
Concept | Embed recipes and Retrieval Augmented Generation (RAG)#
While large language models (LLMs) are powerful tools, they often lack specific internal knowledge from organizations. The Embed recipes (Embed dataset and Embed documents) in Dataiku use the Retrieval Augmented Generation (RAG) approach to help you fetch relevant pieces of text from a knowledge bank and enrich the user prompts with them. This improves the precision and relevance of answers returned by the LLMs.
A key benefit of the RAG approach is that you can improve precision without fine-tuning a model, which is time-consuming and expensive. All you have to do is add your internal knowledge to a knowledge bank and feed the LLM with it.
RAG pipeline for question-answering using an augmented LLM#
Let’s see how the RAG approach works.
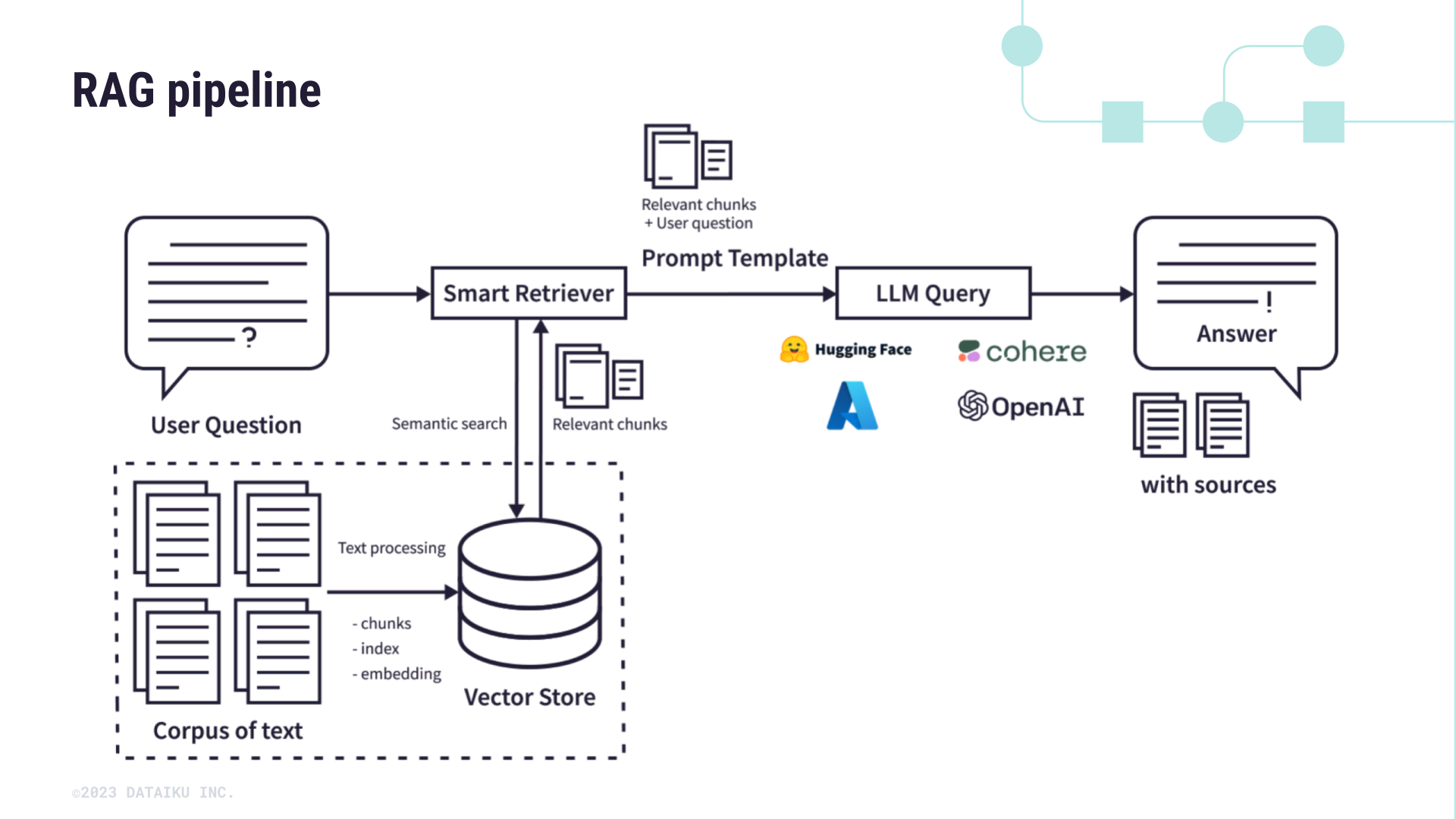
As you can see in the diagram above, using an augmented LLM includes several steps:
Gather a corpus of documents that will serve as the bespoke information you’ll augment an LLM’s base knowledge with.
