
Concept | Flow views, search, and filter#
In this article, you’ll learn to inspect different details and levels of information about your Flow by using the View menu, the search bar, and the selector.
Flow views#
You can access the View menu from the top left corner of your flow. Let’s take a look at some of the available view options.
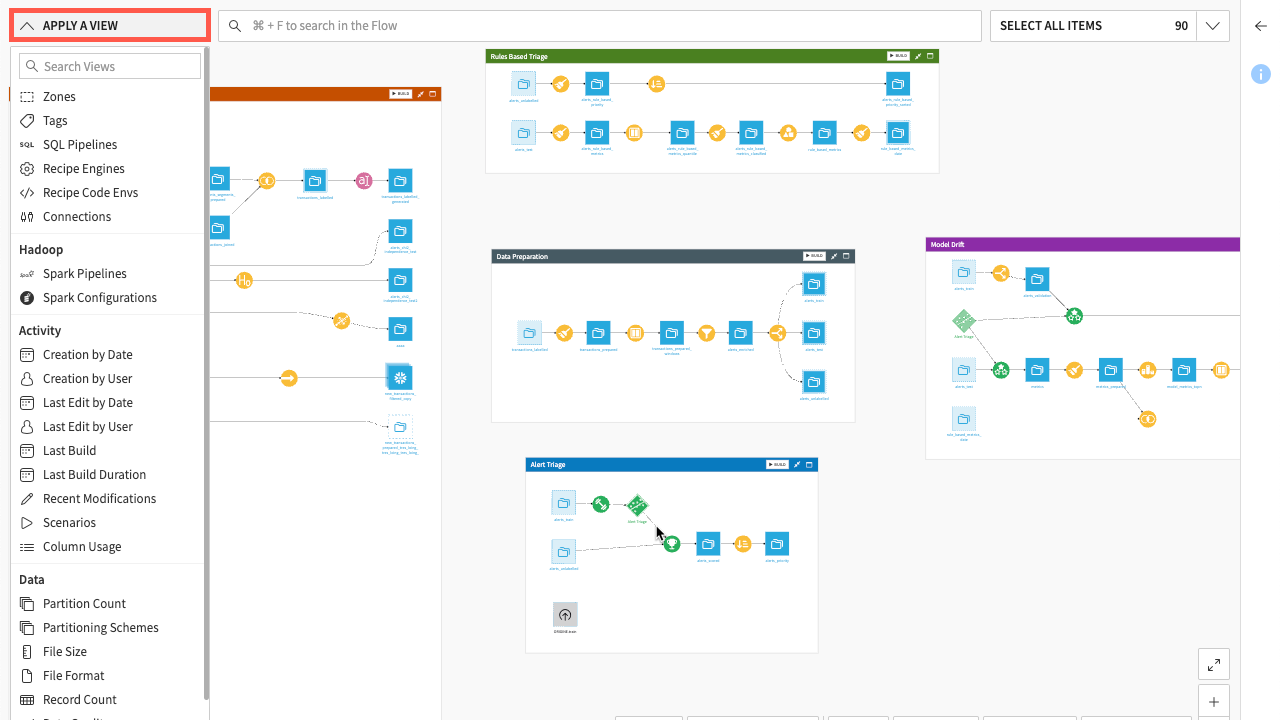
Flow zones#
A useful view for organizing your work and navigating large flows is the Flow Zones view. Here, you can view Flow zones in the project and highlight the Flow objects in selected zones.
This view of your Flow can be useful in a situation where you hide all Flow zones, but still want to see which objects are assigned to particular Flow zones.
