
Automate model monitoring#
You don’t want to manually build the model evaluation stores every time new data is available. You can automate this task with a scenario.
In addition to scheduling the computation of metrics, you can also automate actions based on the results. For example, the goal may be to retrain the model if a metric such as data drift exceeds a certain threshold. Let’s create the bare bones of a scenario to accomplish this kind of objective.
Note
This case monitors a MES metric using a check. You can also monitor datasets with data quality rules.
Create a check on a MES metric#
The first step is to choose a metric important to the use case. Since it’s one of the most common, let’s choose data drift.
Tip
This example chooses a data drift threshold to demonstrate an error. Defining an acceptable level of data drift is dependent on your use case.
From the Flow, open the mes_for_input_drift, and navigate to the Settings tab.
Go to the Status checks subtab.
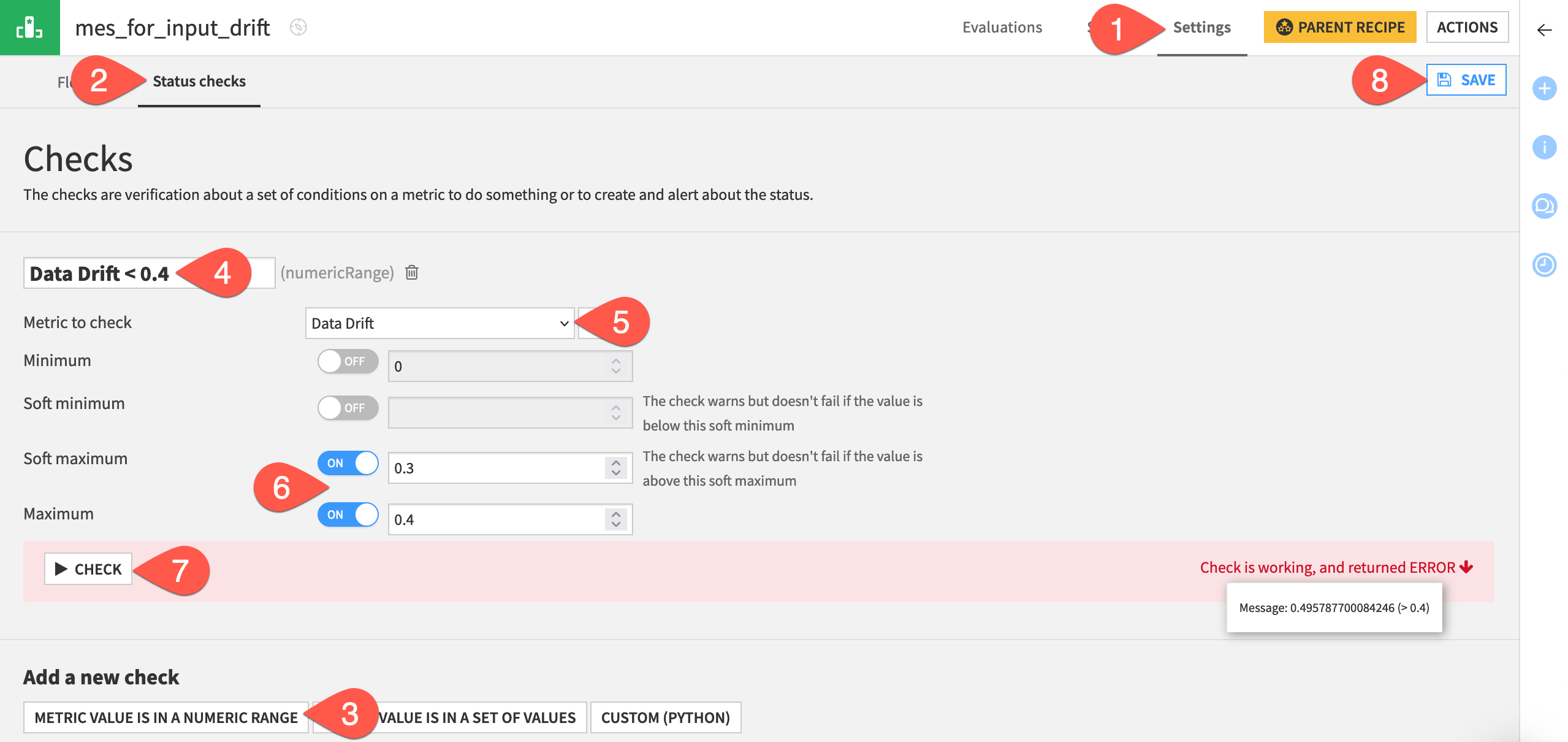
Click Metric Value is in a Numeric Range.
