
Run more model evaluations#
Before diving into the meaning of these metrics, let’s add more data to the pipelines. This will enable more comparisons between the model’s training data and the new “production” data found in the new_transaction_data folder.
Get a new month of transactions#
In the Model Scoring Flow zone, navigate to the Settings tab of the new_transactions dataset.
In the Files subtab, confirm that the Files selection field is set to Explicitly select files.
Click the trash can (
 ) to remove /transactions_prepared_2017_04.csv.
) to remove /transactions_prepared_2017_04.csv.On the right, click List Files to refresh.
Check the box to include /transactions_prepared_2017_05.csv.
Click Save.
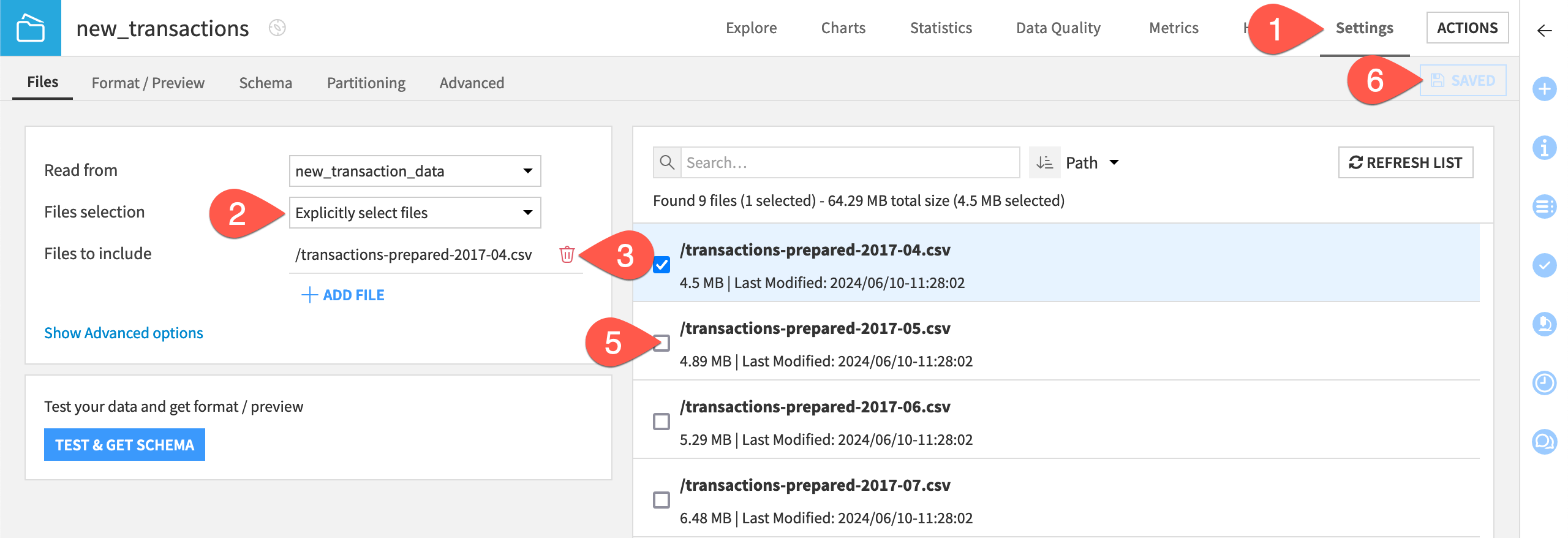
Refresh the page to confirm that the dataset now only contains data from May.
Rebuild the MES for input drift monitoring#
You can immediately evaluate the new data in the Input Drift Monitoring Flow zone.
In the Input Drift Monitoring Flow zone, select the mes_for_input_drift.
In the Actions (
 ) tab of the right panel, select Build.
) tab of the right panel, select Build.Click Build Evaluation Store with the Build Only This setting.
Rebuild the MES for ground truth monitoring#
For ground truth monitoring, you first need to send the data through the Score recipe to maintain consistency.
In the Ground Truth Monitoring Flow zone, select the mes_for_ground_truth.
In the Actions (
) tab of the right panel, select Build.Select Build Upstream.
Click Preview to confirm that the job will run first the Score recipe and then the Evaluate recipe.