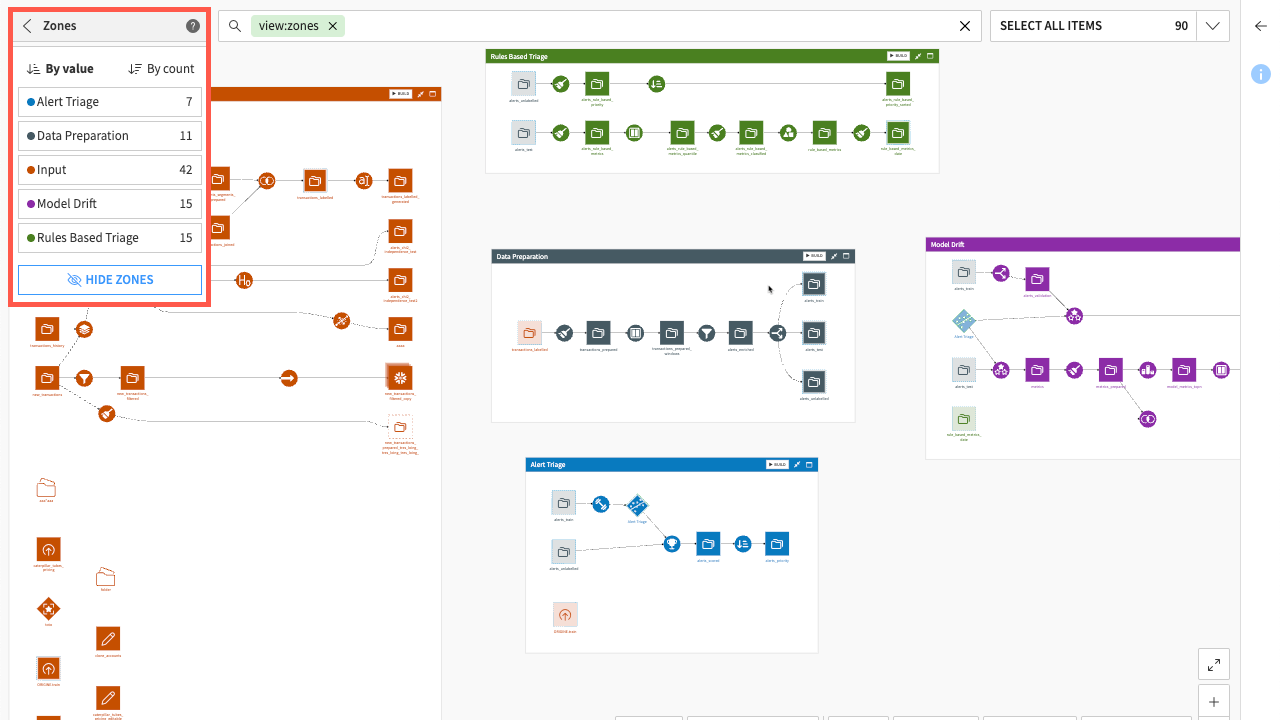
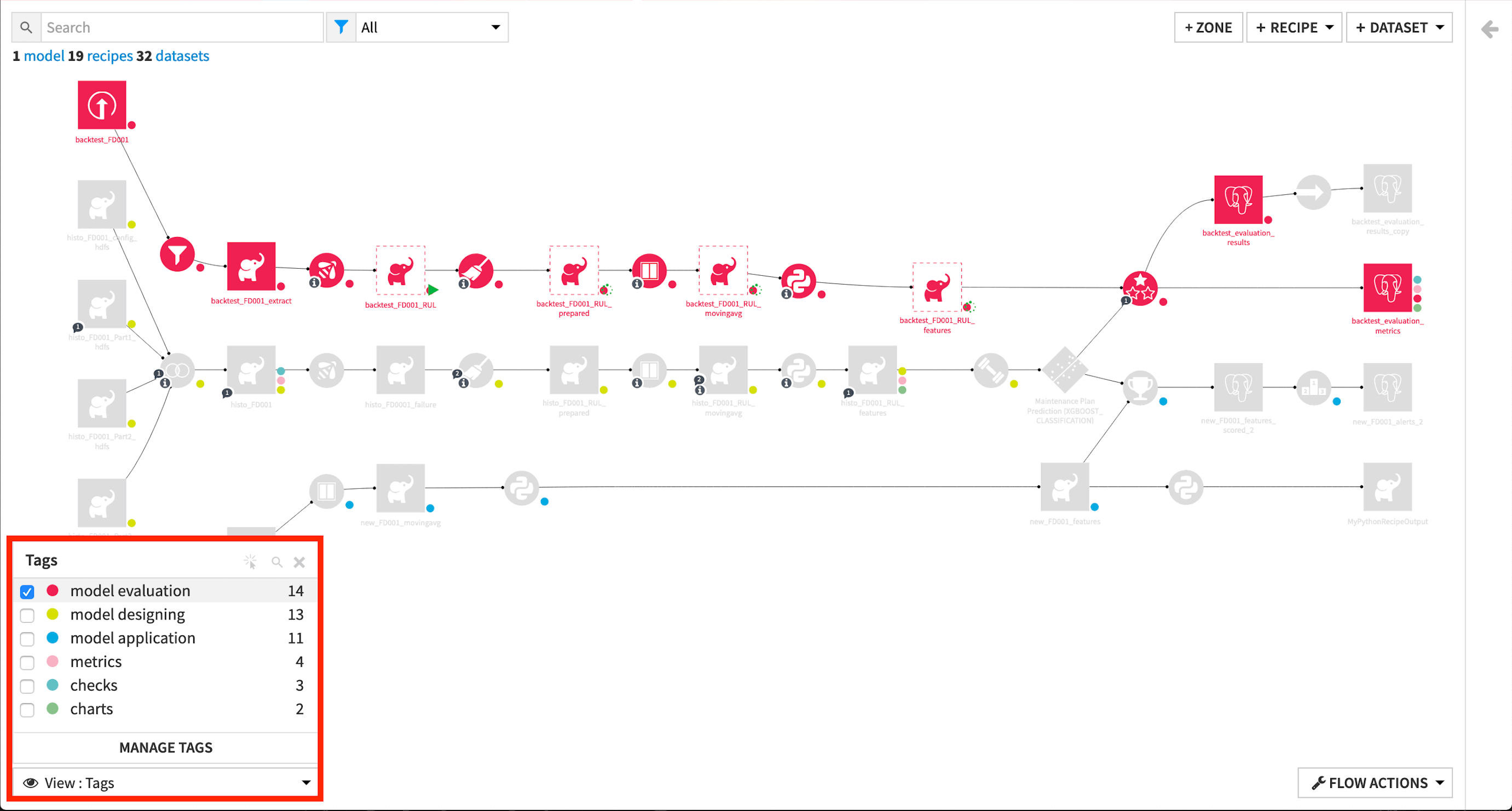
Tags#
The Tags view lets you see which objects in your Flow are associated with previously defined tags. Tags help you organize your work and understand the purpose of objects in your Flow.
In this view, objects with an associated tag are highlighted