
Tutorial | Retrieval Augmented Generation (RAG) with the Embed dataset recipe#
Get started#
You may be interested in using the Retrieval Augmented Generation (RAG) to increase the relevance and accuracy of responses from large language models (LLMs).
If your internal knowledge is already in the form of structured datasets (or can be prepared into tabular data), you can use the Embed dataset recipe to achieve this goal.
Objectives#
In this tutorial, you will:
Use Dataiku’s visual tools to prepare a dataset for text vectorization.
Use the Embed dataset recipe to extract this dataset’s information into a knowledge bank.
Discover resources for going further after having created a knowledge bank.
Important
If you don’t already have your internal knowledge organized in a tabular dataset, you’ll want to follow Tutorial | Build a RAG system and turn it into a conversational agent to learn how to use the Embed documents recipe. Unlike the Embed dataset recipe, the Embed documents recipe can create a multimodal knowledge bank from a variety of unstructured file formats, such as PDFs, images, etc.
Prerequisites#
To complete this tutorial, you’ll need:
Dataiku 14.0 or later.
An Advanced Analytics Designer or Full Designer user profile.
An internal code environment for retrieval augmented generation set up by the instance administrator.
An LLM connection to a supported LLM provider, including access to an embedding LLM.
Tip
You don’t need previous experience with large language models (LLMs), though it would be useful to read the article Concept | Embed recipes and Retrieval Augmented Generation (RAG) before completing this tutorial.
Create the project#
From the Dataiku Design homepage, click + New Project.
Select Learning projects.
Search for and select RAG with the Embed Dataset Recipe.
If needed, change the folder into which the project will be installed, and click Create.
From the project homepage, click Go to Flow (or type
g+f).
Note
