Create the prediction model#
Now that we have a dataset ready on which to train models, let’s use machine learning to predict car breakdown.
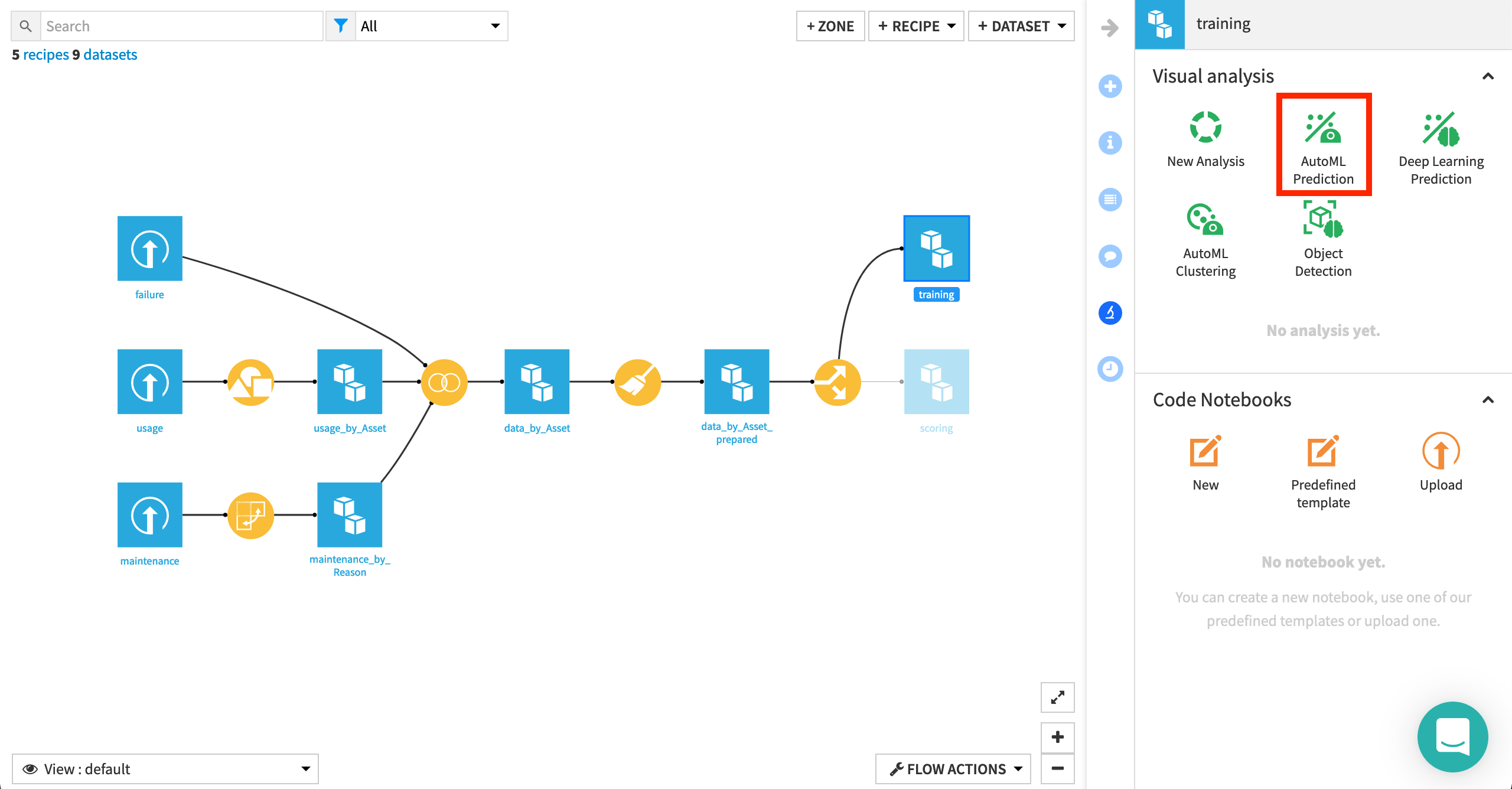
With the training dataset selected, click on AutoML Prediction in the Lab of the right panel.
Choose failure_bin as the target variable.
Note
Our goal is to predict a target variable (including labels), given a set of input features, and so we know this is a supervised learning problem, as opposed to clustering, or object detection for example.
You can learn more about this process in the Machine Learning Basics course.