depending on the selected tags. This view can be particularly helpful for understanding large or complicated Flows or when multiple people are working on the same Flow.
The Manage Tags button is useful for adding or deleting tags from the project.
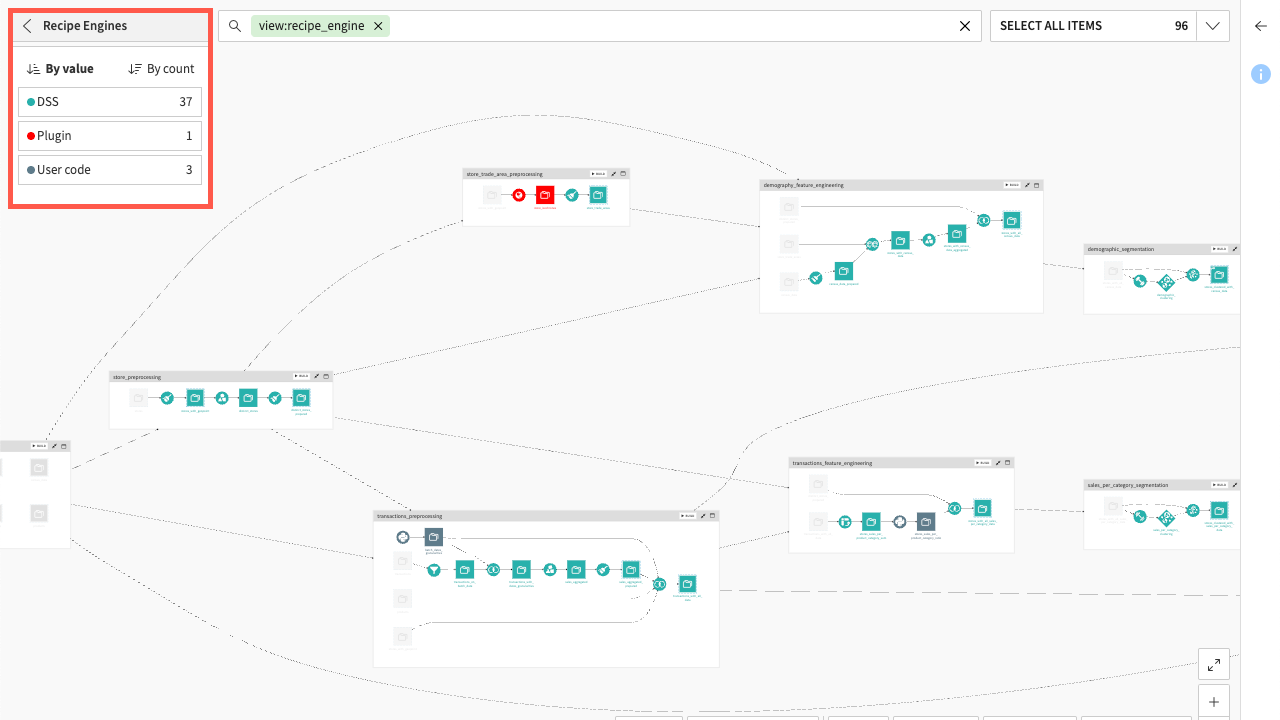
Recipe engines#