You can also download the starter project from this website and import it as a ZIP file.
Prepare the data for retrieval#
Note
You can perform all the steps in this section directly within the Embed dataset recipe. However, using the Split column into chunks processor in a Prepare recipe, as done below, provides additional options and an interactive preview for better control.
Start by taking a closer look at the initial data. The project’s starting dataset contains a sample of articles from the Dataiku Knowledge Base. You can use this knowledge to help Dataiku users find relevant answers to their questions.
For example, the first eight rows represent the concept-rag file. If you compare these chunks with the online article, you’ll notice that the text has been divided according to the document’s sections.
From the Flow, open the dataiku_knowledge_base_sample dataset.
Recognize how each file is split into multiple chunks stored in the text column.
In the Actions (
 ) tab, under Visual recipes, click Prepare.
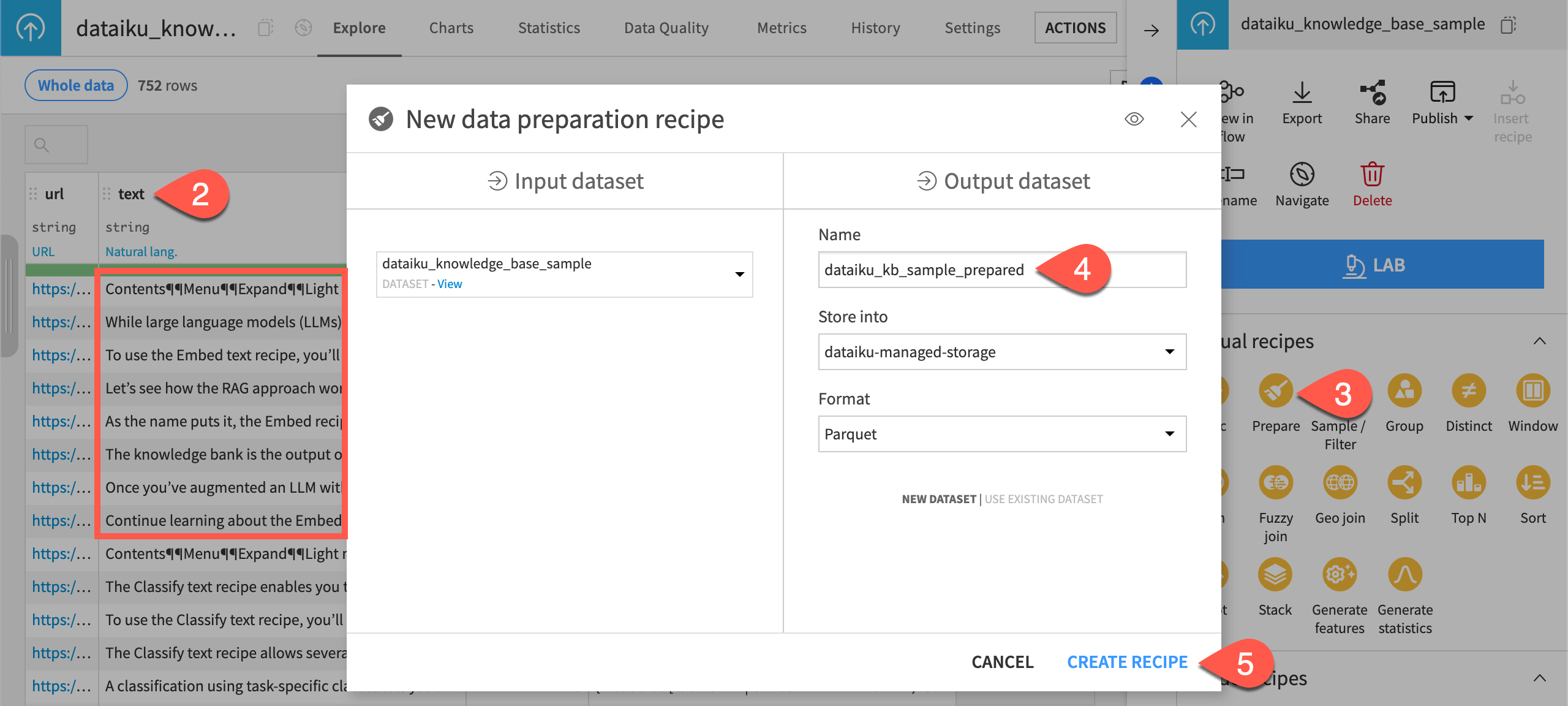
) tab, under Visual recipes, click Prepare.In the New data preparation recipe window, name the output dataset
dataiku_kb_sample_prepared.Click Create Recipe.
Although the text is already split, you can further split each chunk using the Split column into chunks processor in a Prepare recipe. This allows you to have more control over the splitting method or to reduce the chunk size. This can be particularly useful when dealing with documents that have minimal structure.
In the recipe’s Script, click + Add a New Step in the left panel.
In the processors library, search for
Split column into chunks, and select it.Set the processor as follows:
In the Column field, enter
text, the name of the column that stores the text to chunk.In the Chunk size field, enter
1500, which means each chunk should include 1500 characters.In the Chunk ID column field, enter
children_chunk_id.
Click Run to build the output dataset.
