
Tutorial | Flow zones#
Get started#
Using Flow zones to sub-divide a complex Flow into more manageable pieces allows you to view it at a higher level of abstraction and quickly grasp its overall purpose.
Objectives#
In this tutorial, you will:
Move Flow items into new Flow zones.
Manage the display of Flow zones.
Delete Flow zones and undo that change.
Prerequisites#
To reproduce the steps in this tutorial, you’ll need:
Dataiku 12.6 or later.
Basic knowledge of Dataiku (Core Designer level or equivalent).
Create the project#
From the Dataiku Design homepage, click + New Project.
Select Learning projects.
Search for and select Flow Zones.
If needed, change the folder into which the project will be installed, and click Create.
From the project homepage, click Go to Flow (or type
g+f).
Note
You can also download the starter project from this website and import it as a ZIP file.
You’ll next want to build the Flow.
Click Flow Actions at the bottom right of the Flow.
Click Build all.
Keep the default settings and click Build.
Use case summary#
The project has three data sources:
Dataset |
Description |
|---|---|
tx |
Each row is a unique credit card transaction with information such as the card that was used and the merchant where the transaction was made. It also indicates whether the transaction has either been:
|
merchants |
Each row is a unique merchant with information such as the merchant’s location and category. |
cards |
Each row is a unique credit card ID with information such as the card’s activation month or the cardholder’s FICO score (a common measure of creditworthiness in the US). |
Create and move items into Flow zones#
Looking at the Flow, you can abstract its purpose to two steps: data ingestion and data preparation. We can use this grouping to build our Flow zones.
Move items to a new zone#
Select these datasets:
tx_prepared
tx_distinct
tx_pivot
tx_topn
tx_windows
In the Actions tab, under Flow Zones, select Move (or right-click on the selection and select Move to a flow zone).
Name the zone
Data preparationand review which recipes will be moved as well.Click Confirm.
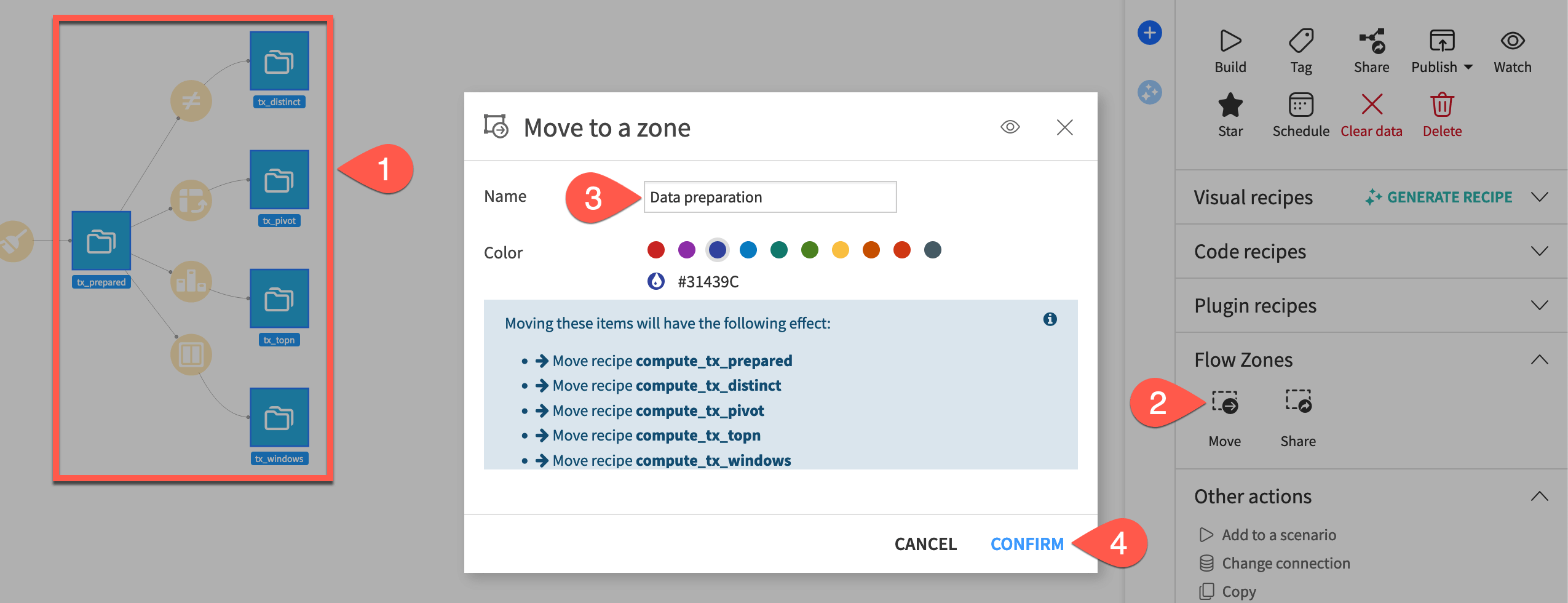
Tip
Here, we moved items to a new Flow zone. You also have the option in this step to move items to existing Flow zones if present.