For instance, these might be internal policy or financial documents, technical documentation, or research papers about a certain topic.
The Embed recipes use vector stores such as FAISS, Pinecone, or ChromaDB to break your textual data into smaller chunks and then vectorize it (that is, encode the semantic information into a numerical representation). The output of the vectorization is stored in a knowledge bank that’s optimized for high-dimensional semantic search.
Note
The numeric vectors are commonly known as text embeddings, hence the name of the recipes.
When a user asks a question, the smart retriever uses the vector store to augment the provided question with relevant information from the vector store.
The augmented prompt is used to query the large language model to provide more precise answers along with their sources.
Embed recipes#
Dataiku offers two embed recipes:
Embed documents (from Dataiku 13.4 and later)
Embed dataset (from Dataiku 12.3 and later)
In both cases, these recipes handle text embedding (that is, text vectorization) in the RAG approach.
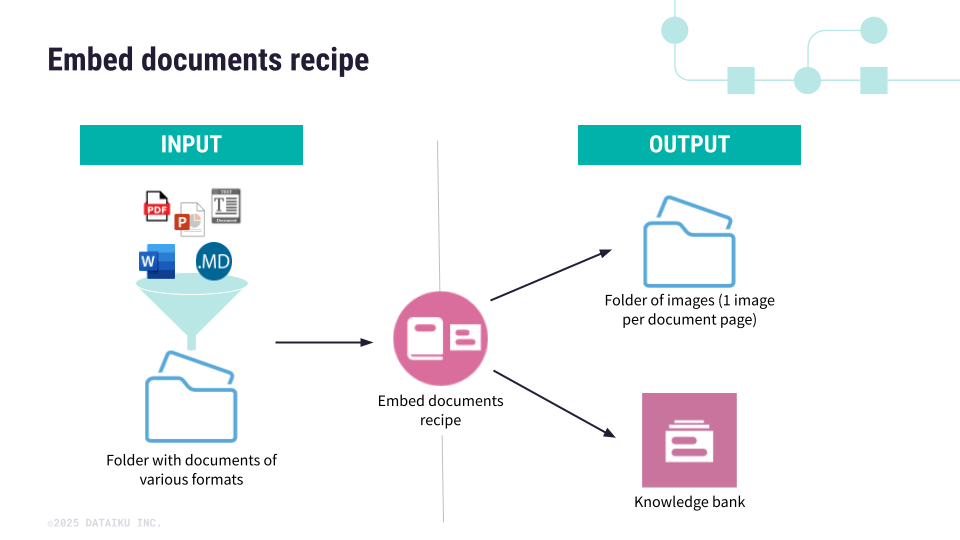
The key difference is that the Embed documents recipe can extract content from documents of different formats (.pdf, .docx, .pptx, .txt and .md) and thus generate a multimodal knowledge bank.
Unlike a standard knowledge bank, which only submits text chunks to an LLM, a multimodal knowledge bank enhances retrieval by combining both the text chunks produced during embedding and the associated images (for example, tables, graphs, and diagrams) extracted from the documents. This ensures that all relevant information can be retrieved in a multimodal knowledge bank.
Embed documents recipe#
Note
The Embed documents recipe is available with Dataiku 13.4 and later versions.
How the recipe works#
The Embed documents recipe:
Takes as input a managed folder of documents.
Breaks the documents into pages or page ranges.
Extracts the content using either:
Simple text extraction for .txt and .md documents. In this case, the recipe is able to extract directly the text without involving any LLM. By default, it tries to split the text by sections.
VLM (Vision Language Model) extraction for .pdf, .docx and .pptx documents. With this extraction strategy, the recipe uses a vision language model that you select (such as GPT-4) to extract content – even with complex elements such as tables, charts or images – and convert it into images. By default, each page is converted into an image but you can choose the extraction unit (page by page, page range, full document). This extraction type enables handling tables, charts and images, which can’t be processed by basic text extraction methods.