The Recipe Engines option shows you what kinds of computation engines are used in the Flow’s recipes.
For example, you could want to know what comes from an SQL, a Pyton-based user code, or a plugin engine.
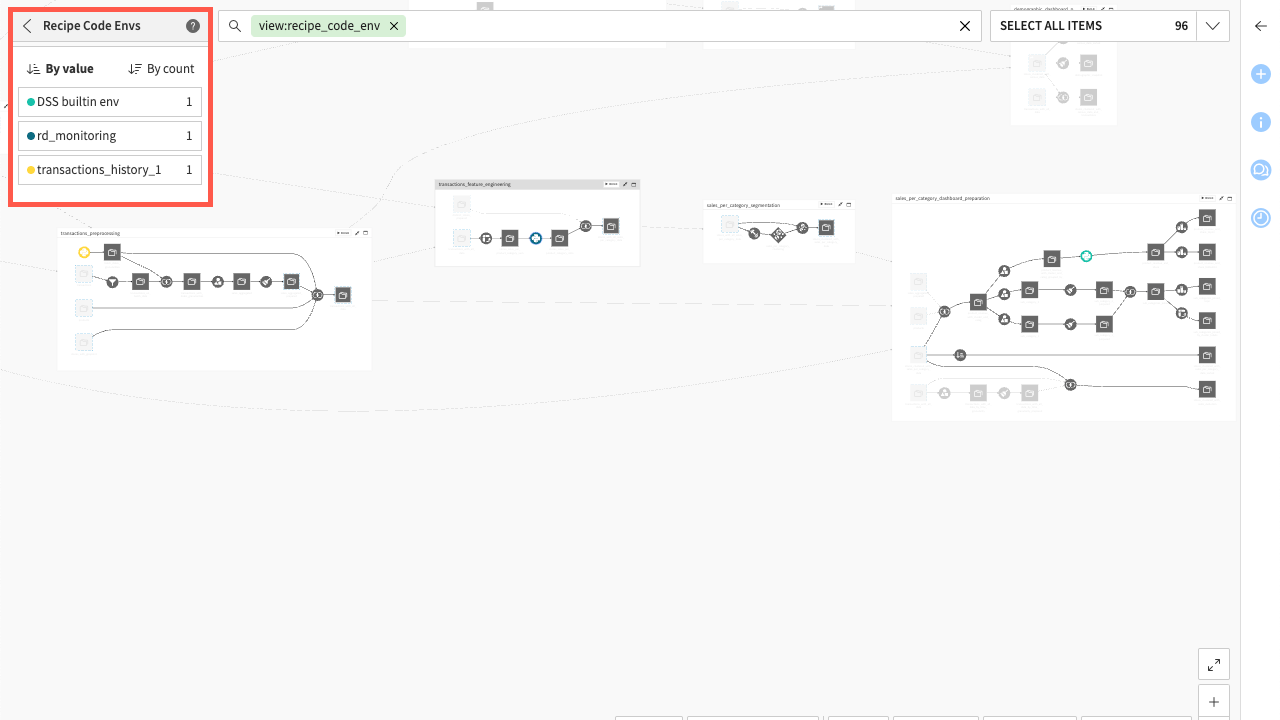
Recipe code environments#
Next is the Recipe Code Envs view, which shows the code environments used in code recipes.