Rename the default zone#
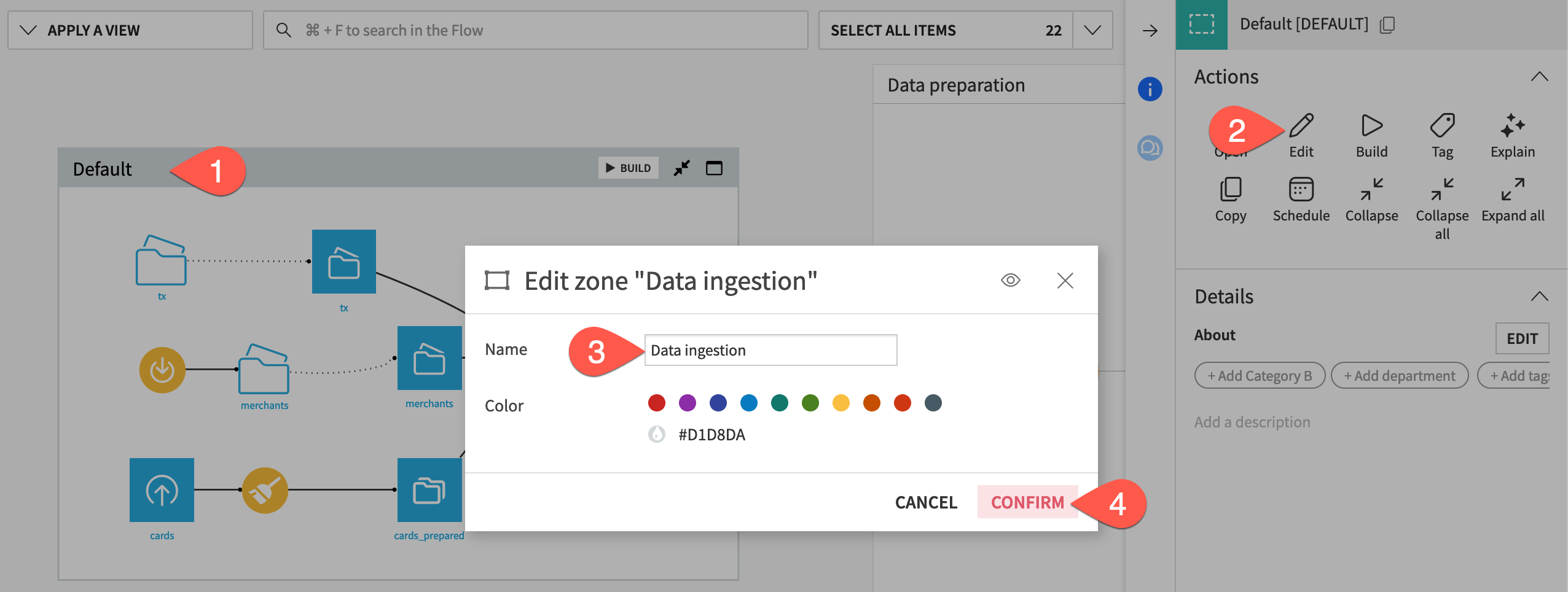
Select the Default Flow zone.
In the Actions panel, click Edit.
Rename the Flow zone
Data ingestion.Click Confirm.