Summarizes the content to be sure that the extracted content is concise and fits within the embedding model’s size limits.
Creates a multimodal knowledge bank that embeds the summaries while linking back to the original document pages for accurate retrieval.
Stores into a managed folder the images taken from the documents when you apply a VLM extraction.
The recipe returns two outputs:
A knowledge bank.
A managed folder when using VLM extraction.
Settings page#
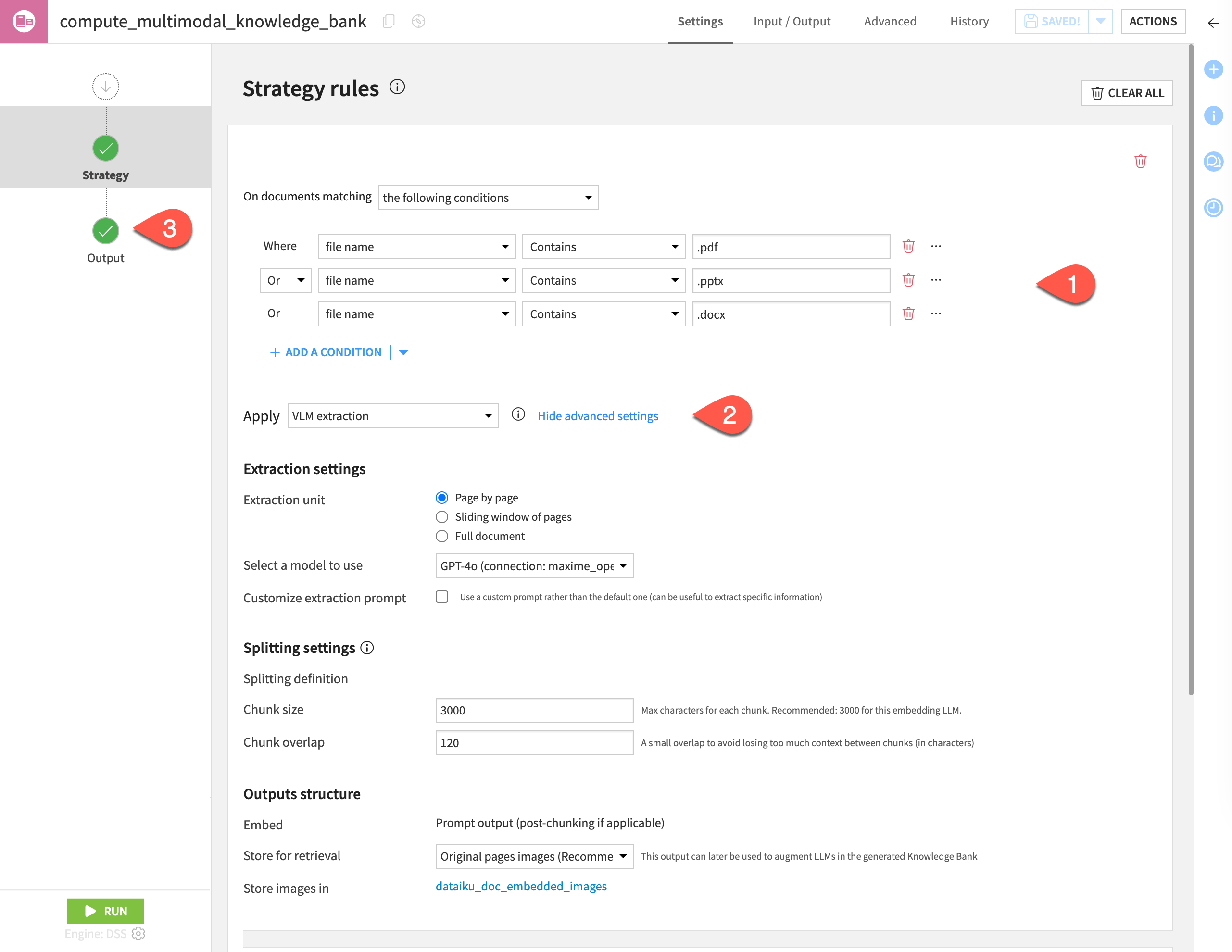
The recipe settings page is where you:
Define the strategy rules for the text extraction. By default, the recipe provides three rules:
Apply text extraction on .pdf, .pptx, .docx, .html, .txt and .md files.
