
Tutorial | Processing text with the Prompt recipe#
Get started#
The Prompt recipe allows you to write prompts, or instructions to a large language model (LLM), to process datasets.
Let’s see how the recipe can be used to process text in different ways!
Objectives#
In this tutorial, you will:
Use an LLM connection and the Prompt recipe to translate a database of product reviews.
Extract entities from the reviews also using an LLM.
Validate results from the model.
Prerequisites#
To complete this tutorial, you will need:
Dataiku 12.5 or later.
An Advanced Analytics Designer or Full Designer user profile.
A connection to at least one supported Generative AI model. Your administrator must configure the connection beforehand in the Administration panel > Connections > New connection > LLM Mesh. Supported model connections include models such as OpenAI, Hugging Face, Cohere, etc.
Tip
You don’t need previous experience with large language models (LLMs), though it would be useful to read the article Concept | Prompt Studios and Prompt recipe before completing this tutorial.
Create the project#
From the Dataiku Design homepage, click + New Project.
Select Learning projects.
Search for and select Prompt Recipe.
If needed, change the folder into which the project will be installed, and click Create.
From the project homepage, click Go to Flow (or type
g+f).
Note
You can also download the starter project from this website and import it as a ZIP file.
This tutorial uses a dataset of product reviews from online shoppers. We’ll work with a small subset reviews to reduce computation cost.
Translate text#
Let’s say we want to translate the online product reviews from English into French.
Create the Prompt recipe#
Start by creating a Prompt recipe to process this data.
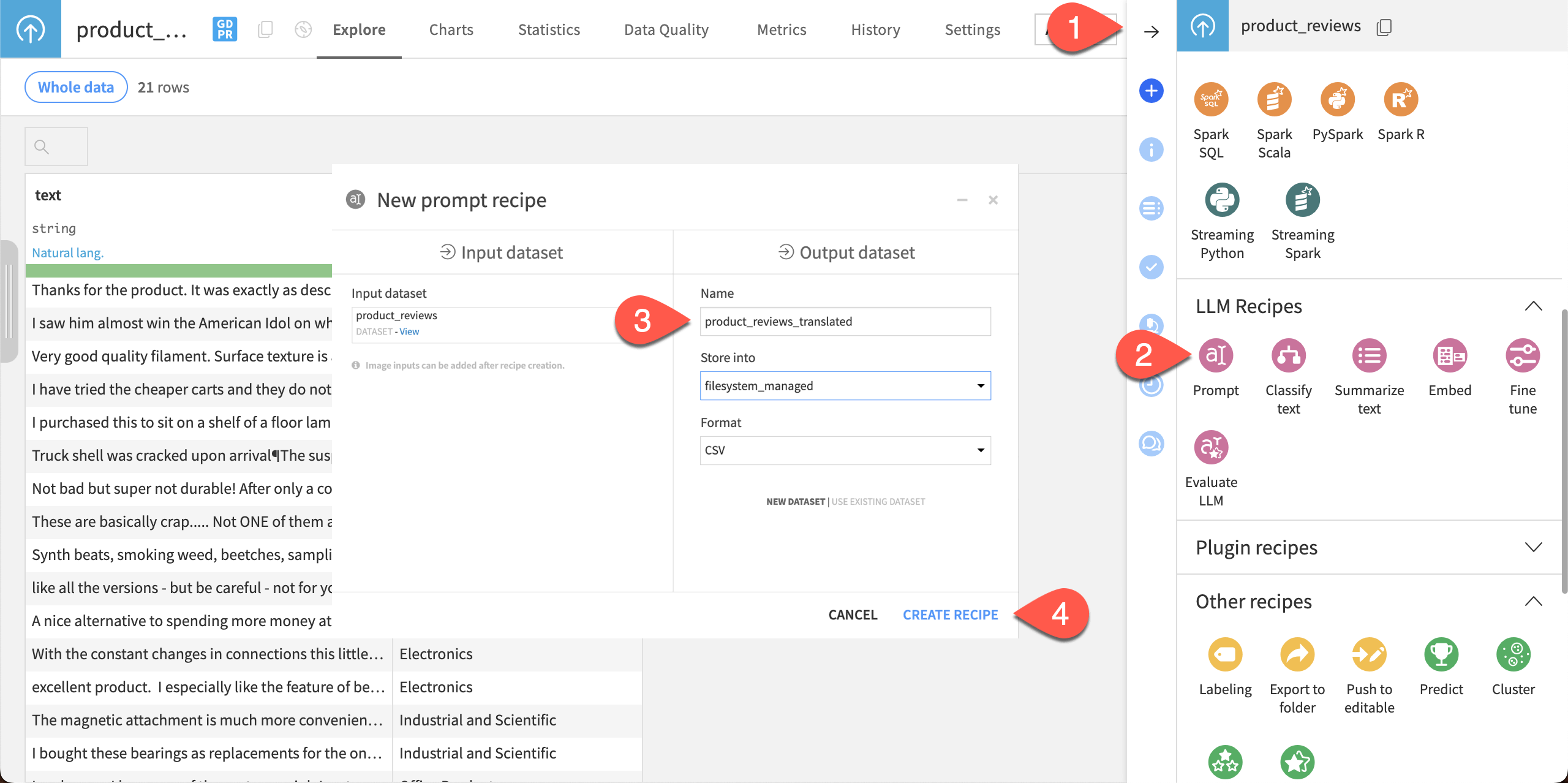
From within the dataset or with it selected in the Flow, navigate to the Actions panel.