Open the Flow zone view#
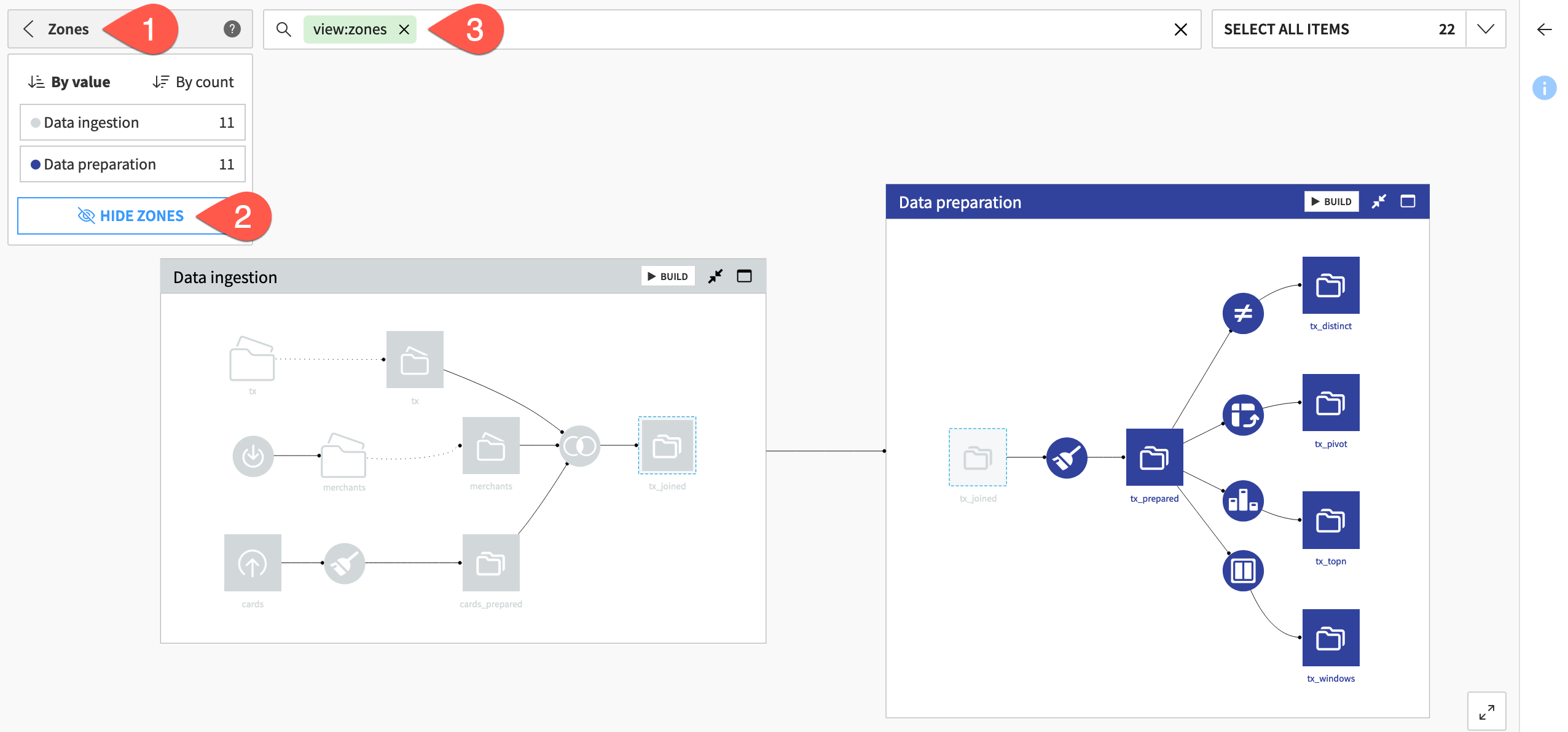
Let’s look at the Flow zone view.
From the Flow View menu, select Zones. In this view, Flow items are colored according to their Flow zone.
Click on Hide Zones. Items are still color-coded according to their Flow zone, but the zone boundaries no longer appear.
Exit the Flow zone view to prepare for next steps.
Expand or Collapse a Flow zone#
Let’s hide the content of the Data ingestion Flow zone. This could be useful if you were only focused on making changes to the Data preparation items.
