
Add an enrichment to a prediction endpoint#
You’ve successfully published an API service from the Design node to the API Deployer and then to a deployment infrastructure (an API node). This allowed you to receive a response from a query to a live prediction endpoint.
Often though, you may be missing information required for a model to score an incoming request. In such a situation, you’ll need to add an API query enrichment to the prediction endpoint within the existing API service on the Design node. Then, you’ll re-deploy a new version of the API service.
Add a query enrichment#
The project creators trained the prediction model in the Flow on six features from the training dataset. You can confirm this by opening the active version of the model, and navigating to the Features panel in the Model Information section.
Ideally, an incoming transaction to the API endpoint would have values for all six features. However, suppose at the time a transaction occurs, a merchant point of sale system sends values for only a subset of these features:
signature_provided
merchant_subsector_description
purchase_amount
merchant_state
You first need to retrieve the missing values for the features card_fico_score and card_age from the internal database, and then use these values to enrich the API queries.
Using the cardholder_info dataset, you’ll use the card_id value of each real-time transaction to look up the corresponding values for fico_score and age. You’ll then pass the complete feature set to the prediction model for scoring.
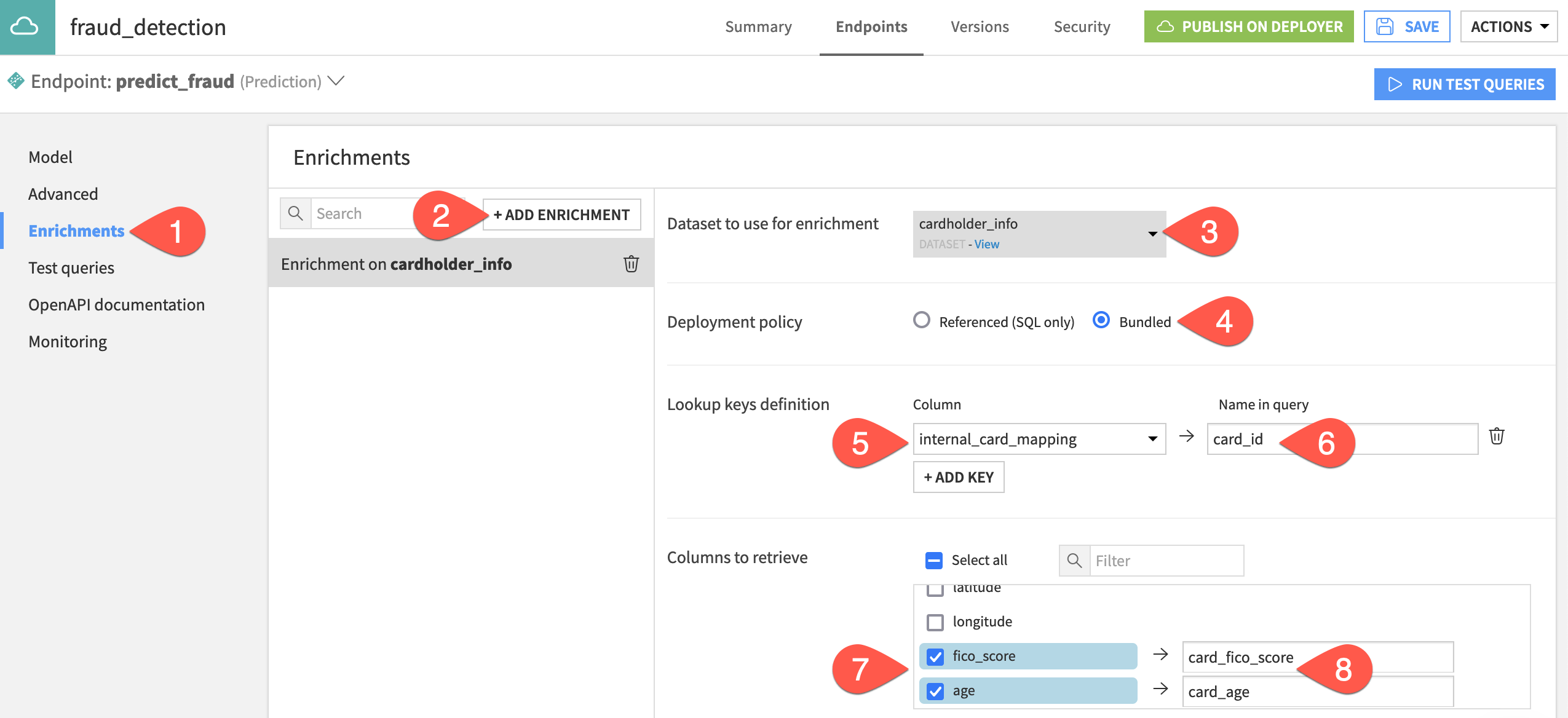
From the API Designer page in the Design node project, open the fraud_detection API service, and navigate to the Enrichments panel.
Click + Add Enrichment.
Select cardholder_info as the dataset to use for enrichment.
Leave the default Bundled deployment policy.