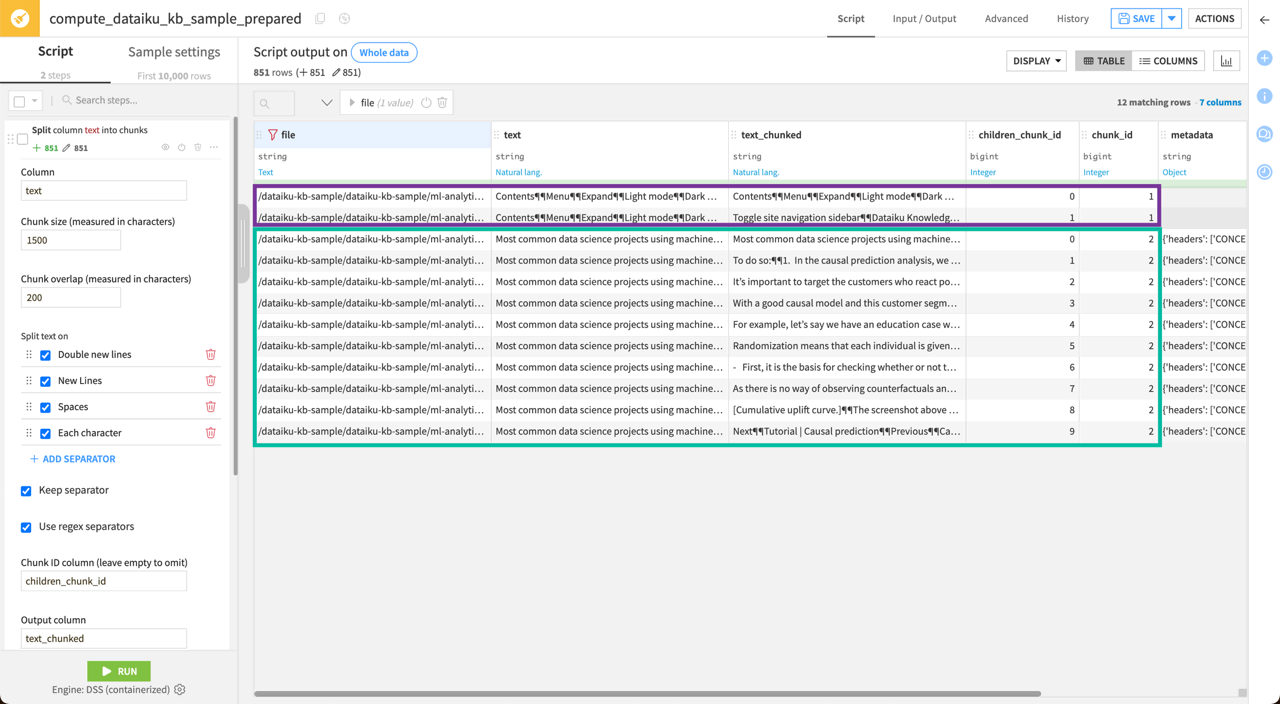
This step creates a text_chunked column with the new splits. For instance, if you filter the url column on concept-causal-prediction to focus on this file, you will see that:
The first “parent” chunk is now divided into two “child” chunks (in purple below).
The second “parent” chunk is divided into ten “child” chunks (in green below).
Look closer at the second parent chunk. The illustration below shows a sample of this chunk where:
The blue block corresponds to the first child chunk.
The yellow block corresponds to the second child chunk.

Extract your knowledge#
Now that you have an input dataset containing the URL and text of each article from the Dataiku Knowledge Base sample, you can create a knowledge bank using the Embed dataset recipe.