Under GenAI recipes, select the Prompt recipe.
Change the name of the Output dataset to
product_reviews_translated.Click Create recipe.
Write the prompt#
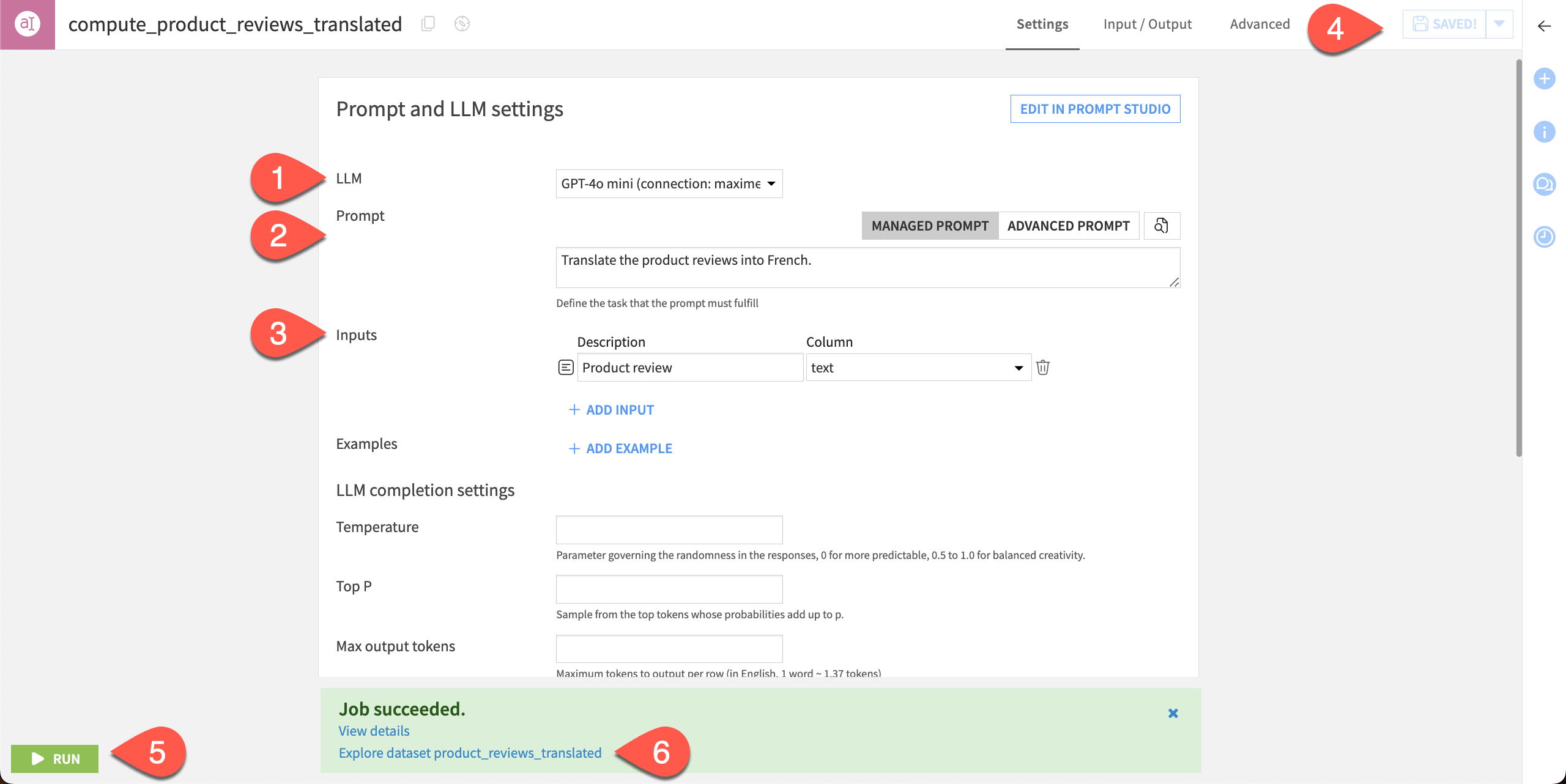
In the recipe settings, you can write a prompt directly.