By knowing the required code environments for running recipes in the project, you can ensure that an export of the project is uploaded to a Dataiku instance which has equivalent code environments.
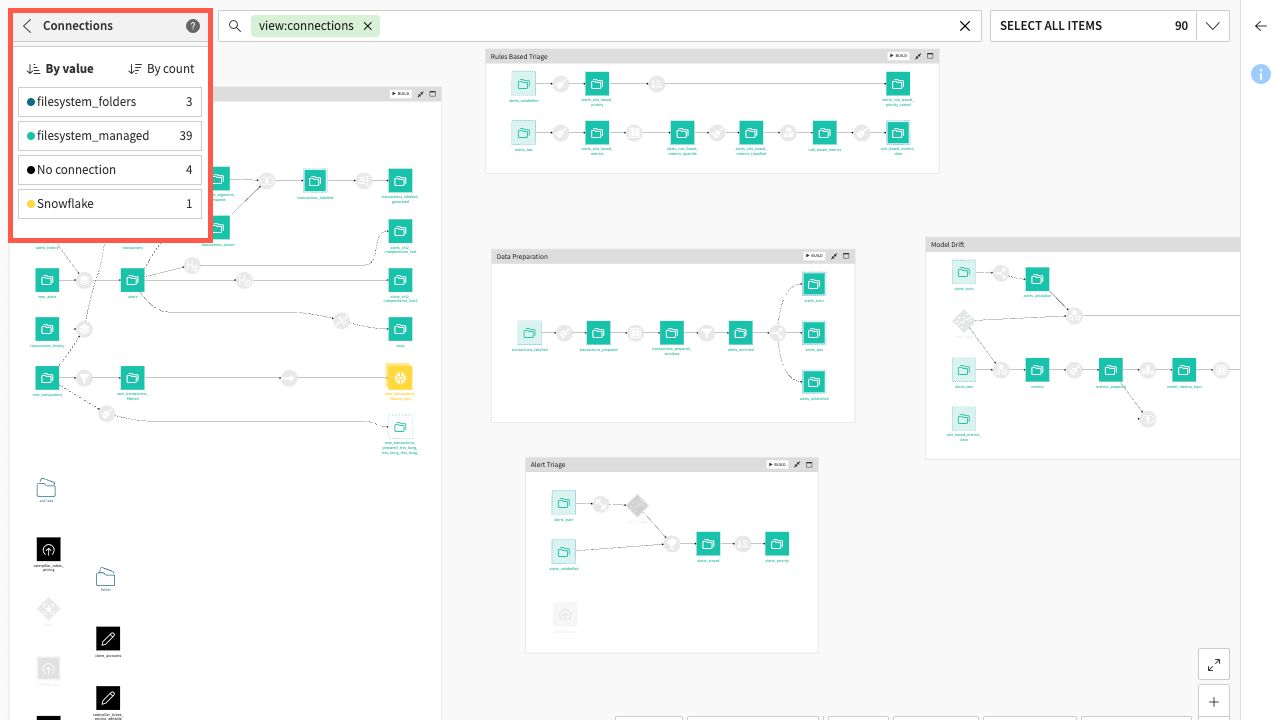
Connections#
The Connections option shows the connections of datasets in your Flow.
As seen with the previous views, checkboxes allow you to filter the view-—-in this case, by connection names, to see the particular datasets on those connections.
Together with the Recipe Engines view, you can get an idea of how to optimize the computation engines used in the Flow.
