Create the training & scoring datasets#
Before training models, we need to split the data. We will use the Split recipe to create two separate datasets from the merged and prepared dataset:
a training dataset will contain labels for whether there was a failure event on an asset. We’ll use it to train a predictive model.
a scoring dataset will contain no data on failures, that is, unlabelled, so we’ll use it to predict whether these assets have a high probability of failure.
Here are the detailed steps:
From the data_by_Asset_prepared dataset, initiate a Split recipe.
Add two output datasets, named
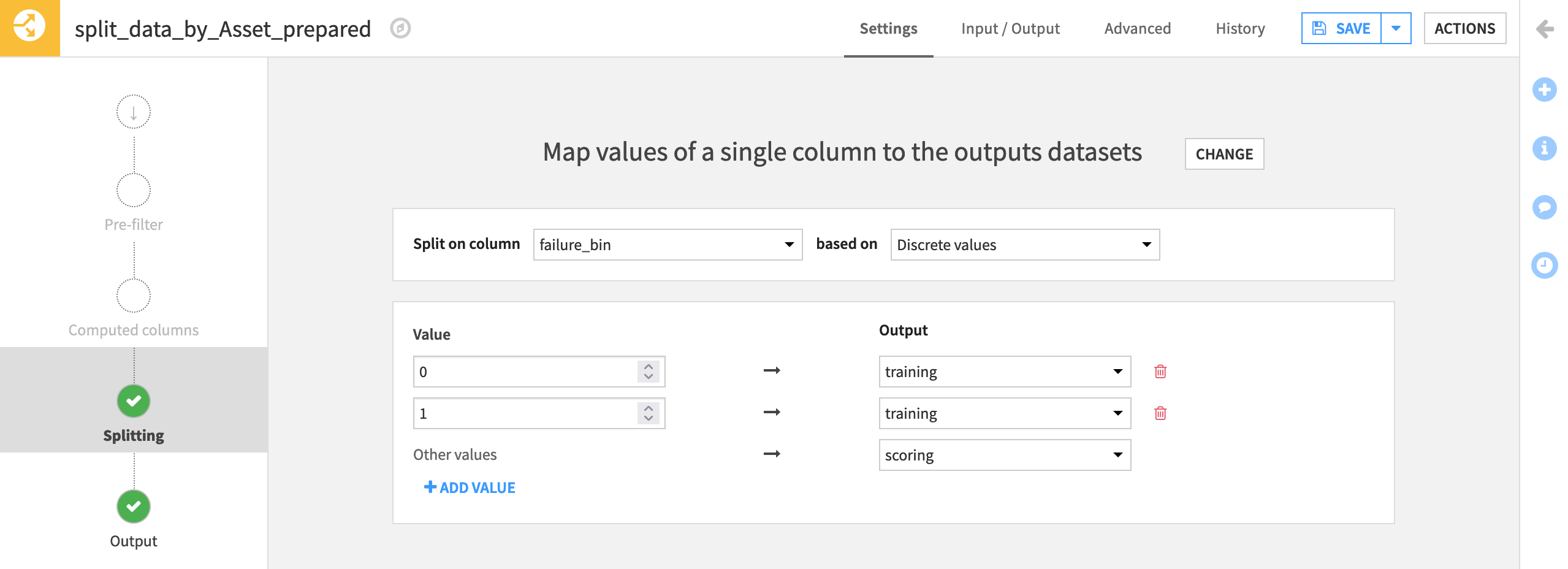
trainingandscoring, selecting Create Dataset each time. Then Create Recipe.At the Splitting step, choose to Map values of a single column.
Then choose failure_bin as the column to split on discrete values.
Assign values of 0 and 1 to the training set, and all “Other values” to the scoring set. (From the Analyze tool, we can see that these are the only possible values).
Run the recipe, and confirm the training dataset has 1,624 rows, and the scoring dataset has 195.