Apply VLM extraction on .pdf, .doc, .docx, .pptx, .odp, .odt, .jpg, .jpeg, .png, .txt, .md files.
Apply custom rules to configure some advanced settings, such as:
The extraction unit
The splitting method
The output structure
Configure the recipe outputs, that is, the knowledge banks, the folder that stores the images when using the VLM extraction, and the update strategy.
Embed dataset recipe#
Note
The Embed dataset recipe is available with Dataiku 12.3 and later versions.
Unlike the Embed documents recipe, the Embed dataset recipe doesn’t perform text extraction. It’s only used for embedding. As a consequence, when you use it, if your textual data is in PDF, HTML, or another document format, you must first apply a content extraction recipe to convert the files into a tabular dataset, where each document’s extracted text is captured in its own row.
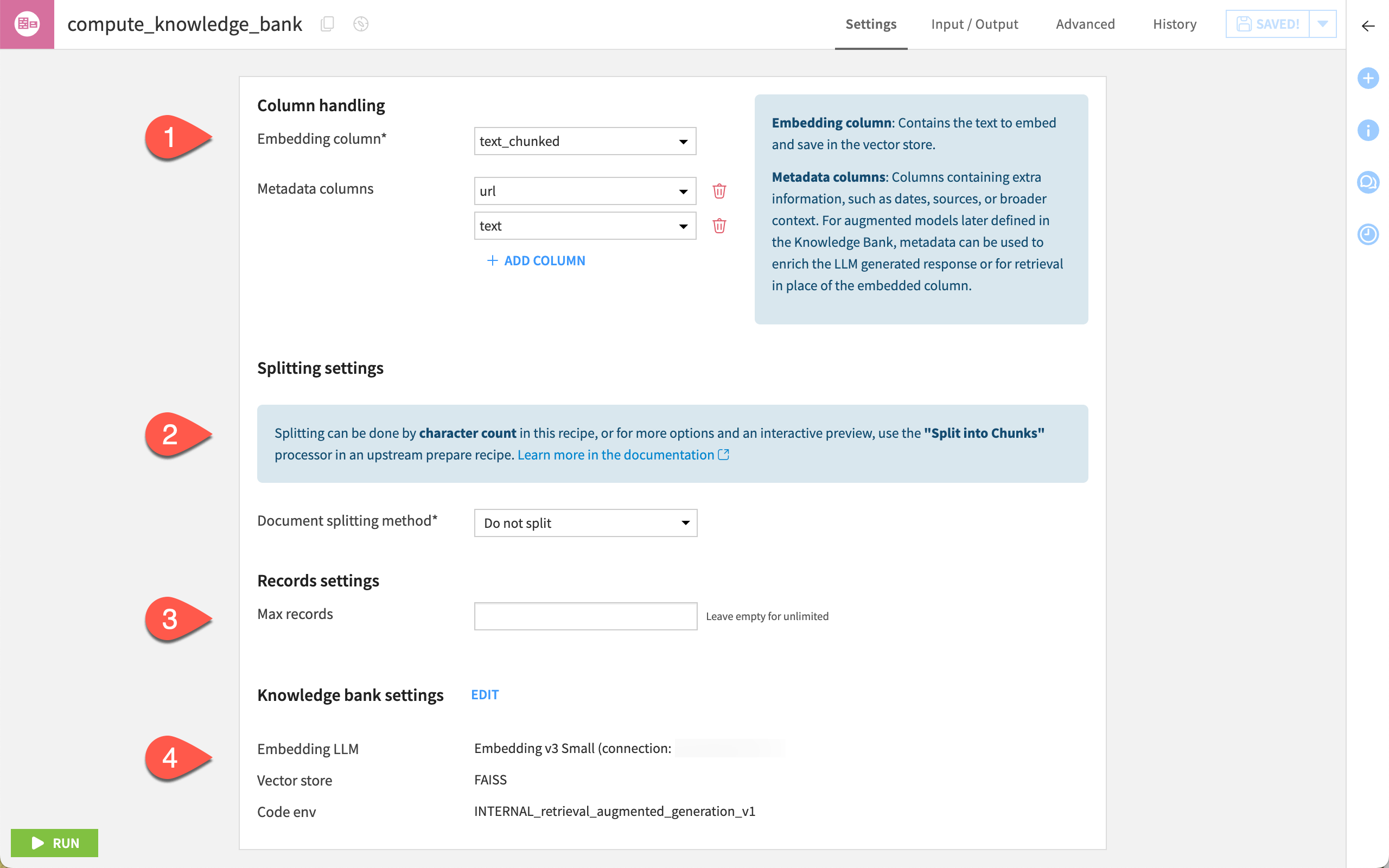
The recipe settings page is where you:
Configure the dataset columns to be used, including:
The embedding column, which is the column from the input dataset that contains the text to embed (that is, to convert from textual data into numerical vectors).