Name the check
Data Drift < 0.4.Choose Data Drift as the metric to check.
Set the Soft maximum to
0.3and the Maximum to0.4.Click Check to confirm it returns an error.
Click Save.
Now add this check to the display of metrics for the MES.
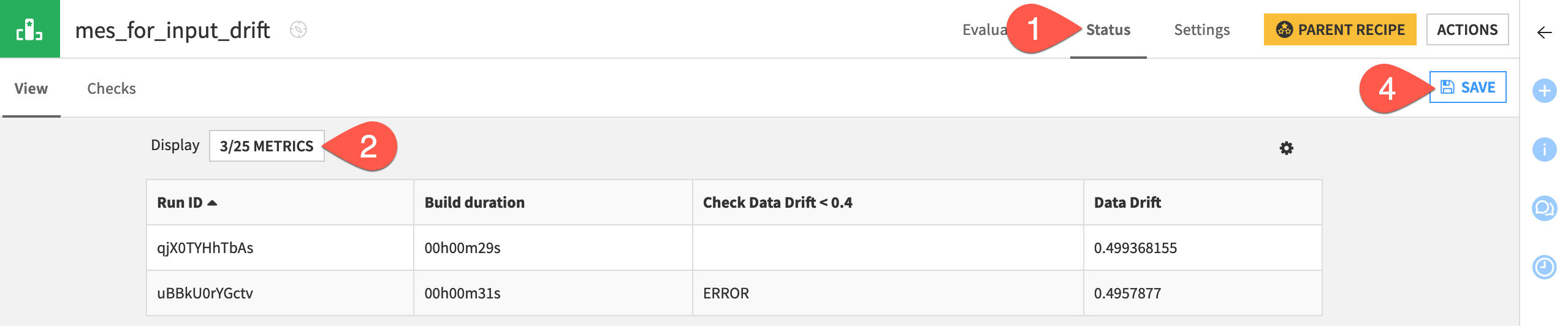
Navigate to the Status tab of the input drift MES.
Click X/Y Metrics.
Add both the data drift metric and the new check to the display.
Click Save once more.
Design the scenario#
Just like any other check, you now can use this MES check to control the state of a scenario run.
From the Jobs (
 ) menu in the top navigation bar, open the Scenarios page.
) menu in the top navigation bar, open the Scenarios page.Click + New Scenario.
Name the scenario
Retrain Model.Click Create.
First, you need the scenario to build the MES.
Navigate to the Steps tab of the new scenario.