Once we have picked the type of machine learning problem and target variable, we can choose between various kinds of AutoML or Export modes.
Leave the default Quick Prototypes, and click Create.
Click Train to build models using the default settings and algorithms, and wait for the results of the first training session.
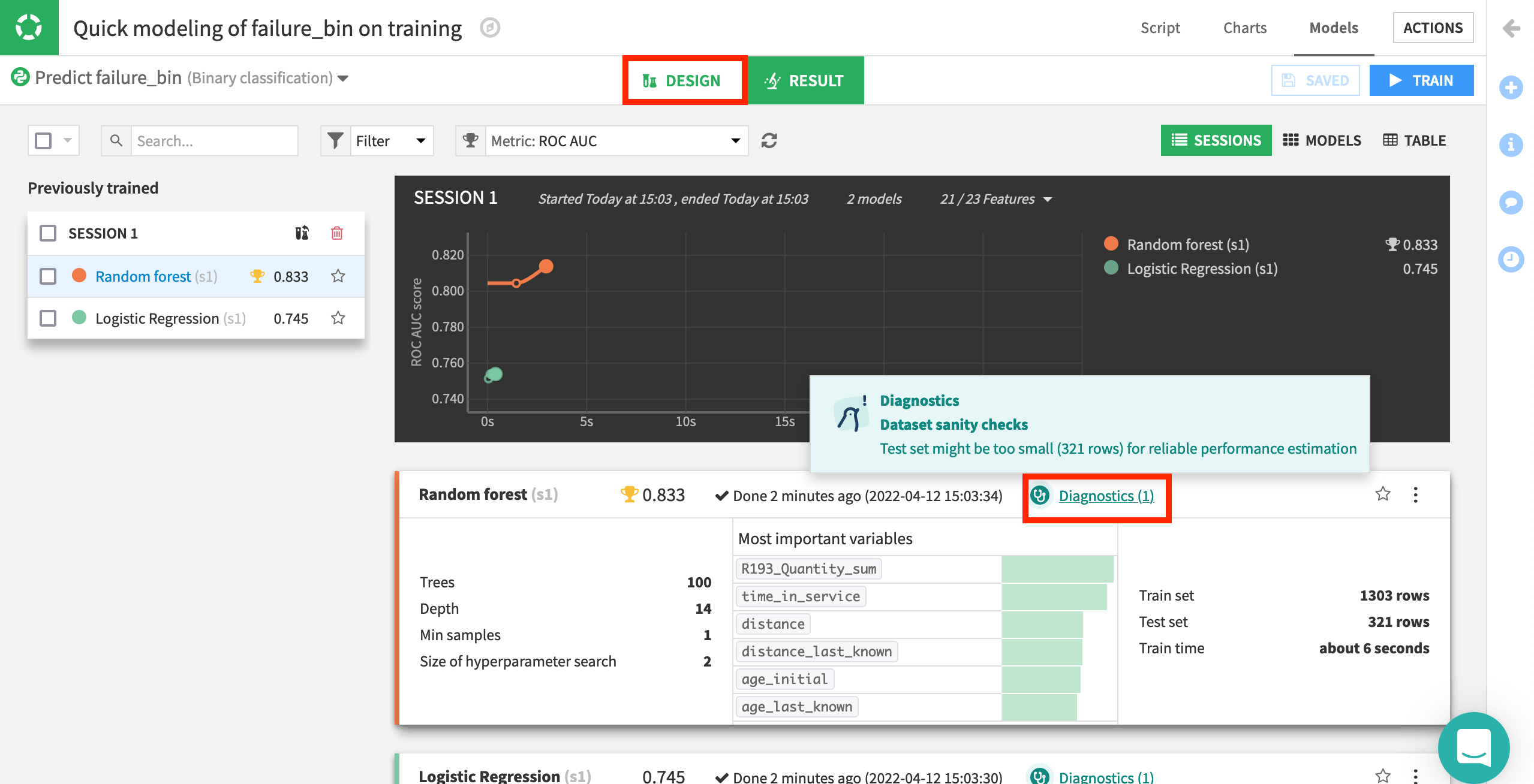
Note
In the Results tab, you’ll notice each model has one diagnostic warning. This is Dataiku’s way of alerting us to potential machine learning problems—in this case, a dataset sanity check drawing attention to our small test set. For our purposes, we can ignore the warning. You can learn more about ML diagnostics in the reference documentation.