The metadata columns used to get some additional information to enrich the retrieval augmented LLM or for the retrieval stage in place of the embedding column.
Configure the splitting methods and chunks of the input data.
Define a maximum number of rows to process.
Set your knowledge bank by selecting the LLM and vector store to use for text embedding.
Knowledge bank settings#
A knowledge bank is the output of an Embed recipe. This is where your input textual data has been converted into numerical vectors to augment the LLM you want to use.
On the Flow, it’s represented as a pink square object.
The table below describes the different tabs used to configure the knowledge bank.
Tab |
Description |
|---|---|
Usage |
This tab is meant to configure the LLMs that will be augmented with the content of the knowledge bank. It allows you to:
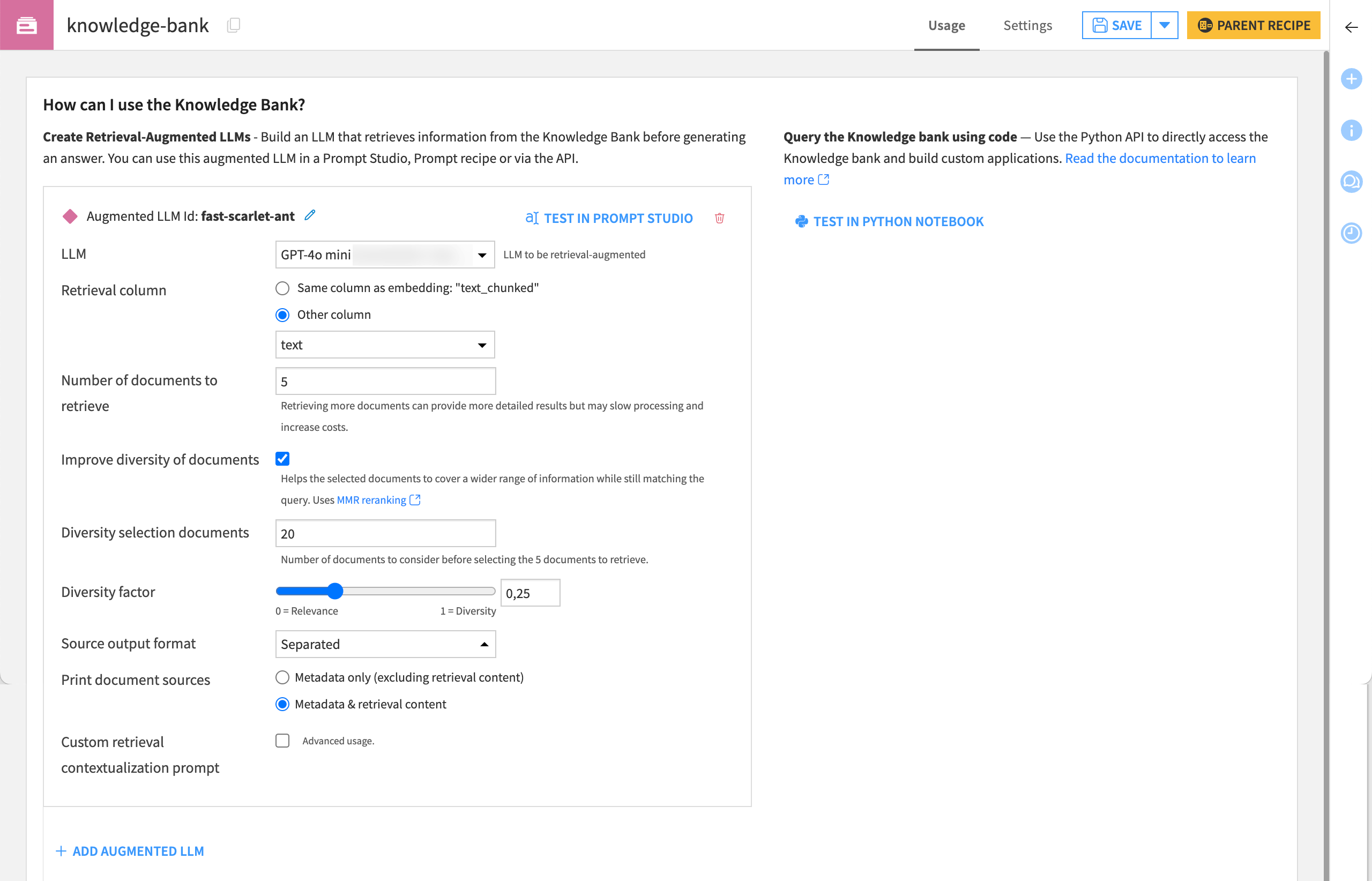
|
Search |
This tab offers a chat interface where you can query the knowledge bank. 
