
Tutorial | Prompt engineering with LLMs#
Get started#
Designing high-quality prompts, a process known as prompt engineering, is the quickest and most efficient way to leverage Generative AI models and adapt them for specific business purposes.
In Dataiku, Prompt Studios allow you to test and iterate on prompts until the model produces your desired response, and the Prompt recipe allows you to operationalize the prompt.
Objectives#
In this tutorial, you will:
Use Prompt Studios to engineer prompts for a large language model to summarize and classify text.
Push your final prompt to the Flow using the Prompt recipe.
Prerequisites#
To complete this tutorial, you will need:
Dataiku 12.5 or later.
An Advanced Analytics Designer or Full Designer user profile.
A connection to at least one supported Generative AI model. Your administrator must configure the connection beforehand in the Administration panel > Connections > New connection > LLM Mesh. Supported model connections include models such as OpenAI, Hugging Face, Cohere, etc.
Tip
You don’t need previous experience with large language models (LLMs), though it would be useful to read the article Concept | Prompt Studios and Prompt recipe before completing this tutorial.
Create the project#
From the Dataiku Design homepage, click + New Project.
Select Learning projects.
Search for and select Prompt Engineering.
If needed, change the folder into which the project will be installed, and click Create.
From the project homepage, click Go to Flow (or type
g+f).
Note
You can also download the starter project from this website and import it as a ZIP file.
This tutorial uses a dataset of news articles, including the headline, text and date published. We’ll work with a small subset of articles to reduce computation cost.
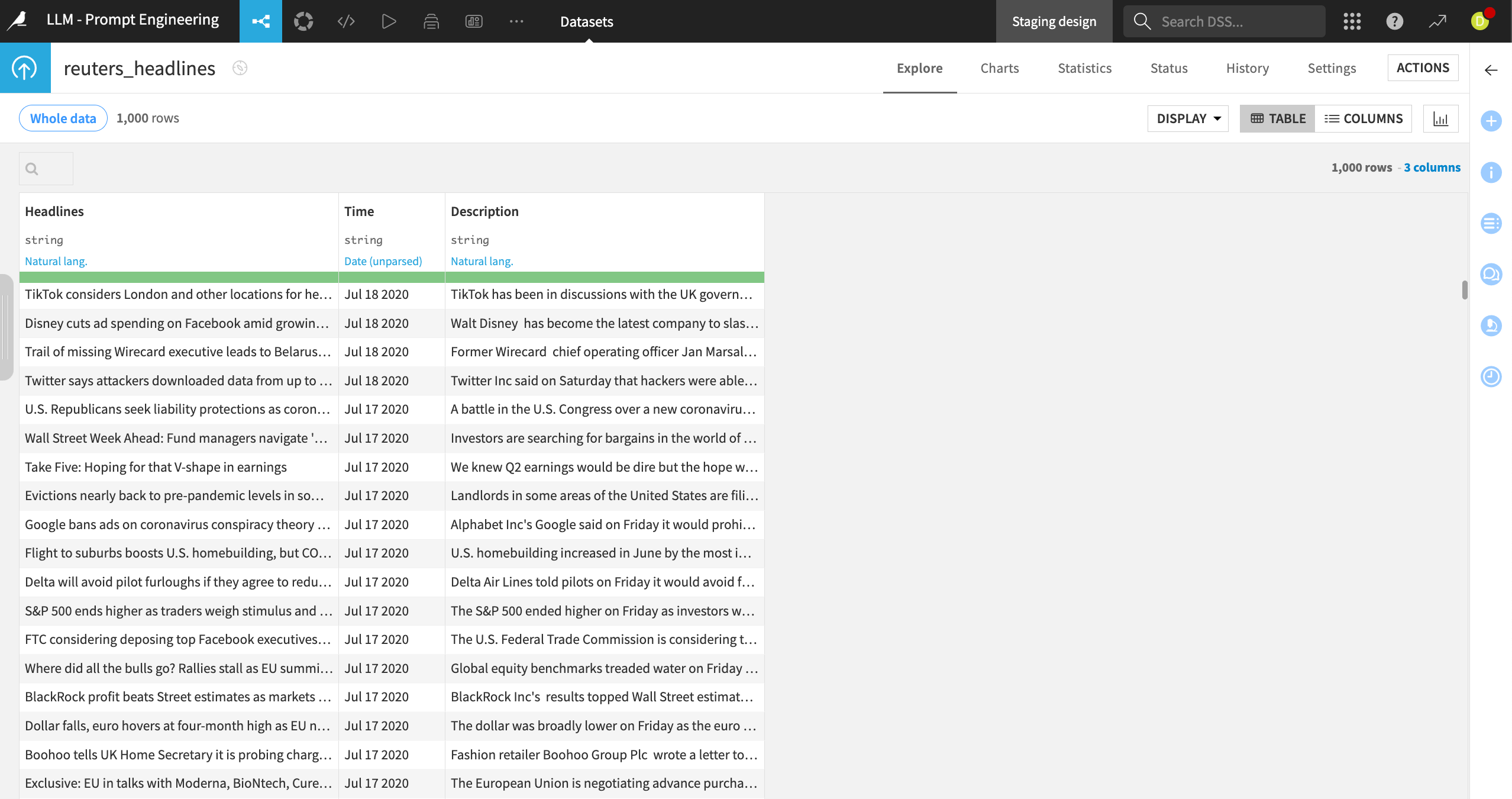
Let’s say we want to know the main subjects of each article, and for the results to be returned in JSON format so we can use them in downstream recipes and models. We can use Prompt Studio to build and iterate on a prompt that automates this process.