Activity#
Moving on to the Activity category, the options here allow you to view the Flow with details of its activity history. This category contains several subcategories to refine the view, such as:
Subcategory |
Description |
|---|---|
Creation |
Shows when each object was first created and customize the view based on specific timelines. By displaying the view by user, you can see which user created each object in the Flow. |
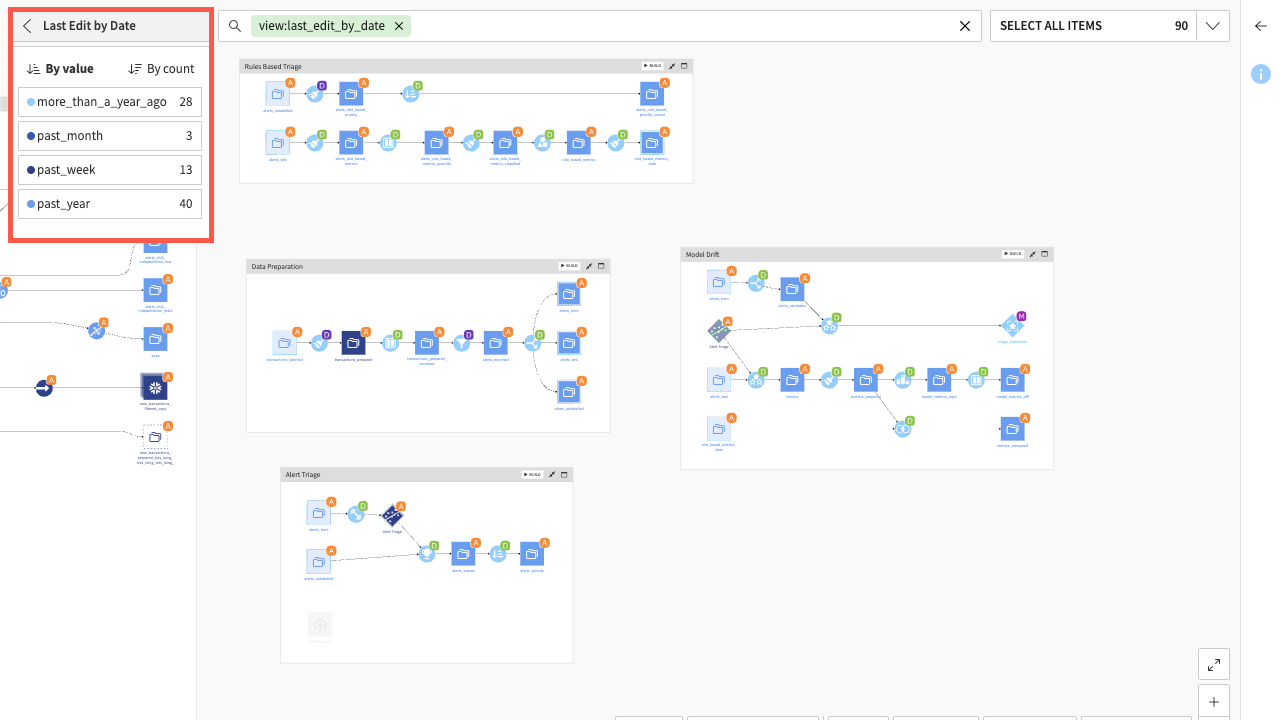
Last Edit |
Provides useful information when working in a team. If a team member changes the settings of a recipe, they won’t be visible from the Flow. But, using the Last modification view, you can check for modification activities whenever you first open up your project. As with the Creation view, you can customize your view by dates or by users. |
Last Build |
Is useful for checking if each dataset is up-to-date. For instance, seeing that a recipe’s input dataset was built in the past 24 hours, but its output dataset was built in the past month can alert you to an outdated dataset in the Flow. |
Recent Modifications |
Shows you how many modifications have been made since a reference date. The number on the left side indicates how many times the objects were modified since the reference date, while the number on the right side indicates the number of objects to which the modifications were applied. |
Scenarios |
Is helpful for identifying objects in the Flow that are used in scenarios. By hovering over an object, Dataiku displays the scenario steps where the object is used. |
Data#