Create the Embed dataset recipe#
To do so:
Open the dataiku_kb_sample_prepared dataset.
Go to the Actions (
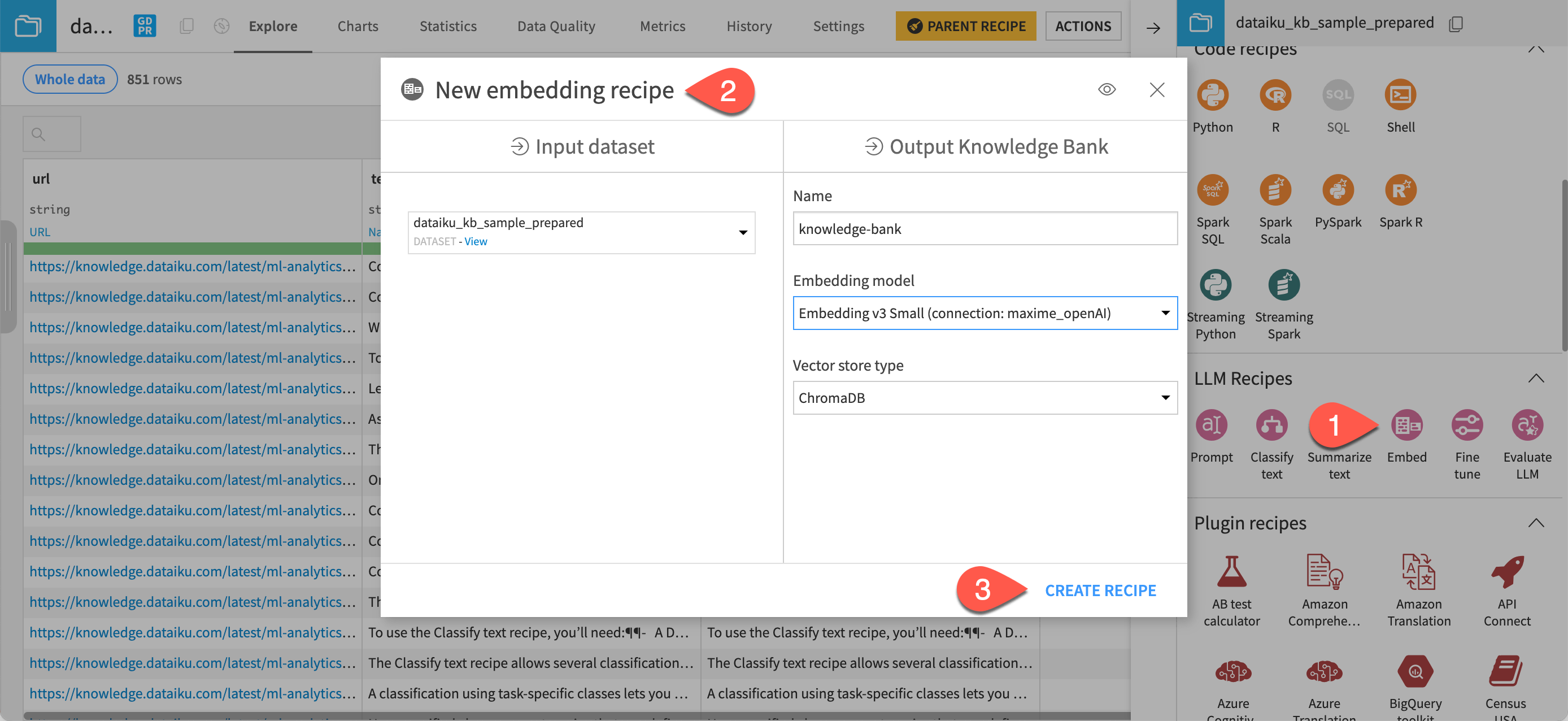
) tab of the right panel, and click Embed dataset under the GenAI recipes section.In the New embed dataset recipe window, name the output knowledge bank
knowledge_bank.In the Embedding model field, select an LLM you can use for text embedding (that is, text vectorization, which means encoding the semantic information into a numerical representation).
Keep the default ChromaDB vector store type.
Click Create Recipe.
Configure the Embed dataset recipe#
Now, configure the recipe to vectorize the content of the text_chunked column into a knowledge bank.