Choose your LLM connection. The options depend on your connections; in this tutorial we will use the GPT-4o mini model from OpenAI.
In the Prompt box, copy and paste the following text:
Translate the product reviews into French.
Click Add input and add the following:
Description:
Product reviewColumn:
text
Click Save.
Click Run to execute the recipe.
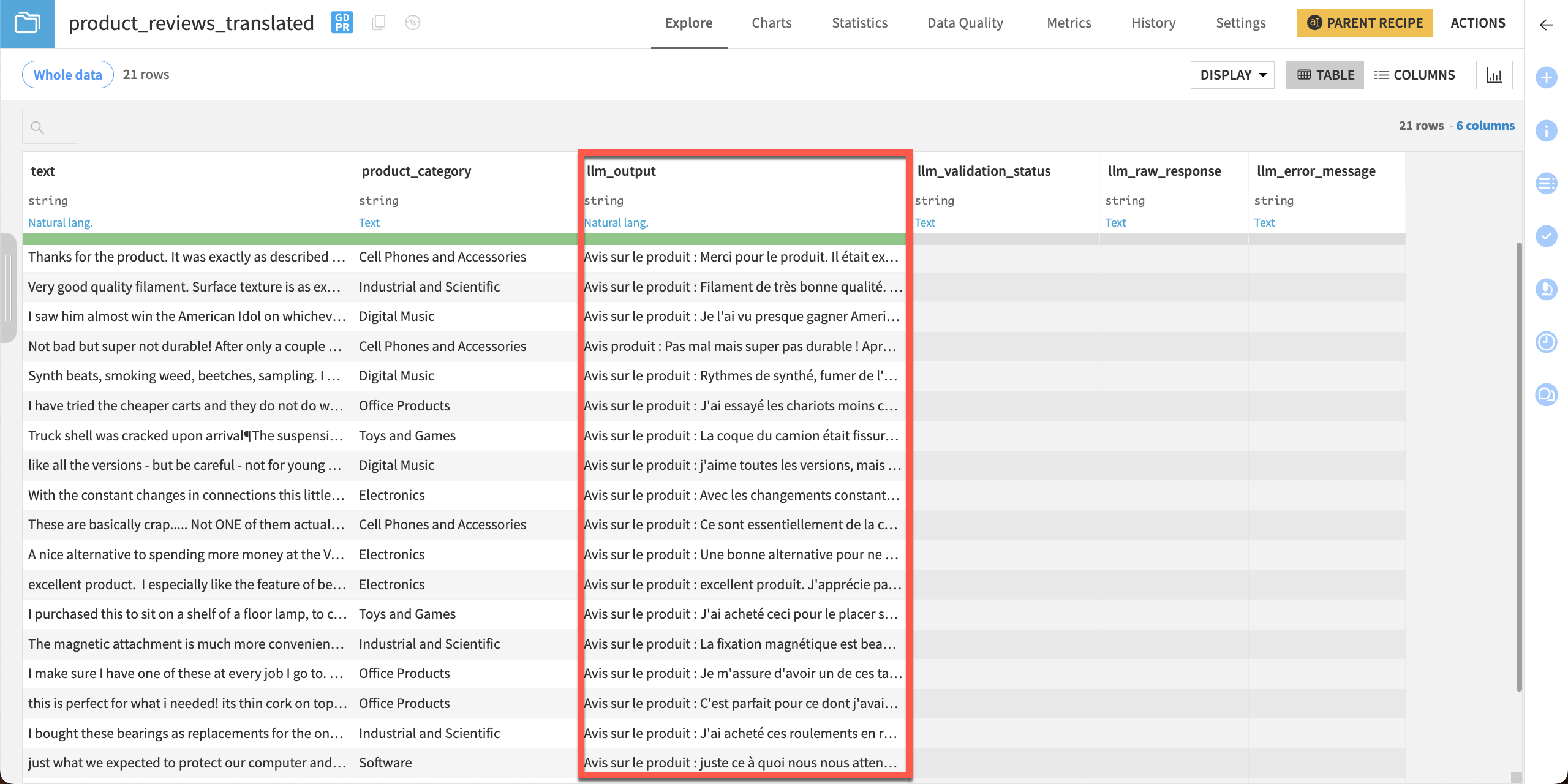
After the recipe has finished running, click Explore dataset product_reviews_translated.