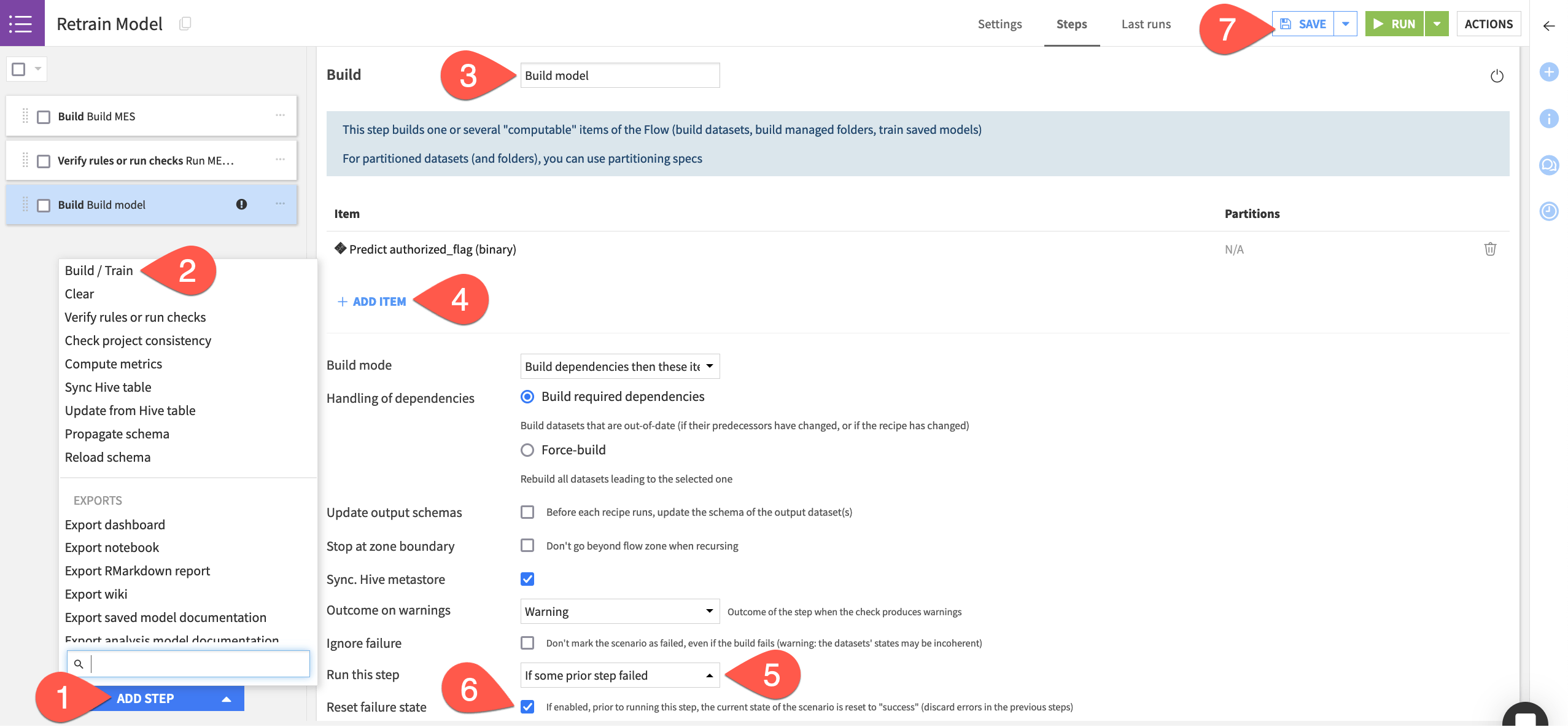
Click Add Step.
Select Build / Train.
Name the step
Build MES.Click Add Item > Evaluation store > mes_for_input_drift > Add.
Next, the scenario should run the check you’ve created on the MES.
Still in the Steps tab, click Add Step.
Select Verify rules or run checks.
Name the step
Run MES checks.Click Add Item > Evaluation store > mes_for_input_drift > Add.
Finally, you need to build the model, but only in cases where the checks fail.
Click Add Step.
Select Build / Train.
Name the step
Build model.Click Add Item > Model > Predict authorized_flag (binary) > Add.
Change the Run this step setting to If some prior step failed (that step being the Run checks step).
Check the box to Reset failure state.
Click Save when finished.
Tip
For this demonstration, you’ll trigger the scenario manually. In real cases, you’d create a trigger and a reporter. Try these features out in Tutorial | Automation scenarios and Tutorial | Scenario reporters.
Run the scenario#
Introduce another month of data to the pipeline, and then run the scenario.
In the Model Scoring Flow zone, return to the new_transactions dataset.
On the Settings tab, switch the file to the next month as done previously.
Return to the Retrain Model scenario.