See also
If you want to use a referenced deployment policy, you’ll need an SQL connection. Follow resources on remapping connections.
Next to Lookup keys definition, click + Add Key, and select the internal_card_mapping column.
Provide
card_idas the name in the query for the lookup key.In Columns to retrieve, specify the two missing features to retrieve from the dataset: fico_score and age.
Remap these columns to the names
card_fico_scoreandcard_age.
Change one more setting before testing the enrichment.
Navigate to the Advanced panel of the API endpoint.
Check the box Return post-enrichment to deliver a more verbose response to each API query.
Test the query enrichment#
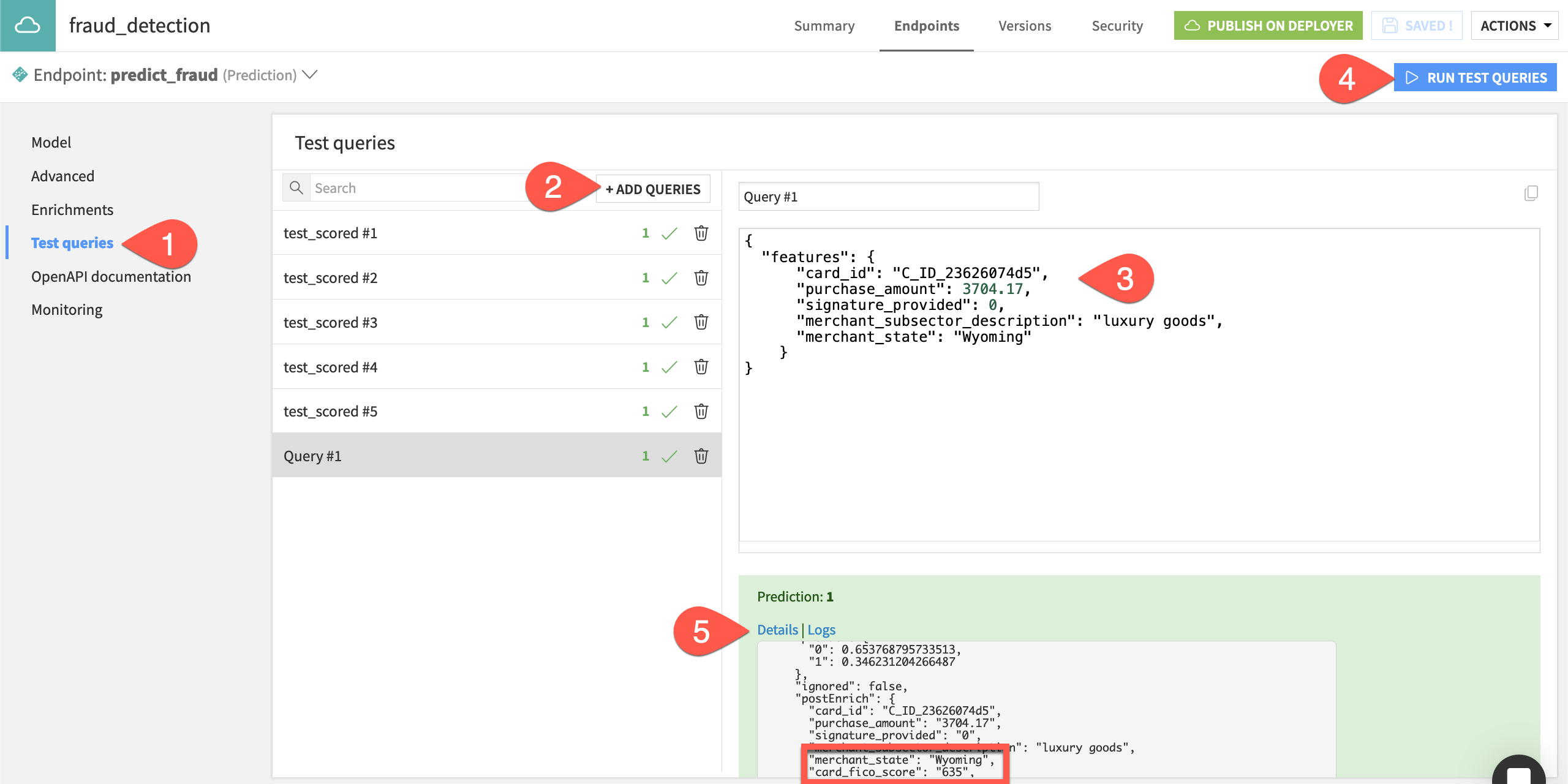
To test the enrichment, you’ll use a query that includes only four of the six features used to train the prediction model.
Navigate to the Test queries panel of the API endpoint.
Click + Add Queries, and then Add
1new empty query.For the new empty query, paste the following JSON object in the query window.
{ "features": { "card_id": "C_ID_23626074d5", "purchase_amount": 3704.17, "signature_provided": 0, "merchant_subsector_description": "luxury goods", "merchant_state": "Wyoming" } }
Click Run Test Queries.
Click Details in the API response for the new test query, and observe the values for card_fico_score and card_age despite them not being present in the query.