Once we have the results of some initial models, we can return to the Design tab to adjust all settings and train more models in additional settings if we wish.
Click on the Design tab to view the settings used to train the models in the first session.
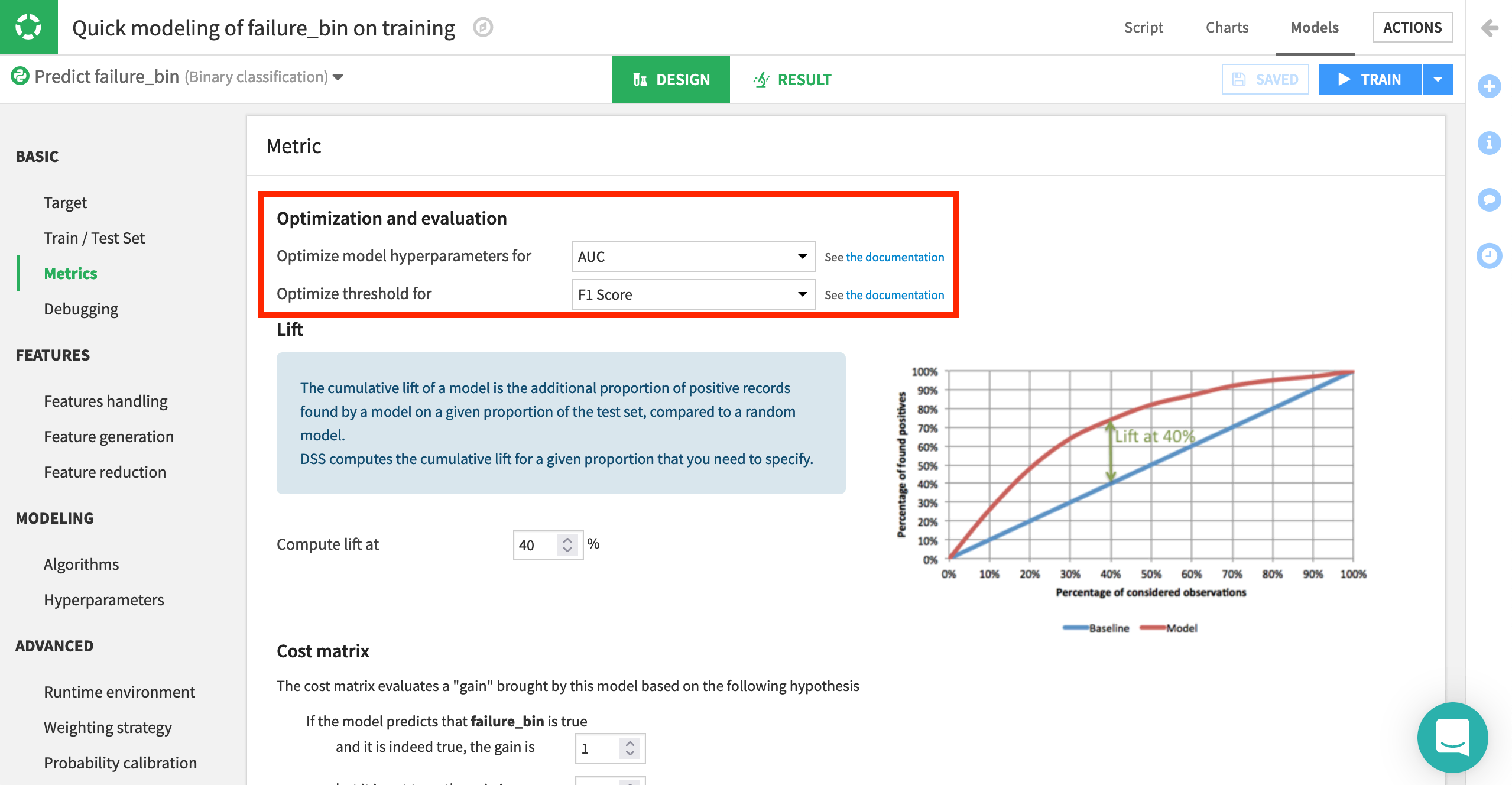
Navigate to the Basic > Metrics page from the left panel.
Here, we can define how we want model selection to occur. With these default settings, the platform optimizes for AUC (Area Under the Curve). That is, it picks the model with the best AUC, while the threshold (or probability cut-off) is selected to give the best F1 score. Similarly, feature engineering can also be tailored as needed, from which/how features are used, as well as options for dimension reduction.