Tip
To view the full text in the Article or Heading columns, right click on the value and select Show complete value, or use the keyboard shortcut Shift + V.
Open a new Prompt Studio#
We’ll start by creating a new Prompt Studio to experiment with and iterate on the prompts.
In the top navigation bar, select GenAI (
 ) > Prompt Studios.
) > Prompt Studios.Click + New Prompt Studio in the top right.
Give the new studio the name
News headlines, then click Create.In the Add a new prompt window, select Managed mode and click Create.
In the Prompt design page, choose the LLM you want to use with your prompt.
Note
The selections available will depend on the connection set up by your administrator. For example, if you are connected to OpenAI, you can use GPT models. If you have access to multiple LLMs, you can change this selection later and experiment with different models using your prompt.
Design the prompt#
On the Prompt design page, you can add your prompt text, provide examples with the desired output, and run test cases using the LLM, before deploying the prompt on your entire dataset.
Our prompt will instruct the model to determine the topic of each provided news article. To prevent it from creating too many topics, we’ll also give it a list of potential topics we’re interested in.
To write the first iteration of the prompt:
In the Prompt input window, copy and paste the following prompt, replacing the text Explain here what the model must do. Use the Copy button at the top right of the block for easier copying.
Determine whether each topic of the following list of topics is covered in the financial news article provided.
List of topics: fed and central banks, company and product news, corporate debt and earnings, energy and oil, currencies, gold and metals, IPO, legal and regulation, M&A and investments, markets, politics, stock movement, sports.
In the Inputs from menu, select Written test cases.
Under Description, create two Inputs:
HeadlineandText.In the Test cases section, click + Add Test Case and copy and paste the following text into the corresponding boxes:
Headline:
Manufacturing, vaccine data power stocks higher; U.S. dollar dips
Text:
Stocks across the globe rose on Wednesday following data pointing to a recovery in manufacturing and on bets for a COVID-19 vaccine, while the risk-on mood pushed the U.S. dollar lower.
Add another test case with the following text in the boxes:
Headline:
U.S. weekly jobless claims up slightly; leading indicator rises
Text:
The number of Americans filing for unemployment benefits rose just marginally last week, suggesting strong job growth in March that should underpin consumer spending.
Click Run Prompt to pass the prompt and test cases to your selected model.
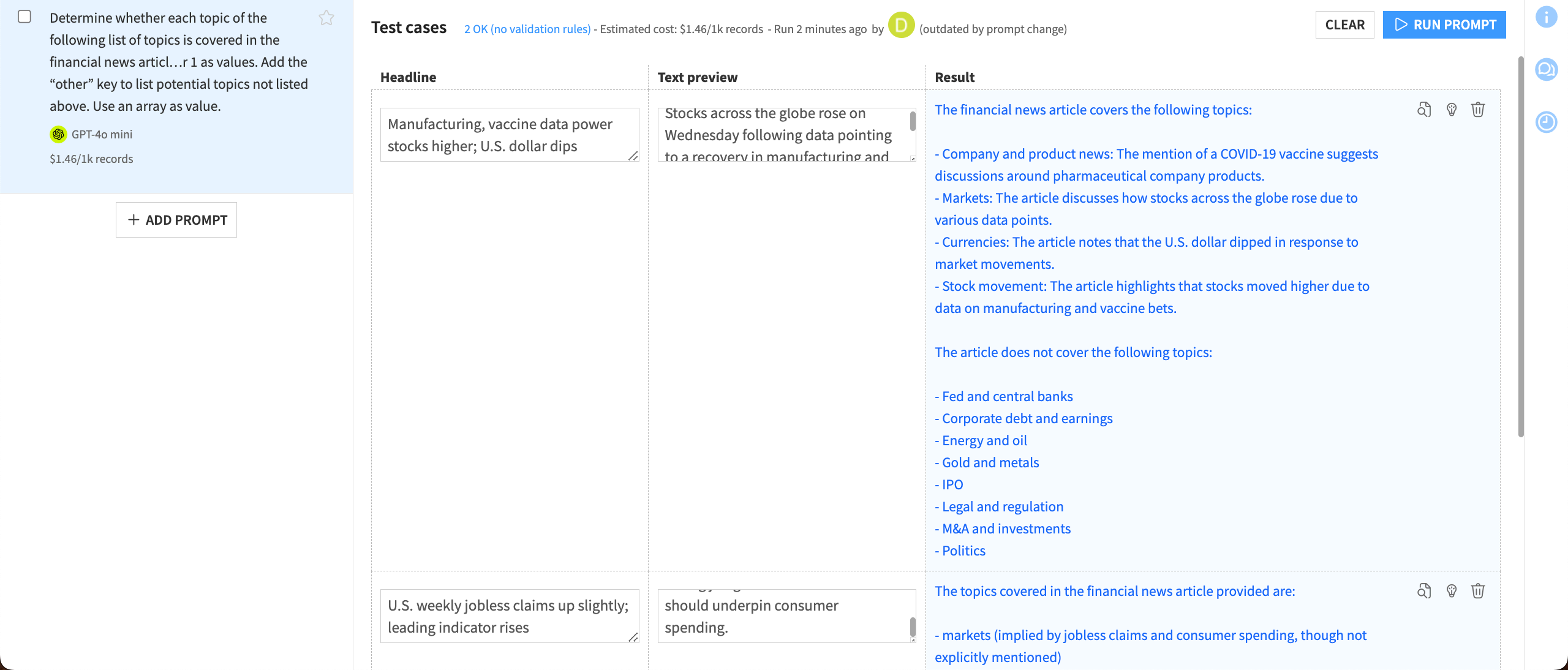
Depending on the model you selected, you’ll see different results. In this case, using GPT-4o, we can see several problems with the responses. The model answered in complete sentences, and each response is in a slightly different format. Neither format is useful for further analysis.