|
Settings > Core settings |
This tab lets you edit the embedding method and indicate the vector store used to store the vector representation of the textual data. By default, the embed recipe uses the ChromaDB vector store. 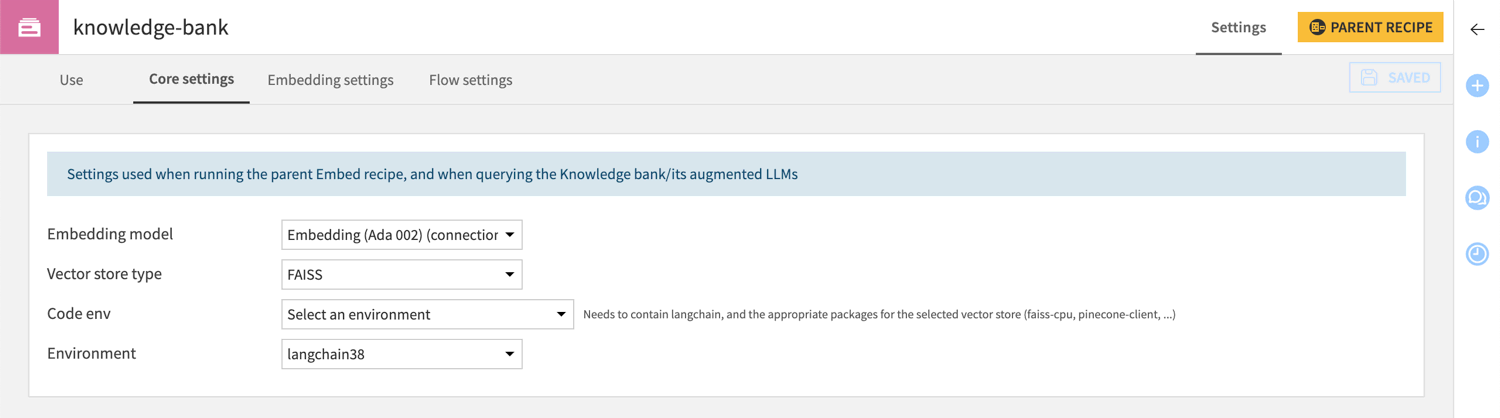
|
Settings > Embedding settings |
This tab is a snapshot of the parent recipe settings upon the last run. 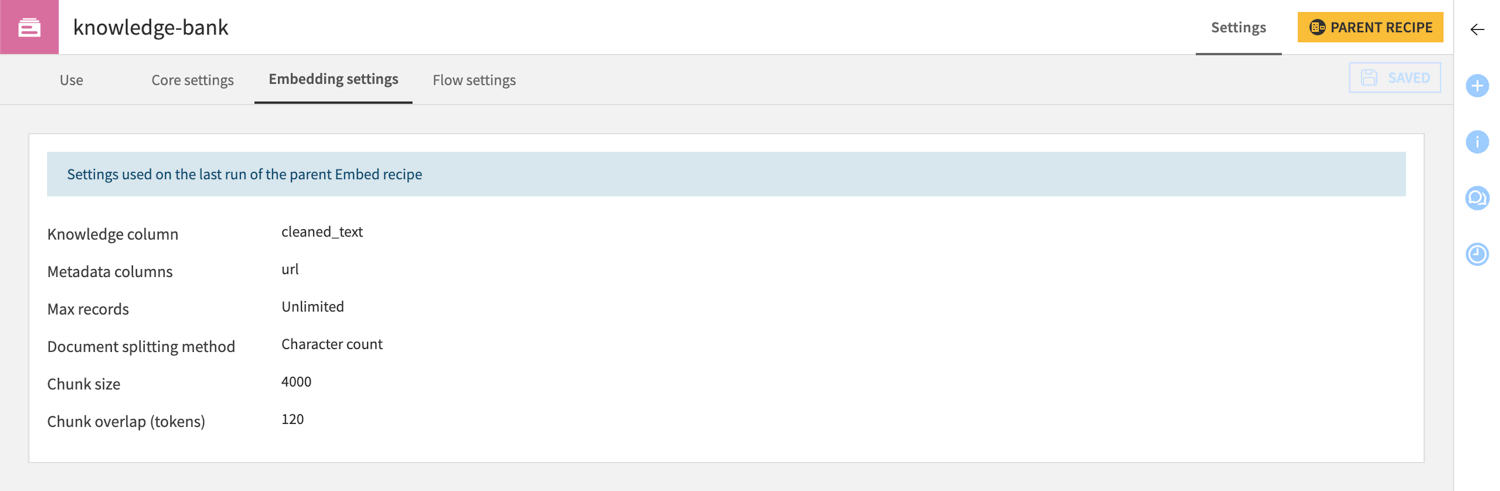
|
Settings > Flow settings |
This tab allows you to define whether you want to automatically recompute the knowledge bank when building a downstream dataset in the Flow. 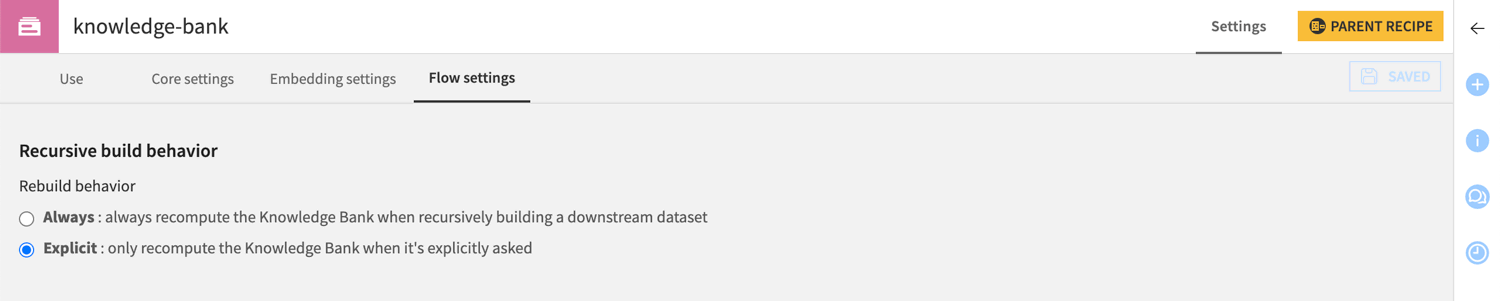
|
Tests in the Prompt Studio#
Once you’ve augmented an LLM with the content of your knowledge bank, this LLM becomes available in the Prompt Studios and Prompt recipe under a section named Retrieval Augmented.
Note
Retrieval-augmented LLMs are only available within the scope of the project. They inherit properties from the underlying LLM connection (caching, filters, permissions, etc.).
Using the Prompt Studio, you can test your augmented model with various prompts and evaluate the responses it generates.