Moving to the Data category, we see several options for viewing information about datasets in the Flow, such as:
Subcategory |
Description |
|---|---|
Partitions Count |
Provides a view of how many partitions are built for the partitioned datasets. Here, the number on the left side indicates the number of partitions, and the number on the right side indicates the number of corresponding partitioned datasets. |
Partitioning Schemes |
Identifies datasets that are partitioned and their partitioning schemes. To learn more about partitions, see Working with partitions. |
File Size |
Shows which parts of the data pipeline would be slower to build, and use this information to refactor your Flow accordingly. |
File Format |
Highlights the format used to store datasets in the Flow. Using this view and the Connections view can help you know where to optimize the Flow. For example, by ensuring that datasets using an HDFS connection are stored in parquet format, rather than CSV format, where appropriate. |
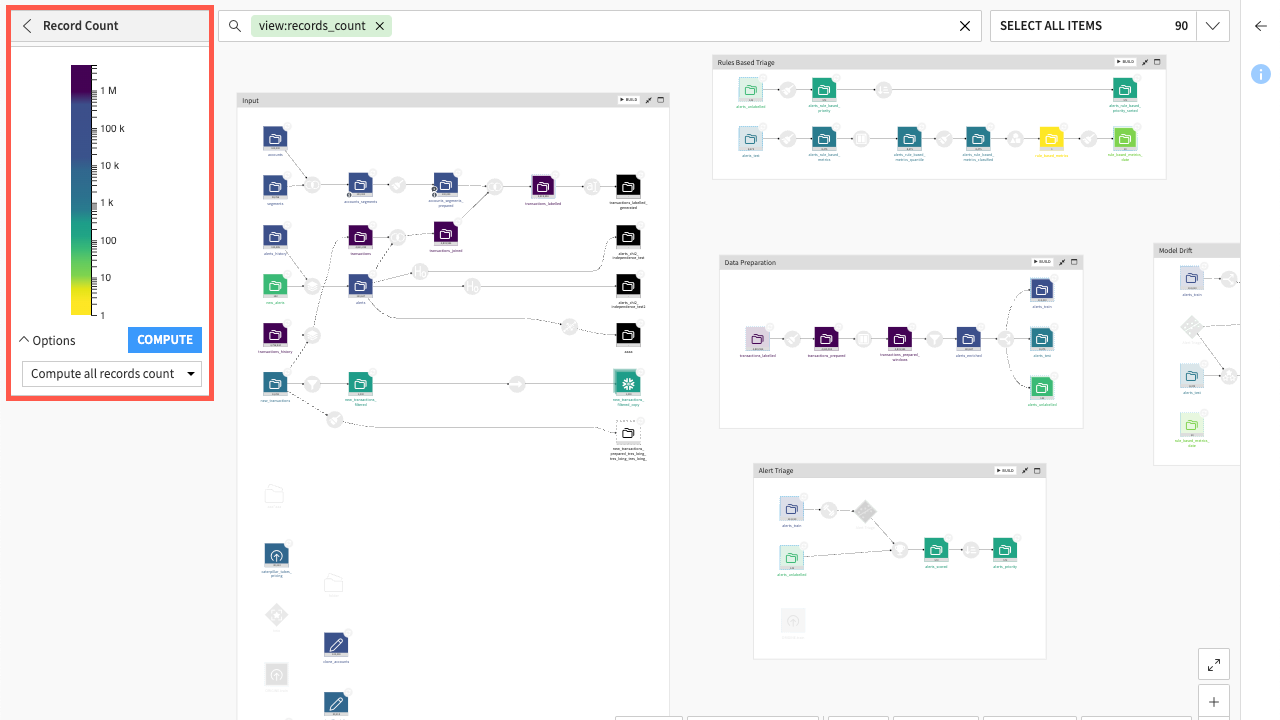
Record Count |
Displays a heatmap of the range of record counts for datasets in the Flow. Where there is a smaller number of counts, a categorical display is shown. By hovering over a dataset, you can see its actual number of rows along with information, such as the last time it was computed. |
Data Quality |
Identify datasets by their status according to data quality rules you have set up. Monitored datasets are colored either green (OK), yellow (Warning), red (Error), black (Empty) or gray (Not Computed). |
Note
You also have the option to compute the all records count or the missing records count in the options.