You might notice other issues depending on your results. For example, the model might return topics that weren’t in your initial list.
We can fix these issues with a bit of prompt engineering.
Iterate on the prompt#
Refine the prompt#
First, let’s specify the format for the model’s results. The most useful format for downstream recipes would be a JSON object where topics are listed as the keys along with 0 or 1 values to indicate whether they’re present. Later, we could parse the JSON using a Prepare recipe and use the results in other recipes or machine learning models.
We can also instruct the model to bucket any topics not in the initial list under an “other” topic, to keep the results clean and consistent with the topics we’re interested in.
Copy and paste the following text to the prompt, under the list of topics:
Format your response as a JSON object with each topic as the keys, and 0 or 1 as values. Add the "other" key to list potential topics not listed above. Use an array as value.
Provide examples to the LLM#
Another way to help the model understand what’s expected is to provide examples with input and the desired output. We can do this in Examples located above the test cases.
In the Examples area, click + Add Example.
Copy and paste the following text into the corresponding boxes:
Input: Headline
Travel stocks soar as encouraging vaccine study lifts Europe
Input: Text
European stocks closed at over a five-week high on Wednesday, with travel stocks surfing a wave of optimism following reports of progress in developing a COVID-19 vaccine.
Output
{
"company and product news": 0,
"corporate debt and earnings": 0,
"IPO": 0,
"M&A and investments": 0,
"stock movement": 1,
"markets": 1,
"legal and regulation": 0,
"politics": 0,
"currencies": 0,
"gold and metals": 0,
"energy and oil": 0,
"fed and central banks": 0,
"sports": 0,
"other": []
}
Add another example with the following text:
Input: Headline
Oil climbs 2% on U.S. stock draw but gains capped as OPEC+ set to ease cuts
Input: Text
Oil prices rose 2% on Wednesday, supported by a sharp drop in U.S. crude inventories, but further gains were limited as OPEC and its allies are set to ease supply curbs from August as the global economy gradually recovers from the coronavirus pandemic.
Output
{
"company and product news": 0,
"corporate debt and earnings": 0,
"IPO": 0,
"M&A and investments": 0,
"stock movement": 0,
"markets": 0,
"legal and regulation": 0,
"politics": 0,
"currencies": 0,
"gold and metals": 0,
"energy and oil": 1,
"fed and central banks": 0,
"sports": 0,
"other": []
}
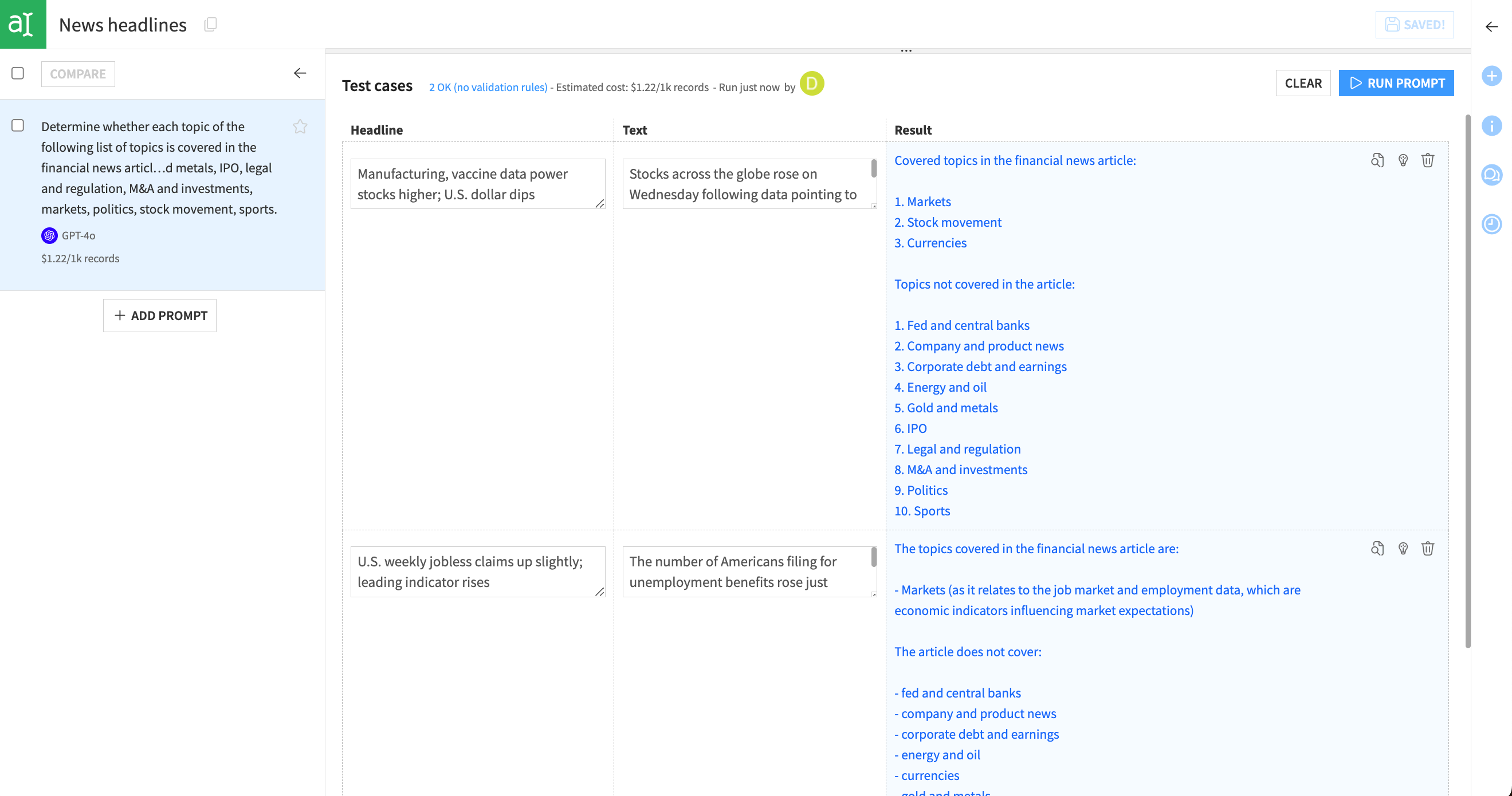
Click Run Prompt and review the results.
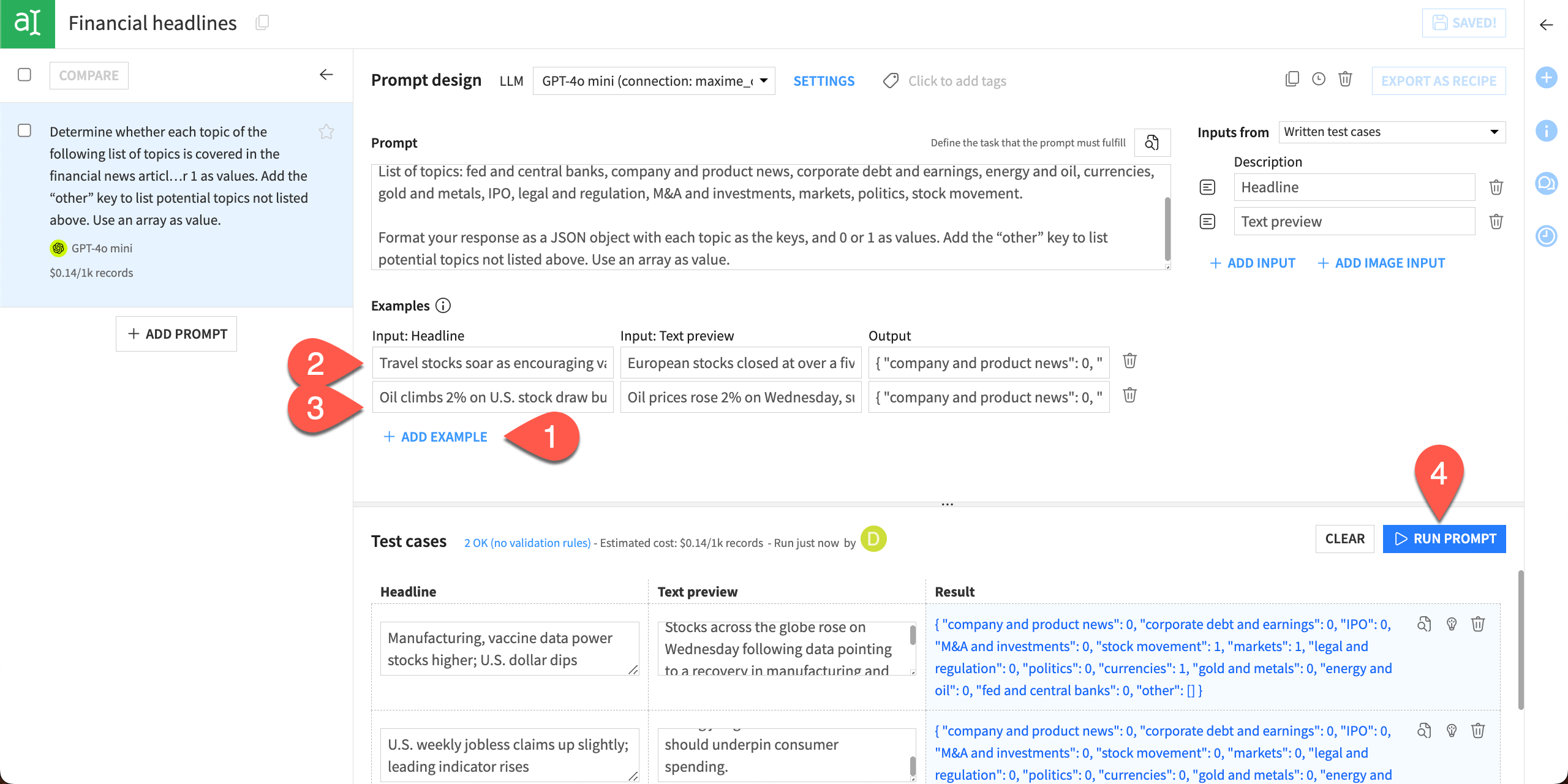
Results from the test cases should be much improved. The output is in JSON format, which can be parsed. Any topics not in the original list are included within the other array. If there are no other topics in the output, the other array will be empty.