Right-click on the Data ingestion Flow zone, then select Collapse. You can also click the collapse (
 ) icon on the Flow zone to do this.
) icon on the Flow zone to do this.Click the expand (
 ) icon to see the Flow details again.
) icon to see the Flow details again.
Note
If collapsing a zone isn’t enough, you can:
Double-click on the Data preparation Flow zone to only see this zone on the screen.
Implement Flow folding as described in the reference documentation.
Delete a Flow zone#
What happens to Flow items when you delete a Flow zone? Let’s delete the Data preparation zone and see.
Select the Data preparation Flow zone.
In the Actions panel, click Delete.
Click Confirm.
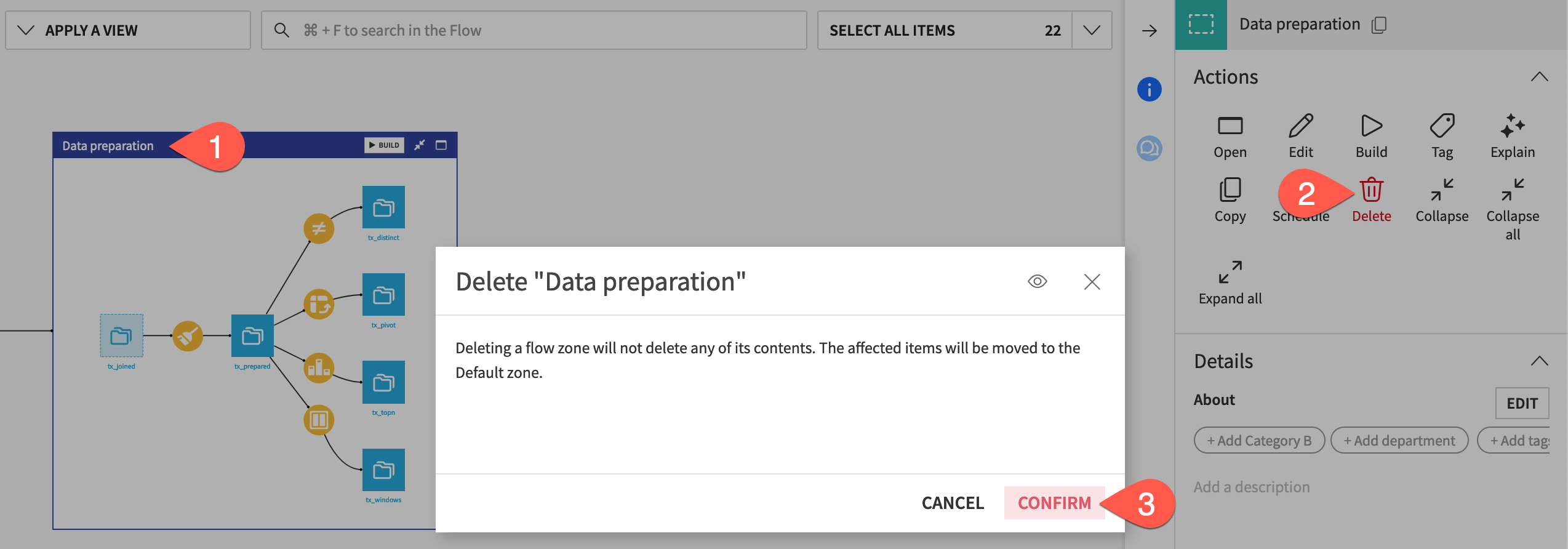
You’ll see that both Flow zones disappear. This is because items in the deleted Flow zone move to the Default Flow zone (which was renamed Data ingestion). However, you can’t only have one Flow zone in the Flow. Thus, both zones were removed.
Note
If we had tried to delete the Data ingestion Flow zone, we would have seen that it wasn’t possible. This is because the Default Flow zone can’t be deleted.
Undo a deletion#
Imagine you had deleted the Flow zones by accident. Do you know how to undo this change? Let’s practice.