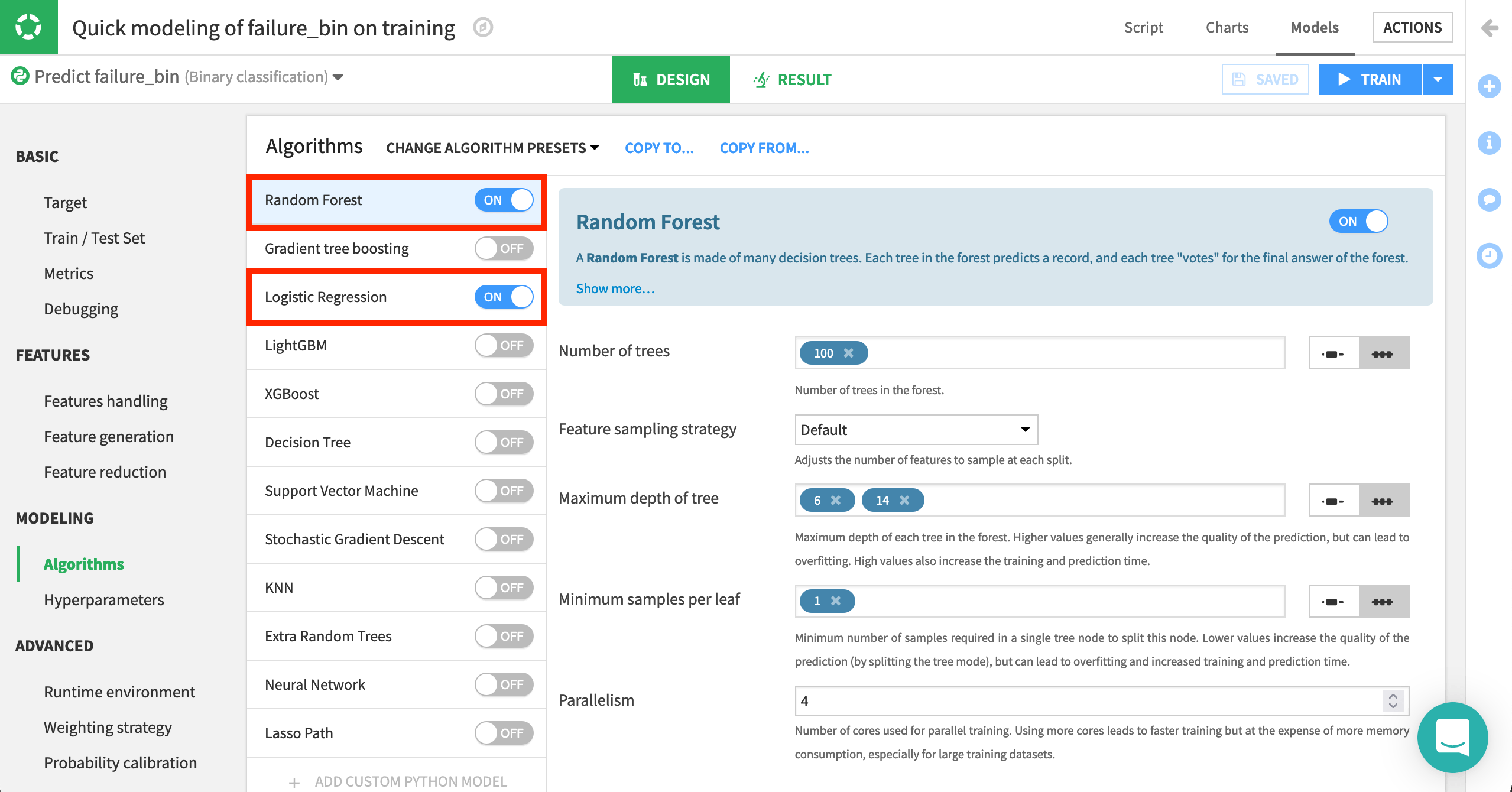
Another important setting is the type of algorithms with which to model the data.
Navigate to Modeling > Algorithms.
Here, we can select which native or custom algorithms to use for model training. In addition, we can define hyperparameters for each of them. For now, we’ll continue using two machine learning algorithms: Logistic Regression and Random Forest. They come from two classes of algorithms popular for these kinds of problems, linear and tree-based respectively.