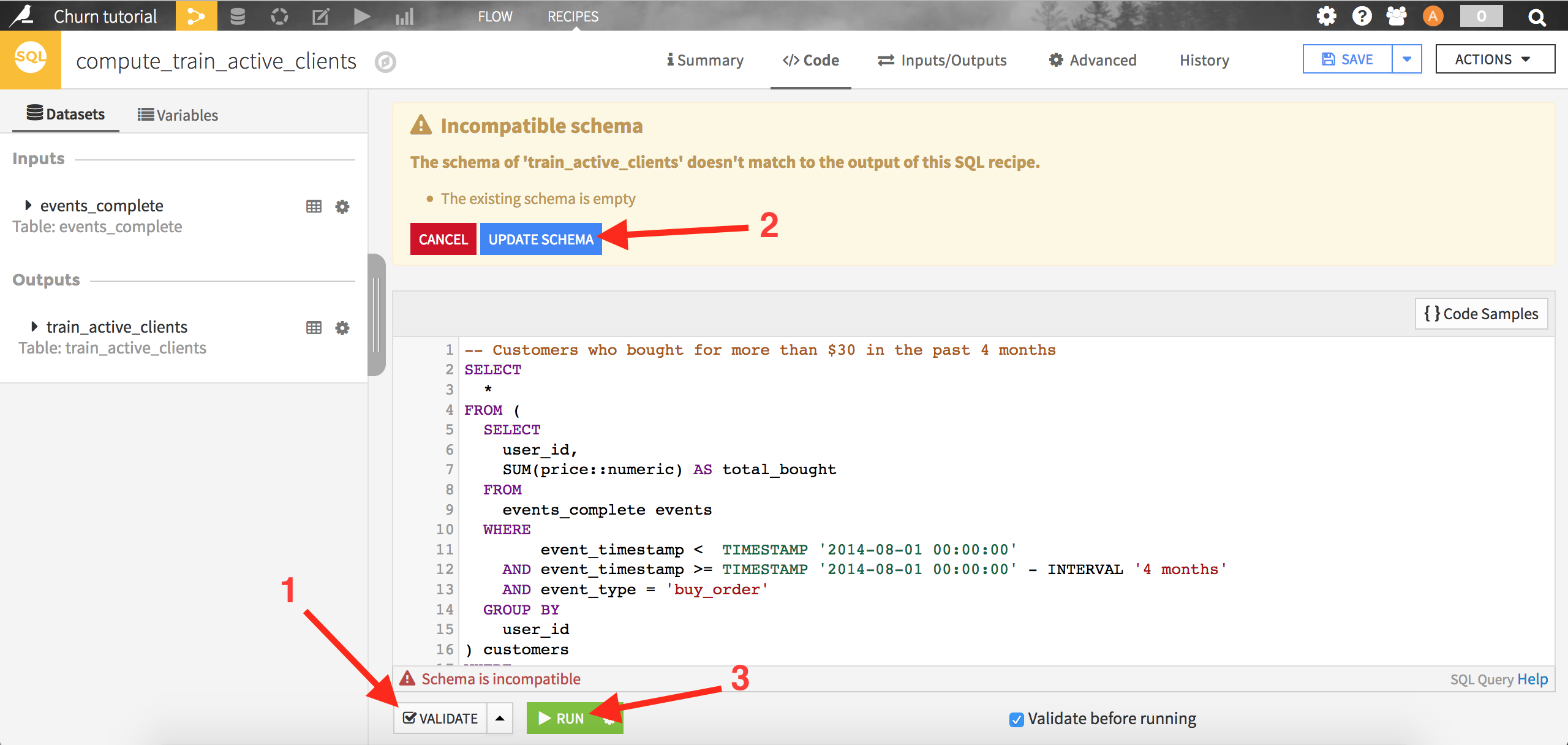
We can now create our target churn variable. For the sake of the example, let’s consider 2014-08-01 as the starting point in time, the reference date. The first step is to select our “best” clients, those who bought for more than 30 dollars of products over the past 4 months. Create an SQL recipe by clicking on the “events_complete” dataset, then on the SQL icon from the right panel:
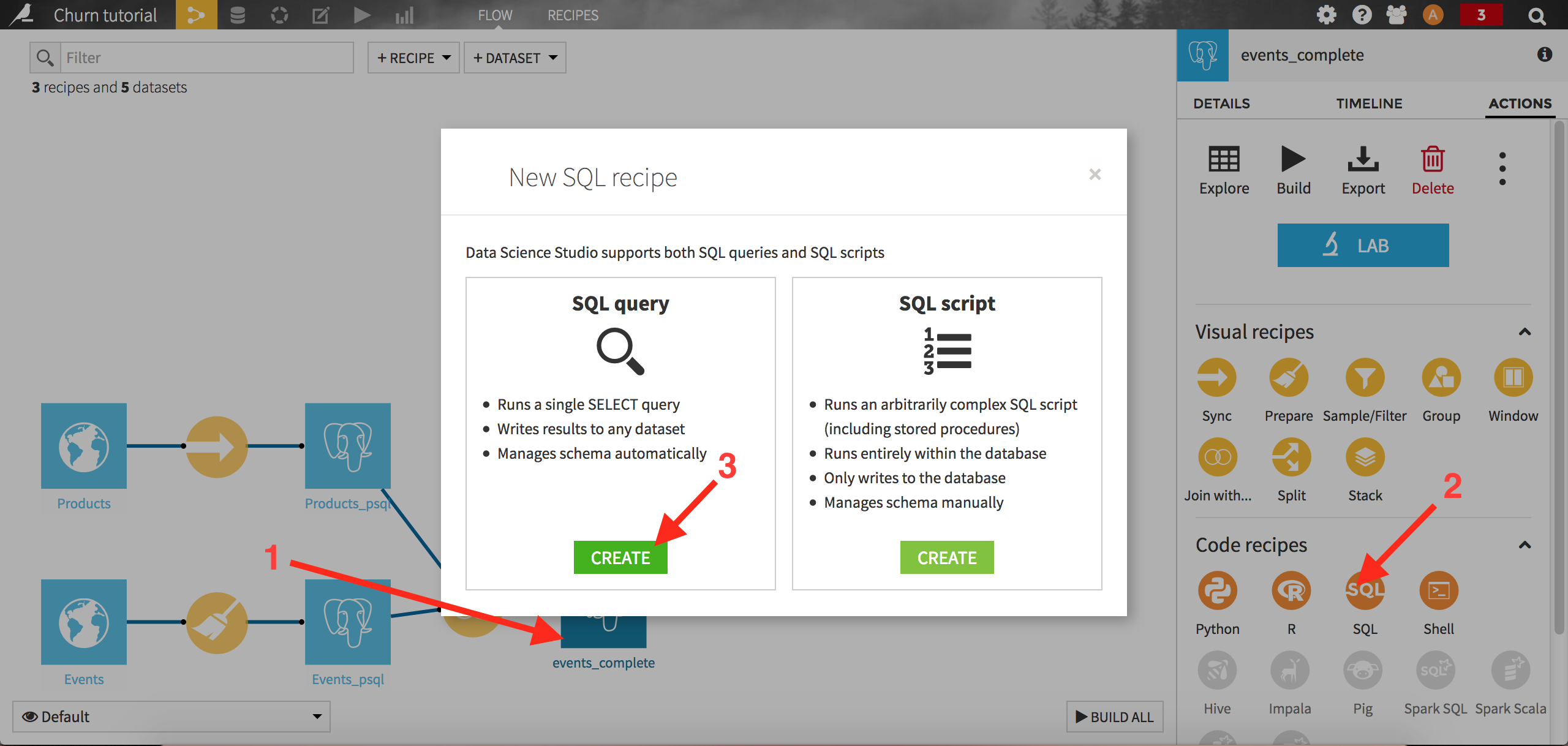
Select SQL query. Dataiku first asks you to create the output dataset. Name it train_active_clients and store it into your PostgreSQL connection. Click on Create to complete the creation of the recipe:
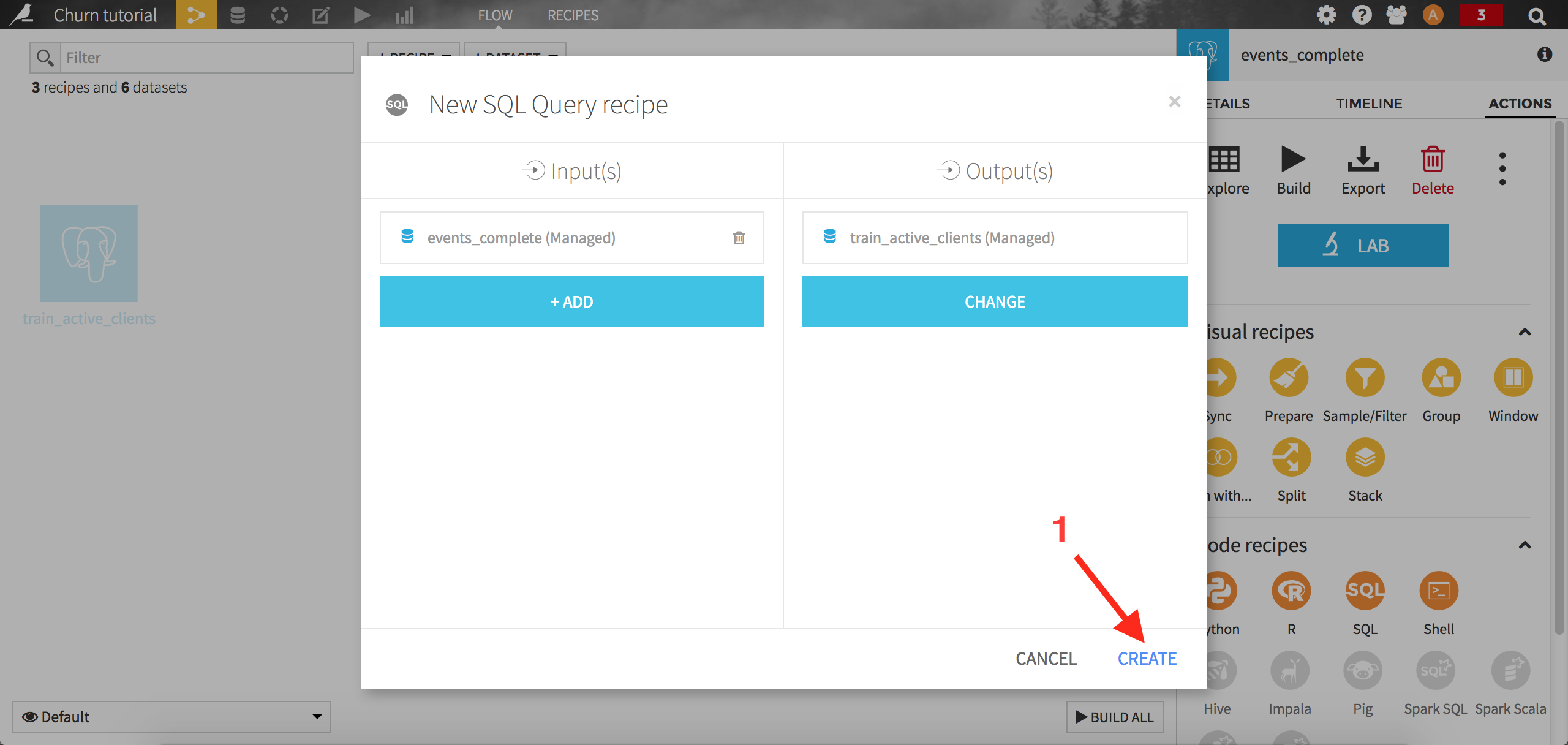
A template query is automatically generated in the code editor window. Select the best customers using the following query:
-- Customers who bought for more than $30 in the past 4 months
SELECT
*
FROM (
SELECT
user_id,
SUM(price::numeric) AS total_bought
FROM
events_complete events
WHERE
event_timestamp < TIMESTAMP '2014-08-01 00:00:00'
AND event_timestamp >= TIMESTAMP '2014-08-01 00:00:00' - INTERVAL '4 months'
AND event_type = 'buy_order'
GROUP BY
user_id
) customers