Use the dataset for test cases#
Now that we have an efficient and useful prompt, we can run it on more test cases from the dataset.
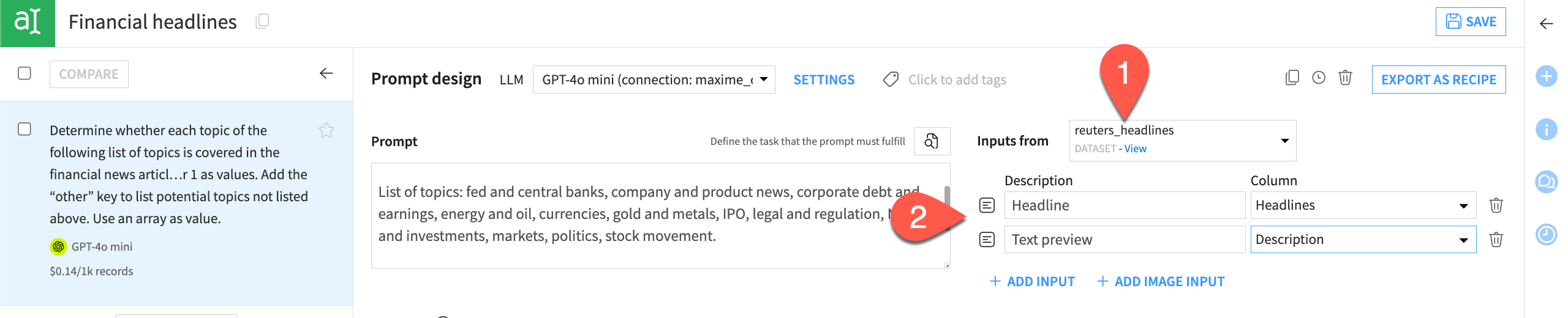
Change the Inputs from option to the dataset articles_filtered.
Map the Headline description to the column Heading and the Text description to the Article column.
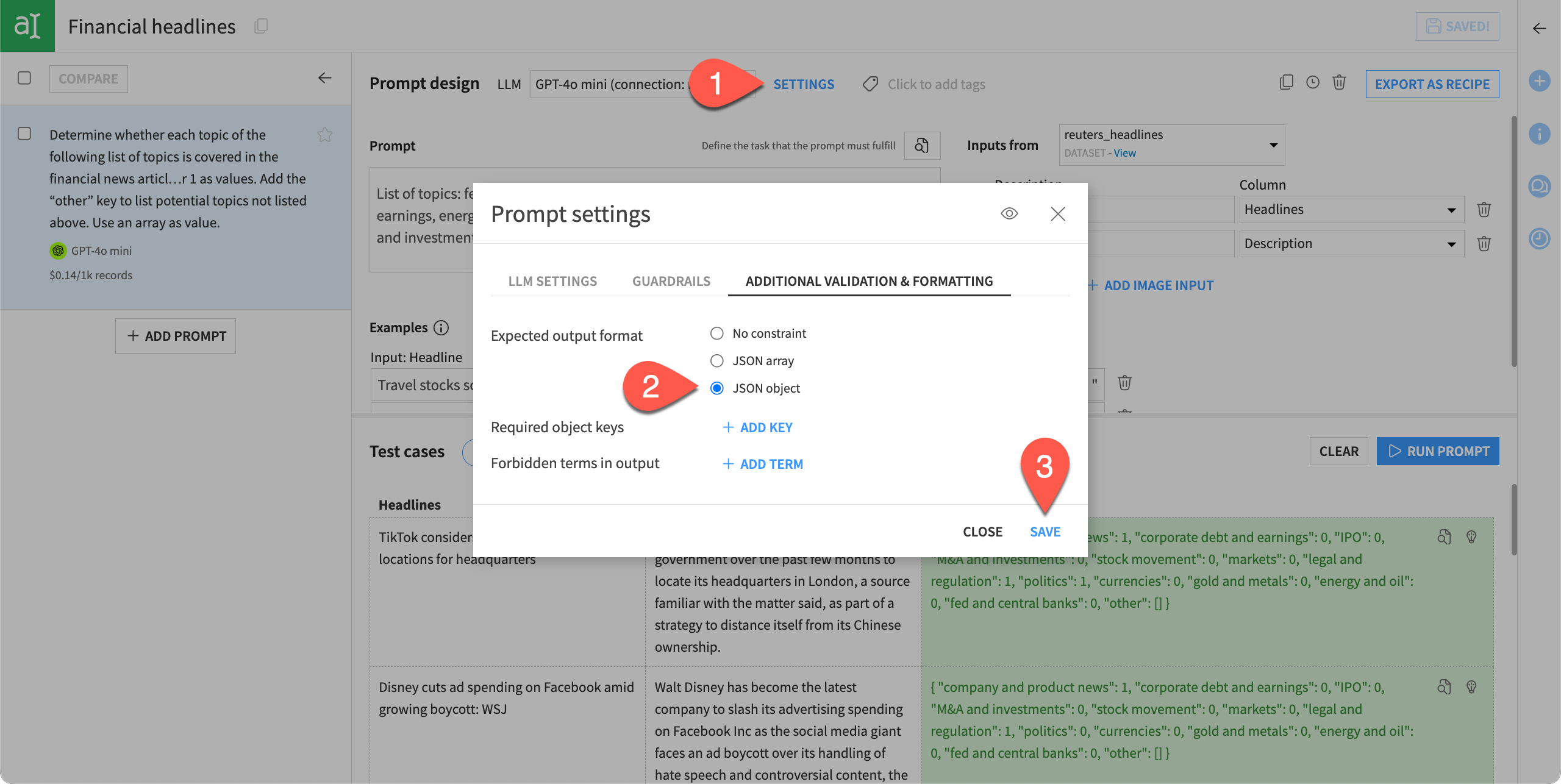
We can also set a validation rule to check that the output conforms to the expected JSON object format.
Next to the Prompt design and model selection, click Settings.
In the Additional Settings tab, select the Expected output format of JSON object.
Click Save to preserve the settings.
When we run the model again, it will use a small sample of test cases from the dataset instead of the test cases we entered manually. Results will be based on the same prompt and examples.