The output dataset contains an llm_output column with the model’s results of translated product reviews.
Now let’s write a more complex prompt!
Extract entities from text#
Entity extraction, also known as named entity recognition (NER), is a natural language processing (NLP) technique used to identify and extract important data points, such as names, locations, organizations, dates, or email addresses.
Entity extraction can help turn unstructured text into structured data that can be used to search, analyze, or build models. It can also be used to help detect events and participants involved, to analyze sentiment around entities, or summarize texts.
Let’s use the Prompt recipe to extract useful information from product reviews.
Create the recipe#
We’ll create another Prompt recipe to process the same dataset (product_reviews) with a different prompt.
Follow the same steps as above to create a new Prompt recipe.
Name the Output dataset
product_reviews_extracted.
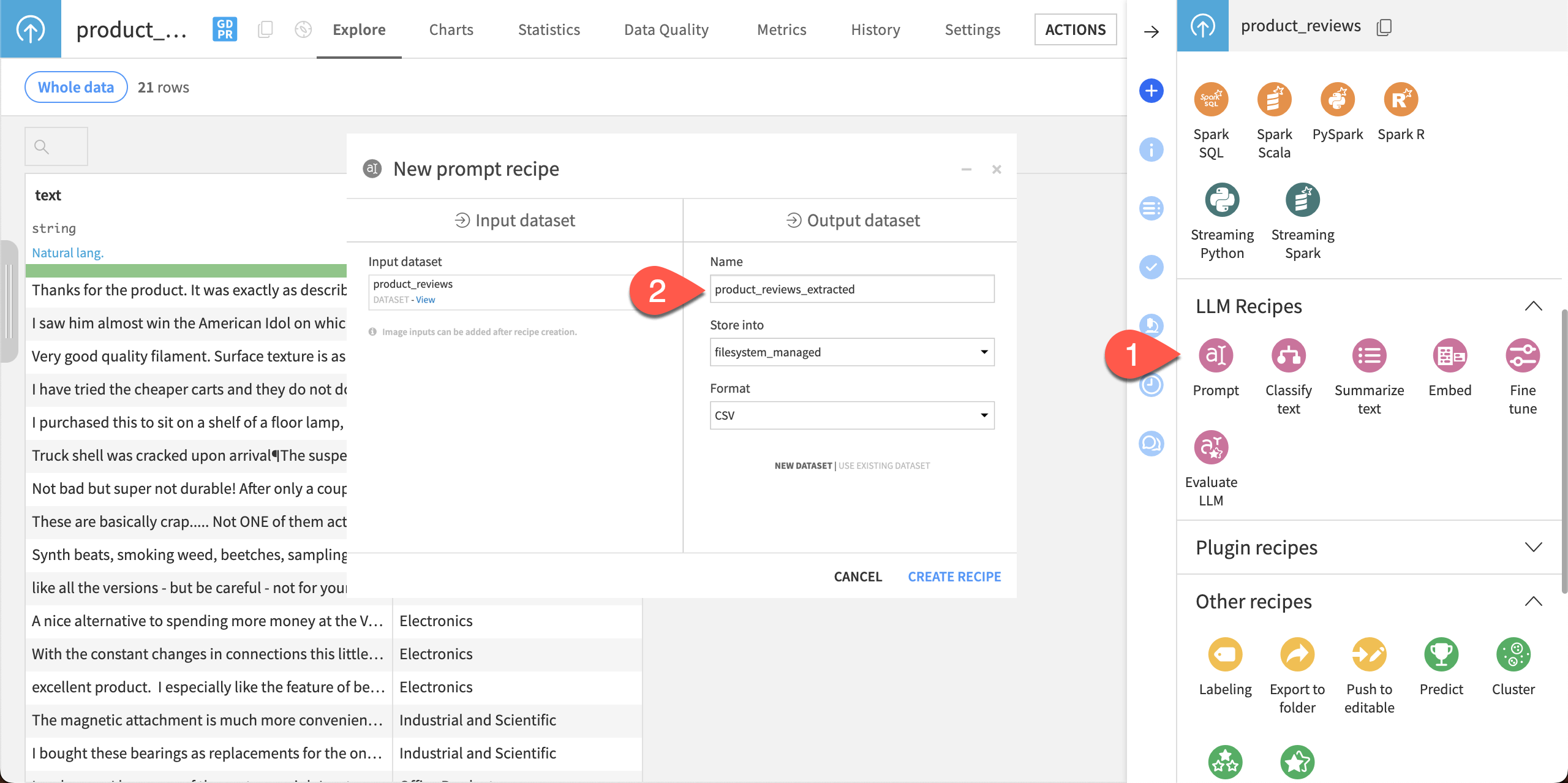
Write the prompt#
This prompt will instruct the LLM to extract information from the reviews, including the name of the product, sentiment, a summary, and other useful information. The output format will be in JSON, which we could then parse and analyze more easily than the raw text.