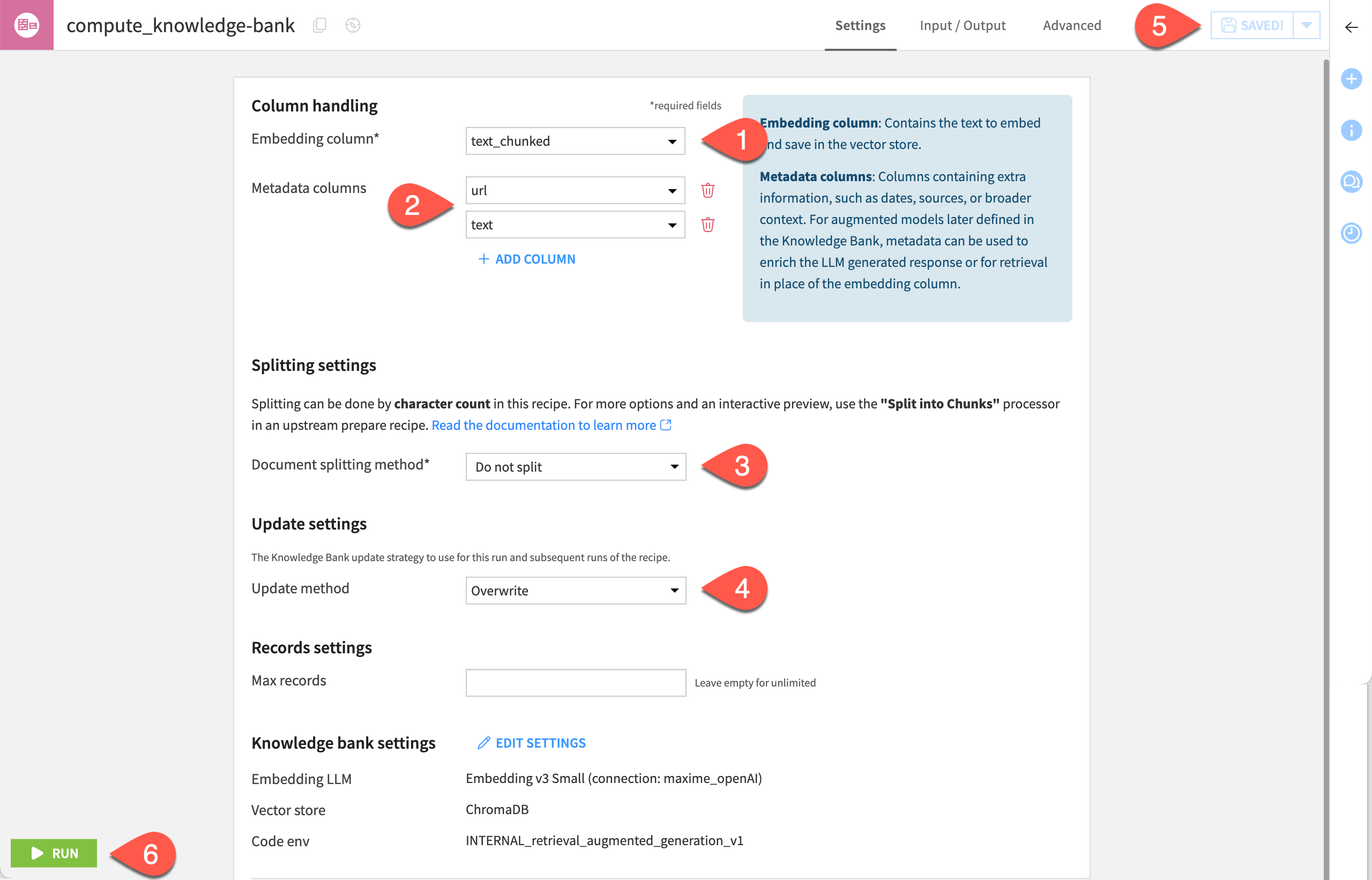
In the Embedding column field, select the text_chunked column, which is the column that includes the textual data to vectorize.
Under Metadata columns, click + Add Column twice and select:
The url column, i.e the column that stores the metadata Dataiku will use to enrich the LLM-generated response by identifying the source used in the responses.
The text column, which you’ll use to configure the augmented model defined in the knowledge bank for retrieval in place of the embedded column.
In the Document splitting method option, select Do not split as you split the data in earlier stages of the Flow.
Keep the default Overwrite method to update the vector store.
See also
For more information on the different update methods, see the Adding Knowledge to LLMs documentation.
Click Run to create the knowledge bank, which is the object that stores the output of the text embedding.
Open the output knowledge_bank when the job finishes.
Next steps#
Now that you have a knowledge bank, you could continue directly to Option 1: Augment an LLM with your internal knowledge. Following this tutorial, you’ll create an augmented LLM from your knowledge bank.
See also
For more information:
On the Embed documents recipe and the RAG approach, see Concept | Embed recipes and Retrieval Augmented Generation (RAG).
The reference documentation on Adding Knowledge to LLMs.
On guardrails, see RAG guardrails.