Click Run Prompt.
Explore the results.
The model ran on eight test cases selected from the dataset (you can change the number of test cases by clicking on the 8 records button). It also returns an estimated cost per 1,000 records to run the full dataset. Results are colored green if they pass the validation test for JSON objects and colored red if they fail the test.
Tip
If your results don’t pass the validation test, make sure your example outputs are in the correct format for JSON objects.
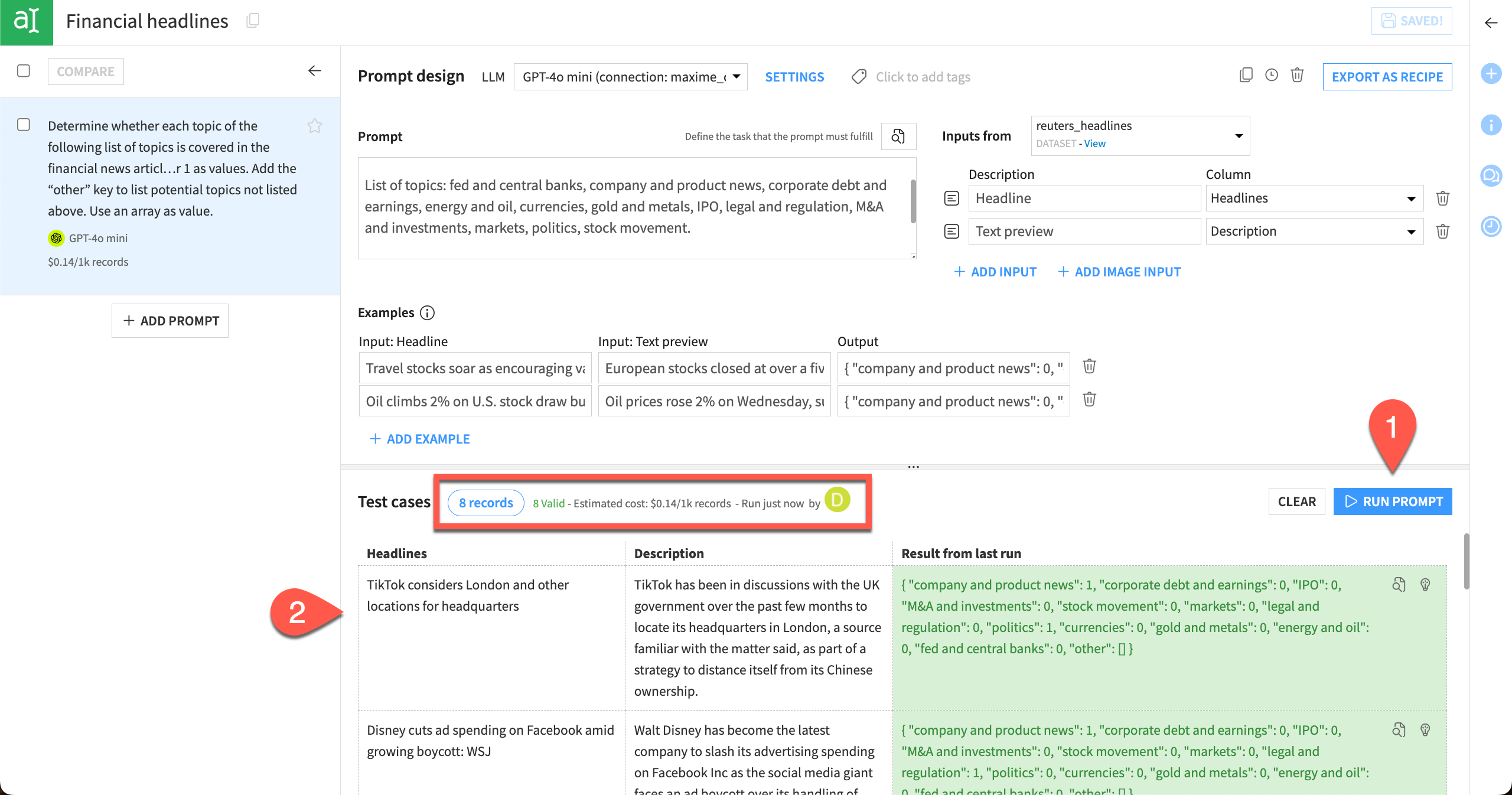
We can see that all the results passed the validation test, and we’re ready to save our prompt as a recipe so we can deploy it to the Flow.