Choose an LLM connection.
In the Prompt box, copy and paste the following text:
Extract the key information from the below product reviews in JSON format (no Markdown). Your answer should follow the JSON schema below:
{
"title": "Product review",
"description": "A product review",
"type": "object",
"properties": {
"name": {
"description": "The name of the product covered in the review. 'Unknown' if it can't be determined",
"type": "string"
},
"summary": {
"description": "A summary of the review",
"type": "string"
},
"predicted_sentiment": {
"description": "Whether the product review is positive, negative or neutral",
"type": "string",
"enum": ["positive", "neutral", "negative"],
},
"advantages": {
"description": "Advantages of the products mentioned in the review. Return an empty list if the review doesn't mention an advantage",
"type": "array",
"items": {
"type": "string"
}
}
},
"drawbacks": {
"description": "Drawbacks of the products mentioned in the review. Return an empty list if the review doesn't mention a drawback",
"type": "array",
"items": {
"type": "string"
}
}
},
"required": [ "name", "summary", "sentiment", "advantages", "drawbacks"]
}
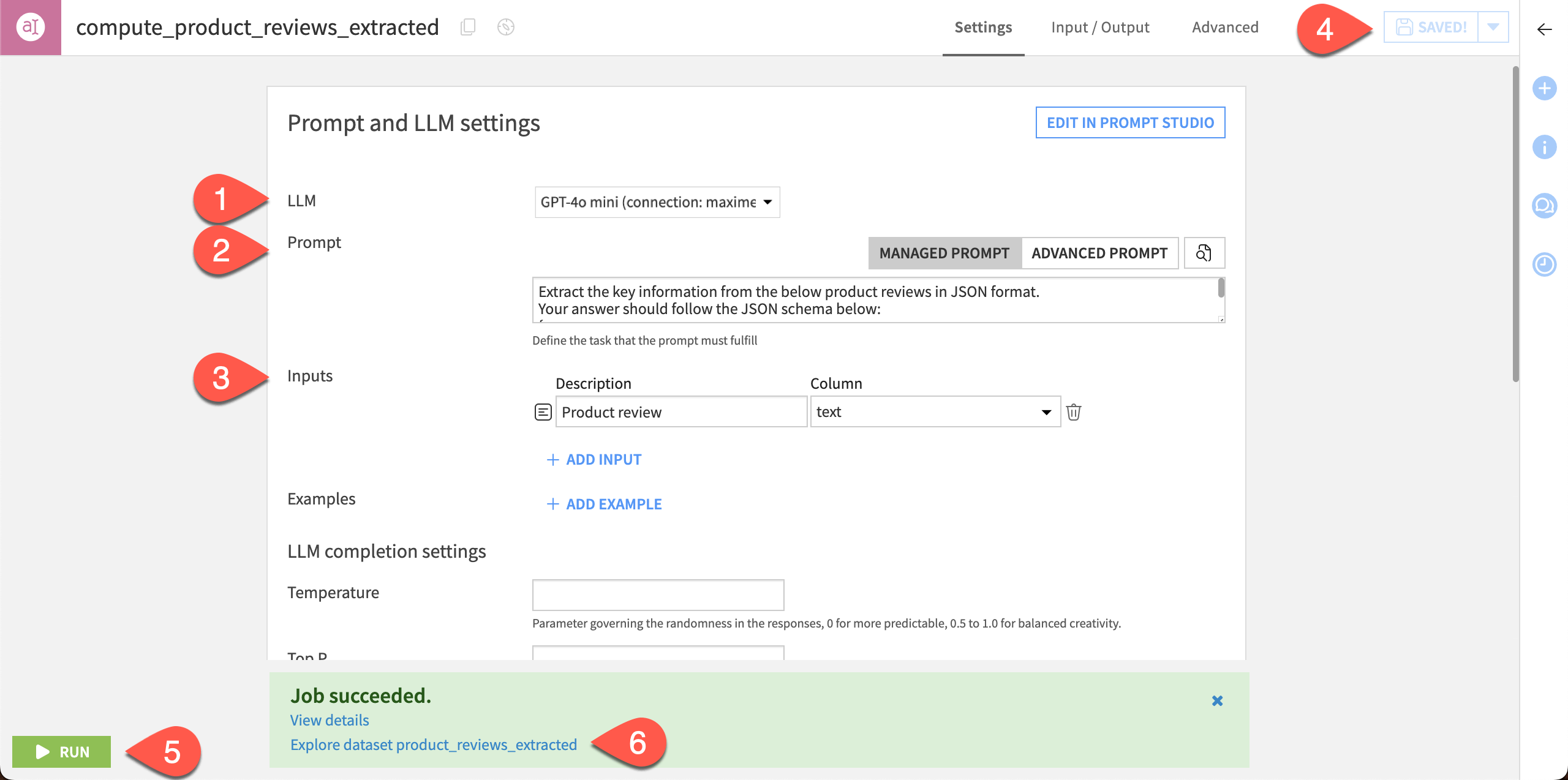
Click Add input and add the following:
Description:
Product reviewColumn:
text
Click Save.