Click Run to manually trigger the scenario.
Go to the Last Runs tab to observe its progression.
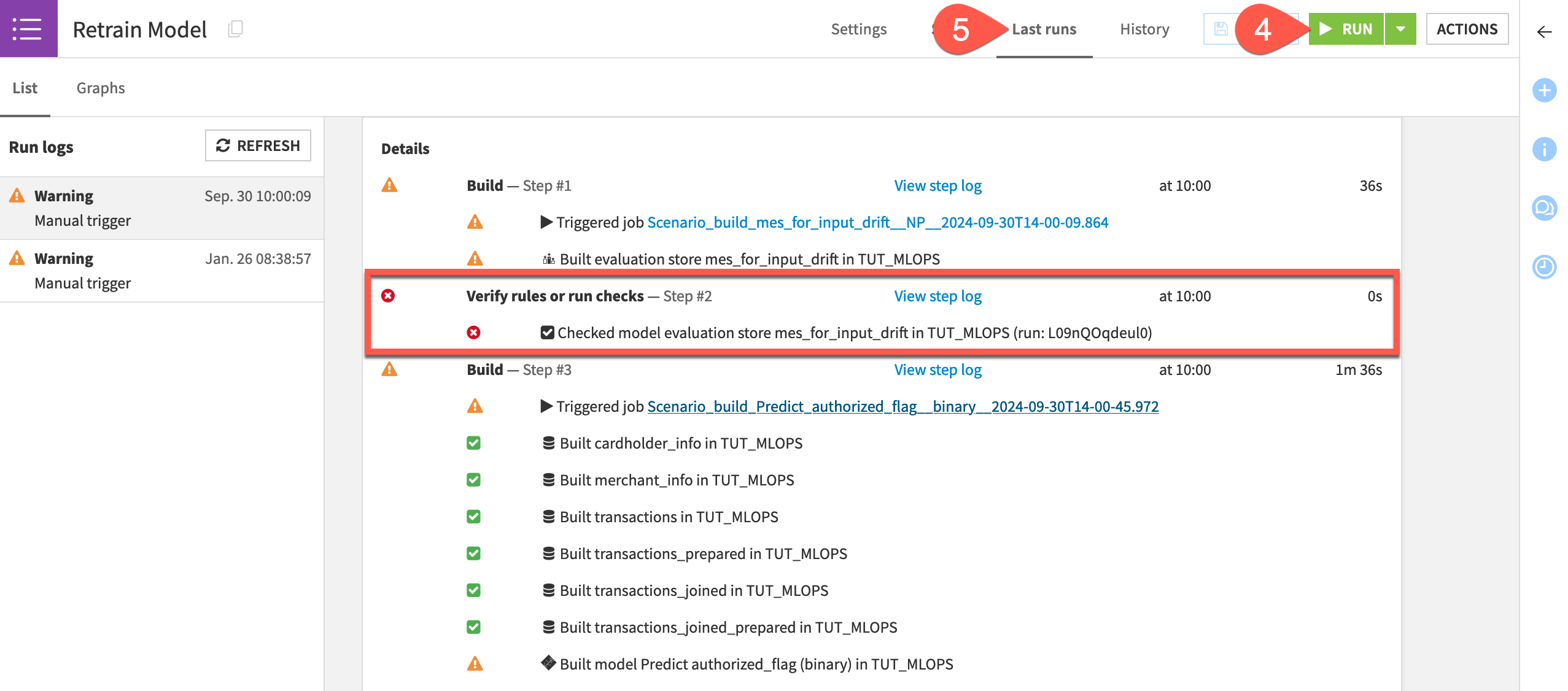
Assuming your MES check failed as intended, open the saved model in the Flow to see a new active version!
Note
This goal of this tutorial is to cover the foundations of model monitoring. But you can also think about how this specific scenario would fail to meet real world requirements.
For one, it retrained the model on the original data!
Secondly, model monitoring is a production task, and so you should move this kind of scenario to the Automation node.