Deploy a Prompt recipe#
You can save your crafted prompt as a recipe directly from Prompt Studio. The recipe will process the entire dataset using the prompt we created.
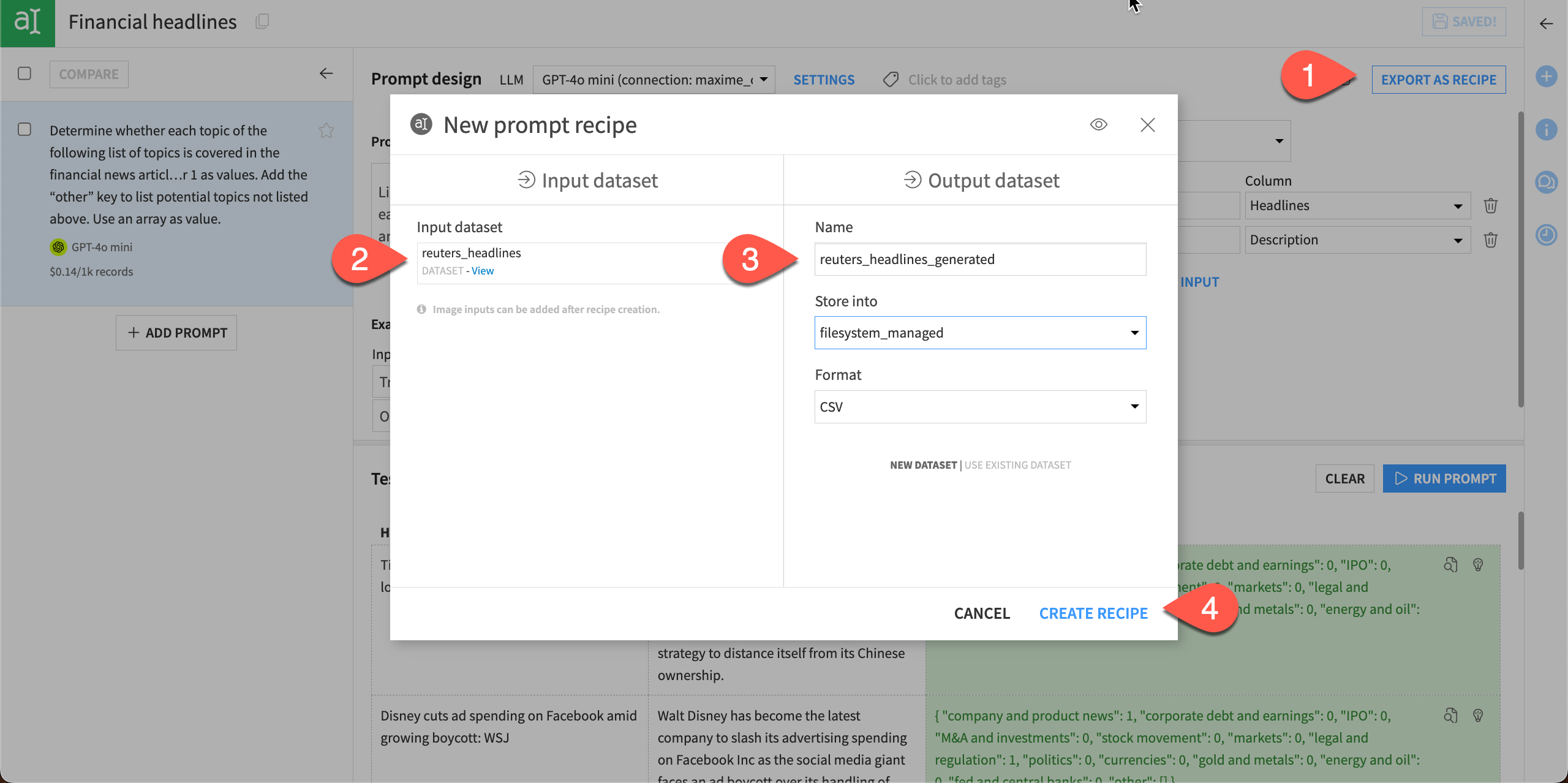
In the top right, select Export as Recipe, and Create in the next window to create a new Prompt recipe.