Click Run to execute the recipe.
After the recipe has finished running, click Explore dataset product_reviews_extracted.
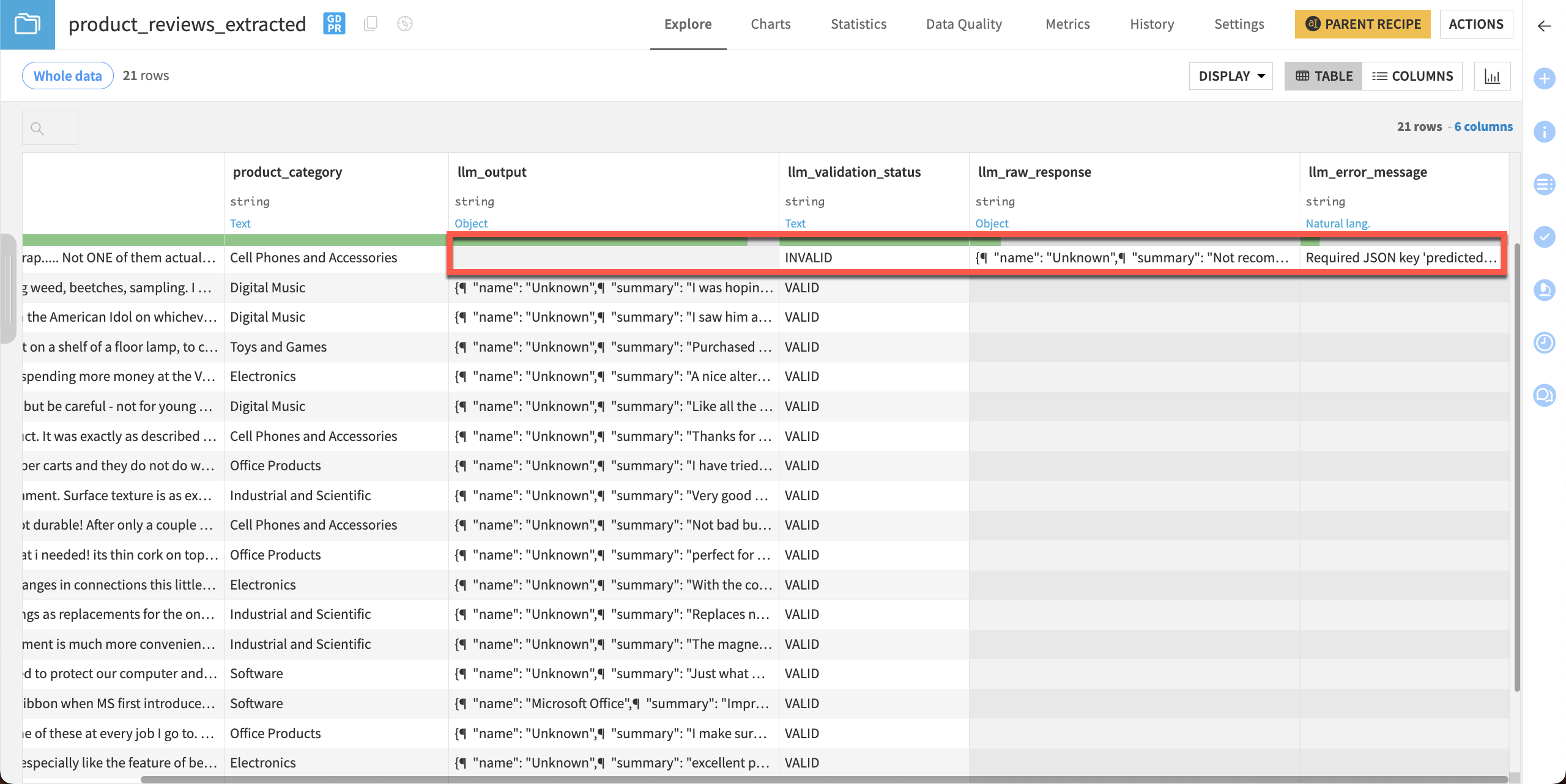
The recipe created several columns. The llm_output column contains the JSON output we instructed the model to give. Notice there is also an llm_validation_status column with no values.