WHERE
total_bought >= 30
Note
Key concept: naming rules
If your PostgreSQL connection uses a Schema, Table prefix, or Table suffix, you will need to replace events_complete in this SQL with the appropriate table reference. For example, if you have the ${projectKey}_ Table prefix set and named the project “Churn Tutorial”, you need to use “CHURNTUTORIAL_events_complete” to reference the table in the SQL code.
This SQL query is the first component of our rule to identify churners: it simply filters the data on the purchase events occurring in the 4 months before our reference date, then aggregates it by customer to get their total spending over this period.
Click on Validate: Dataiku will ask you if you want to modify the output dataset schema, accept by clicking on Update schema. Finally, click on Run to execute the query. When the query has completed, you can click on Explore dataset train_active_clients to see the results.
The second component of our rule is to find whether our best customers will make a purchase in the 4 months after the reference date.
Create a new SQL recipe, where the inputs are train_active_clients (the one we just created above) and events_complete, and the output will be an SQL dataset named train. Copy the code below and run the query:
SELECT
customer.user_id,
CASE
WHEN loyal.user_id IS NOT NULL THEN 1
ELSE 0
END as target
FROM
train_active_clients customer
LEFT JOIN (
-- Users that actually bought something in the following 4 months
SELECT distinct user_id
FROM events_complete
WHERE event_timestamp >= TIMESTAMP '2014-08-01 00:00:00'
AND event_timestamp < TIMESTAMP '2014-08-01 00:00:00' + INTERVAL '4 months'
AND event_type = 'buy_order'
) loyal ON customer.user_id = loyal.user_id
The idea here is to join the previous list of “best” customers with the ones that will buy something in the next four months (found using the subquery “loyal”). The churners are actually flagged using the CASE statement: if the best customers don’t make a purchase in the next 4 months, they won’t be found in the list built by the subquery, hence the NULL value. Each best customer will end up flagged with a “0” if they don’t repurchase (churner), or “1” otherwise.
This marks the end of the first big step: defining what churn is, and translating it into an actual variable that can be used by a machine learning algorithm.