Search and filters#
While views allow you to identify objects with respect to certain categories, the search and filters focus on quickly accessing specific objects you would seek for. To do so, you have access to a search bar beside the views menu. Keywords are mainly inherited from the views such as tags, connections, etc. But, you can also directly use their names or other properties.
As you enter keywords, the search will refine to give you the most relevant result, which is often the exact object. In large Flows, it’s sometimes difficult to identify and locate a single object. That’s why, once the search is complete and the object identified, you can quickly find it again thanks to the Selector, which will focus on and select it.
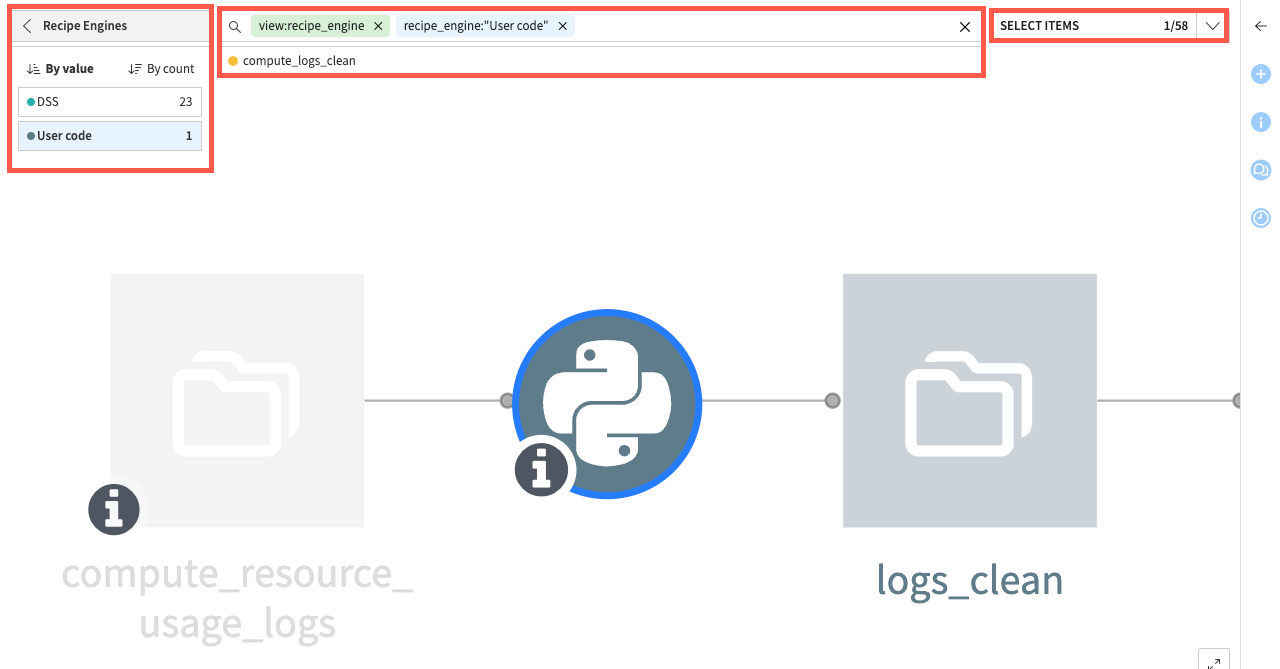
Let’s say you want to find a specific recipe made by the code of a user but you can’t remember the zone where it’s placed nor the name. You select the view Recipe Engines and apply the User code option.
Note
As soon as you select options in the views, you can notice that they’re reported to the filters in the search bar allowing a fluid and dynamic search.
Because it’s the only one, you can use the selector clicking Select Items to have a focus on it. The object has been found in 3 clicks in a massive Flow.
Next steps#
Congrats! Now you’ve seen some of the available Flow views alongside search, and filter and can get started with using the information they provide to organize your work and optimize your Flow.
Learn more about this in the Advanced Designer learning path.
You can also learn more about the Flow in the reference documentation.