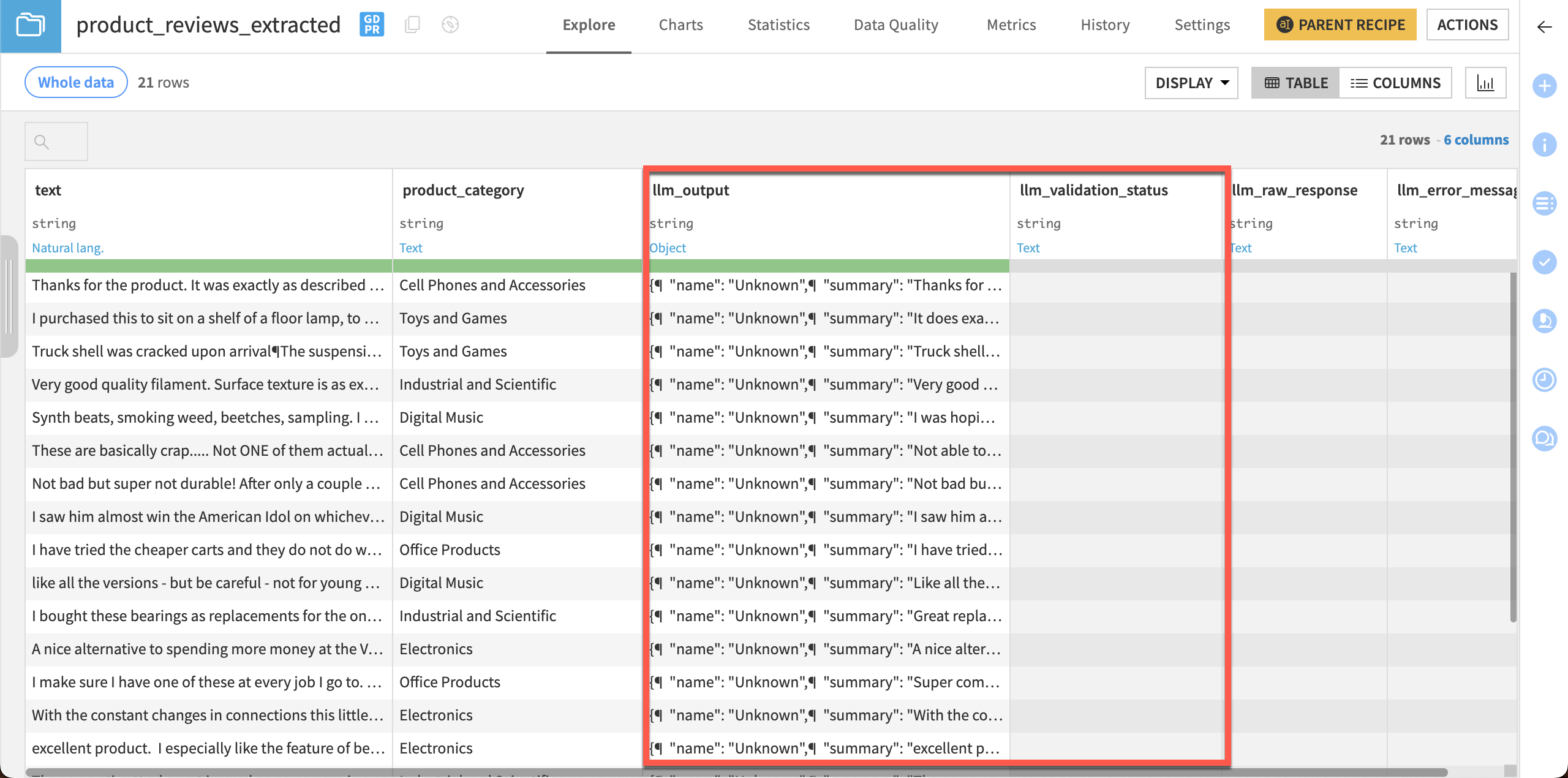
Note
Your results will vary depending on the model used and can also differ in every run.
Create validation settings#
Let’s update the recipe settings to validate that the model’s results are in the JSON format we specified in the prompt. Results will be output in the llm_validation_status column.
Click Parent Recipe to return to the recipe settings.