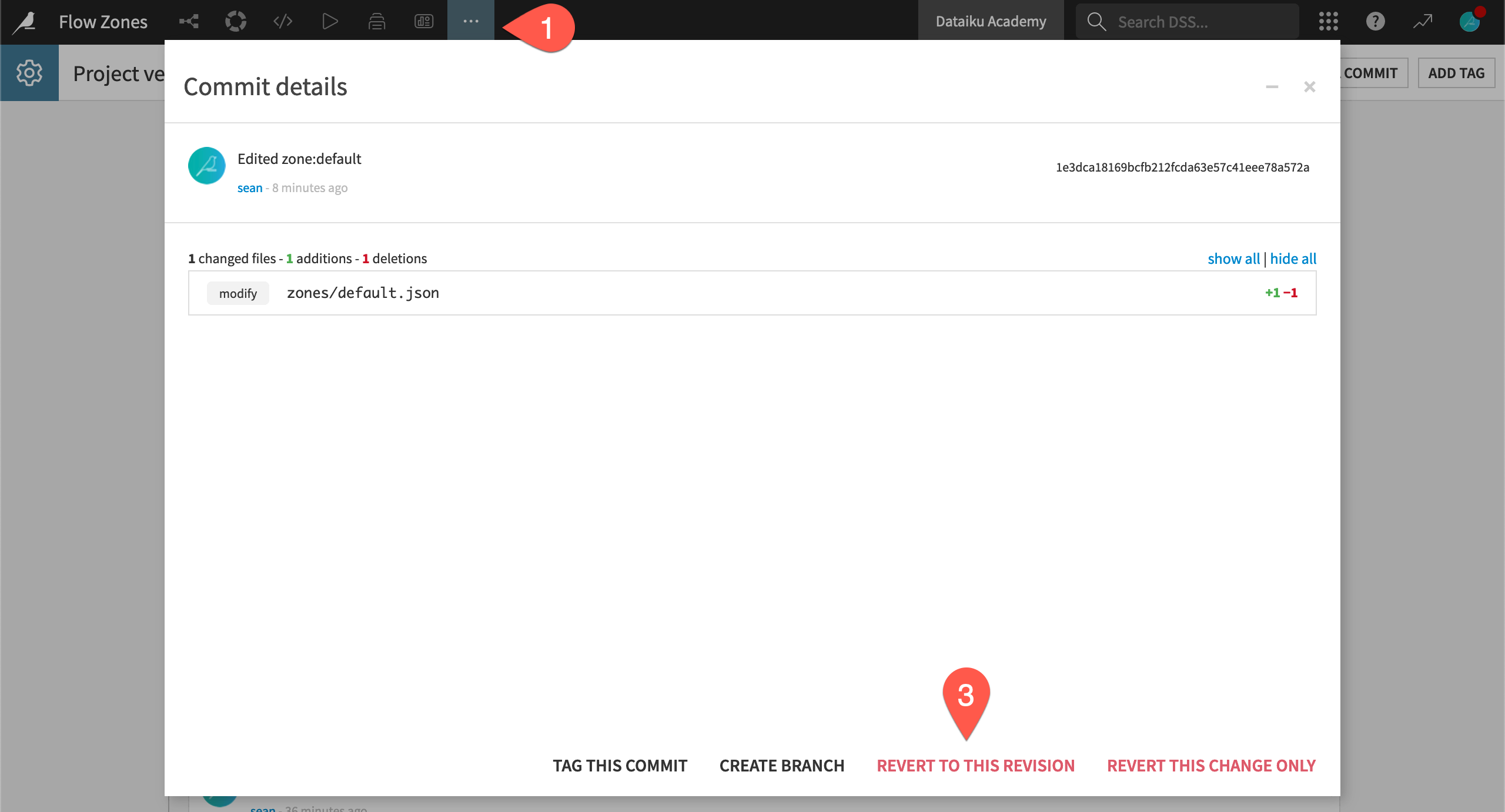
From the More Options (
 ) menu in the top navigation bar, select Version Control.
) menu in the top navigation bar, select Version Control.Click on the change you made before deleting the Flow zone. (Assuming you made no other changes, this will be the second item in the list from the top.)
Select Revert To This Revision and Confirm to undo any changes you made after this commit.
See also
To learn more about version control in Dataiku, visit our page on Project Version Control.
Next steps#
Now you know how to organize your Flow into multiple Flow zones.
To learn about how to use Flow zones to your advantage when building datasets, check out Tutorial | Build modes!
See also
For more information, see the Working with Flow zones article in the Developer Guide.