Click Run.
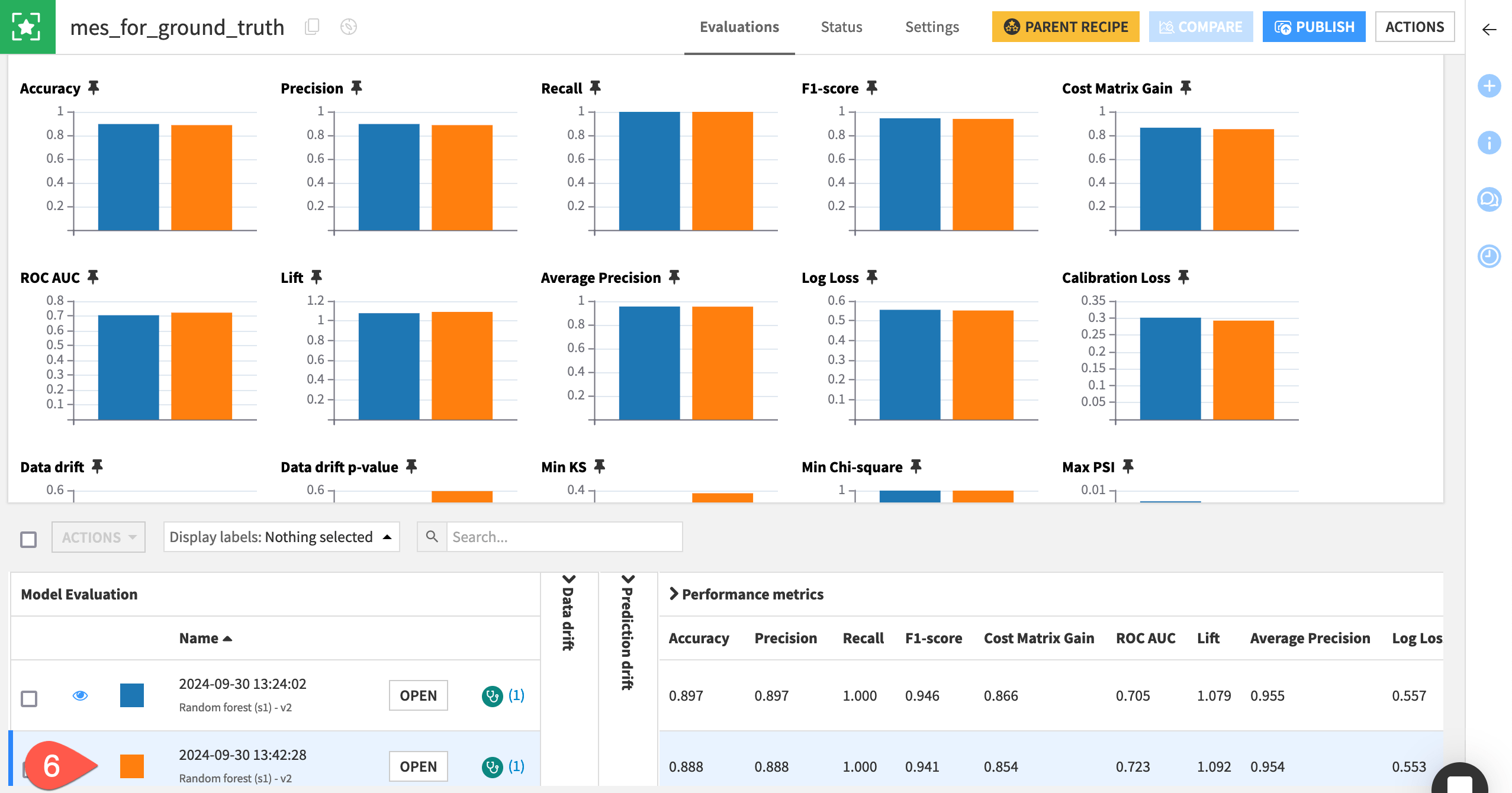
Open the mes_for_ground_truth to find a second model evaluation when the job has finished.
Tip
At this point, both model evaluation stores should have two rows (two model evaluations). Feel free to repeat the process above for the months of June and beyond so that your model evaluation stores have more data to compare.