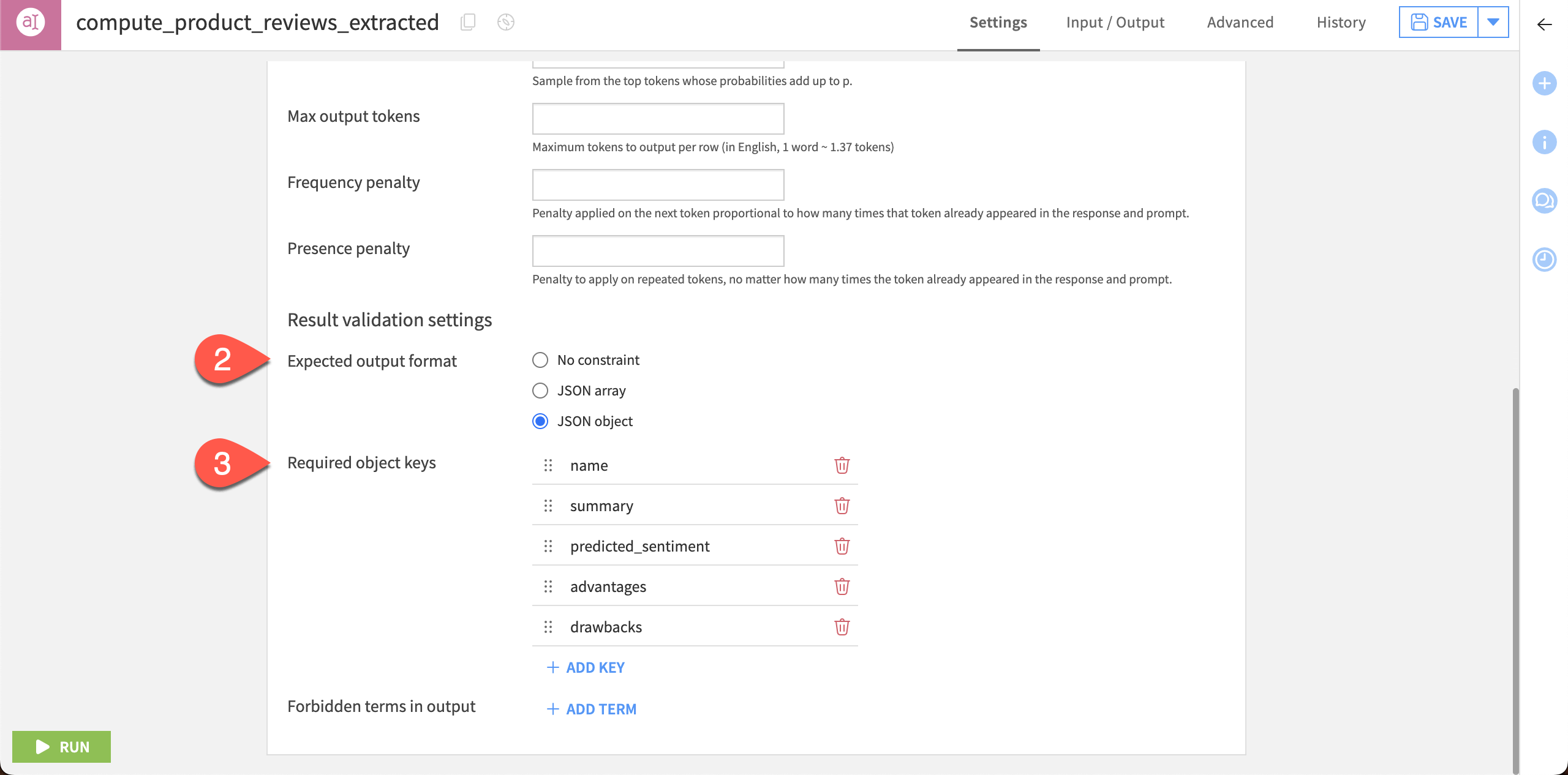
Scroll to Result validation settings > Expected output format and choose JSON object.
Click + Add Key and enter the following keys:
name
summary
predicted_sentiment
advantages
drawbacks
Save and Run the dataset, then navigate to the updated output dataset.
The output dataset now includes values in the llm_validation_status column. If you have any invalid responses the dataset will also contain a value in the llm_error_message column showing the issue.
In this example, the required JSON key predicted_sentiment wasn’t present in one response from the model.
Note
Your results will vary depending on the model used and can also differ in every run.
Tip
If you want to iterate on prompts or test different LLM performances without running them on the entire dataset, use the Prompt Studio to test results on dataset samples! You can access Prompt Studios directly from the Prompt recipe with the Edit in Prompt Studio button.