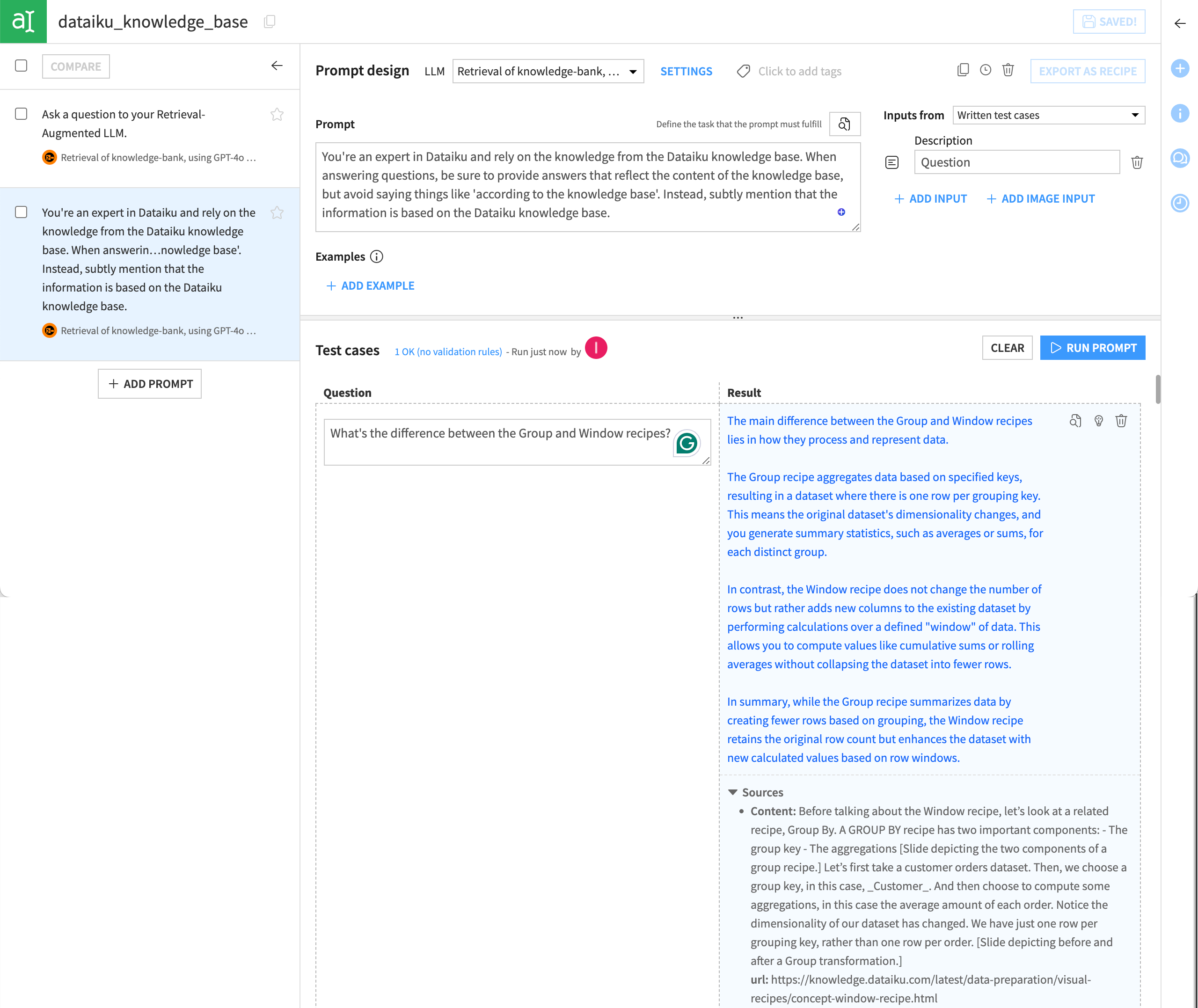
Note that the LLM provides its sources at the bottom of the response. This is a key capability and a primary benefit of the RAG approach.
As you may know, generic LLMs can sometimes offer answers that sound plausible but are, in fact, hallucinations — statements that seem true but aren’t backed up by real data. This is a major risk when accurate and credible information isn’t just a nice-to-have, but a must-have. That’s why prompt engineering and thorough testing are crucial to minimize hallucinations. With your knowledge bank documentation clearly displayed with each answer, the application delivers insights that your teams can verify and trust.
Next steps#
Continue learning about the Embed recipe and the RAG approach by working through:
Tutorial | Build a RAG system and turn it into a conversational agent (for a use case using the Embed documents recipe).
Tutorial | Retrieval Augmented Generation (RAG) with the Embed dataset recipe (for a use case using the Embed dataset recipe).