To summarize, the enrichment uses the card_id to retrieve the missing features (card_fico_score and card_age) so that the model has all features needed to generate a prediction.
Tip
You can also test the enrichment by modifying the JSON object for any of the previous test queries. To do this, delete all features except for the four used in the JSON object above. When you run the test queries, you’ll notice that the endpoint returns the same prediction as before for the modified test query — even without the missing features.
Redeploy the API service#
Now that you’ve added an enrichment to the prediction endpoint on the Design node, you need to redeploy a new version of the API service in the production environment.
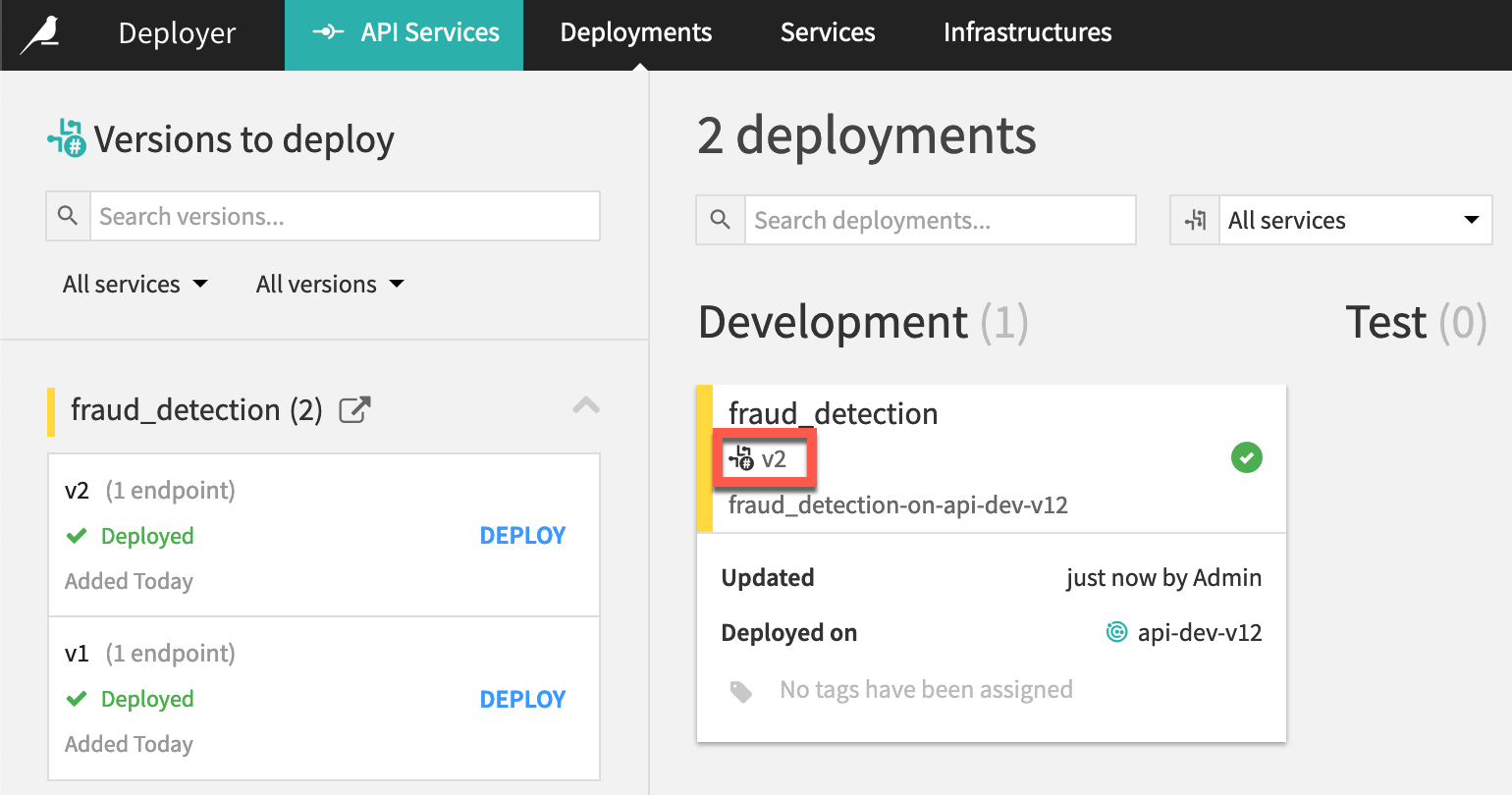
From the fraud_detection API service in the Design node project, click Publish on Deployer.
Accept the default version ID, and click Publish.
Open the API service on the API Deployer, and click Deploy next to the new version.
In the Deploy version dialog, click OK to update the version used in the service.
Click OK again to confirm which deployment you want to edit.
Now on the Settings tab of the deployment, click the Update button.
If deploying to a static infrastructure, select the default Light Update.
Otherwise, navigate to the Status tab of the deployment to confirm the latest version is active.
Tip
You can track changes to a deployment in the Last Updates tab. At this point, you’ll see one update for the initial deployment and another update for the redeployment.