In the New prompt recipe window, make sure the Input dataset is articles_filtered.
Give the Output dataset a name or use the default, and choose a storage connection and output file format.
Click Create Recipe.
Dataiku creates a new Prompt recipe with the settings pre-filled from your work in Prompt Studio. You’ll see the prompt text, input columns, and examples with output.
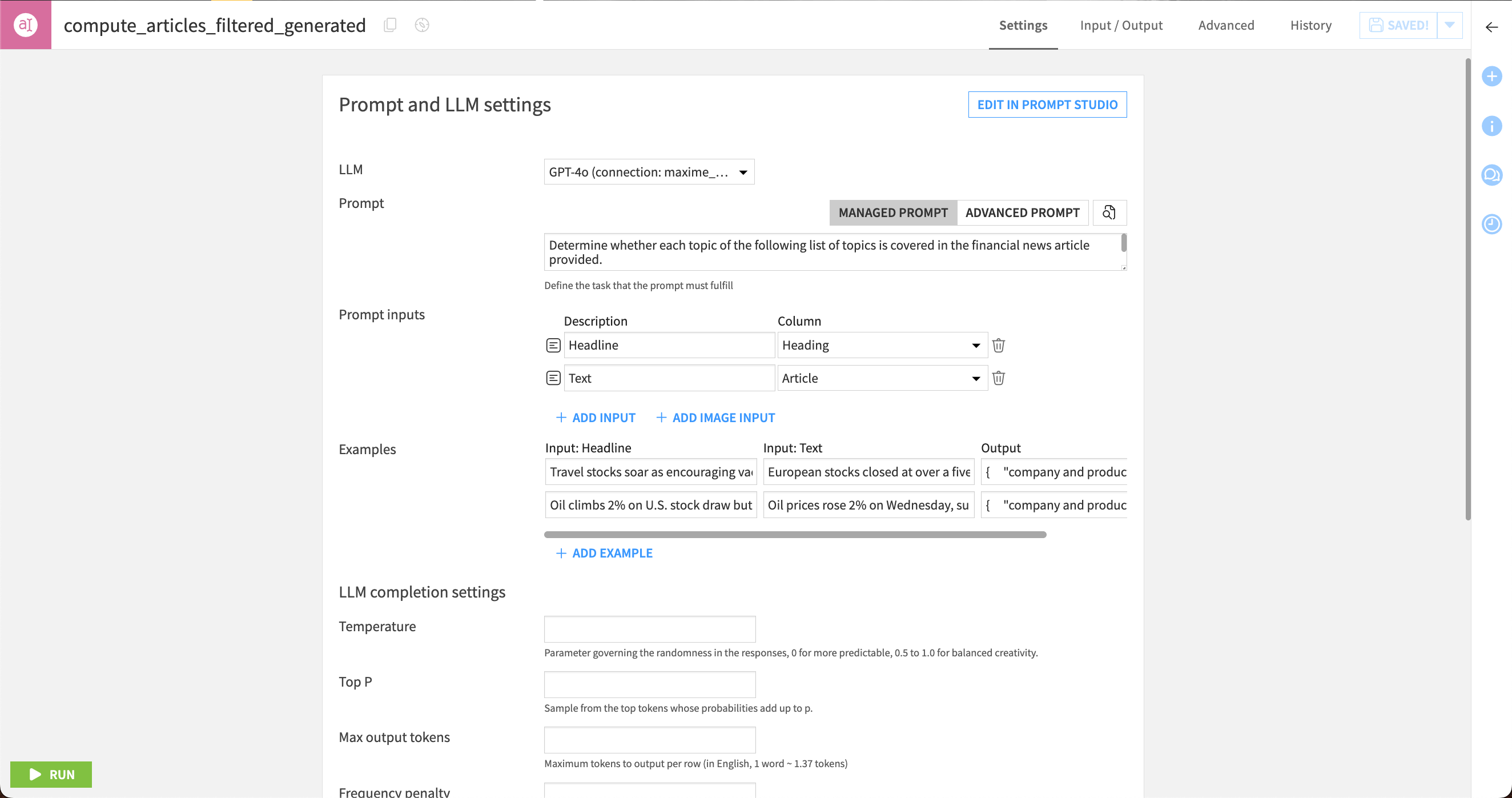
If you’d like, you can run the recipe to use the model on the entire headlines dataset and create an output dataset ready for further analysis or model training.
Important
If you’re using a commercial model, this will incur some costs from the Generative AI company for processing 1,000 rows.
Next steps#
Congratulations! You have designed an effective prompt using Prompt Studios and deployed it to the Flow using the Prompt recipe.
You can explore other use concepts and tutorials using LLMs in the Knowledge Base.