
Concept | Dataiku architecture for MLOps#
Watch the video or read the summary below.

Let’s describe the Dataiku nodes, in addition to the Design node, and how they pertain to MLOps, including:
A batch scoring project lifecycle
A real-time scoring project lifecycle
The final mile of putting machine learning models into production can be a significant challenge. One way to meet this challenge is to work within a framework that’s already prepared to push projects and models into production. This is where the architecture of Dataiku comes in!
The Dataiku architecture consists of different nodes to design your projects models and then operationalize them. You can think of these nodes as unique environments — each with its own purpose — yet are still part of the same platform.
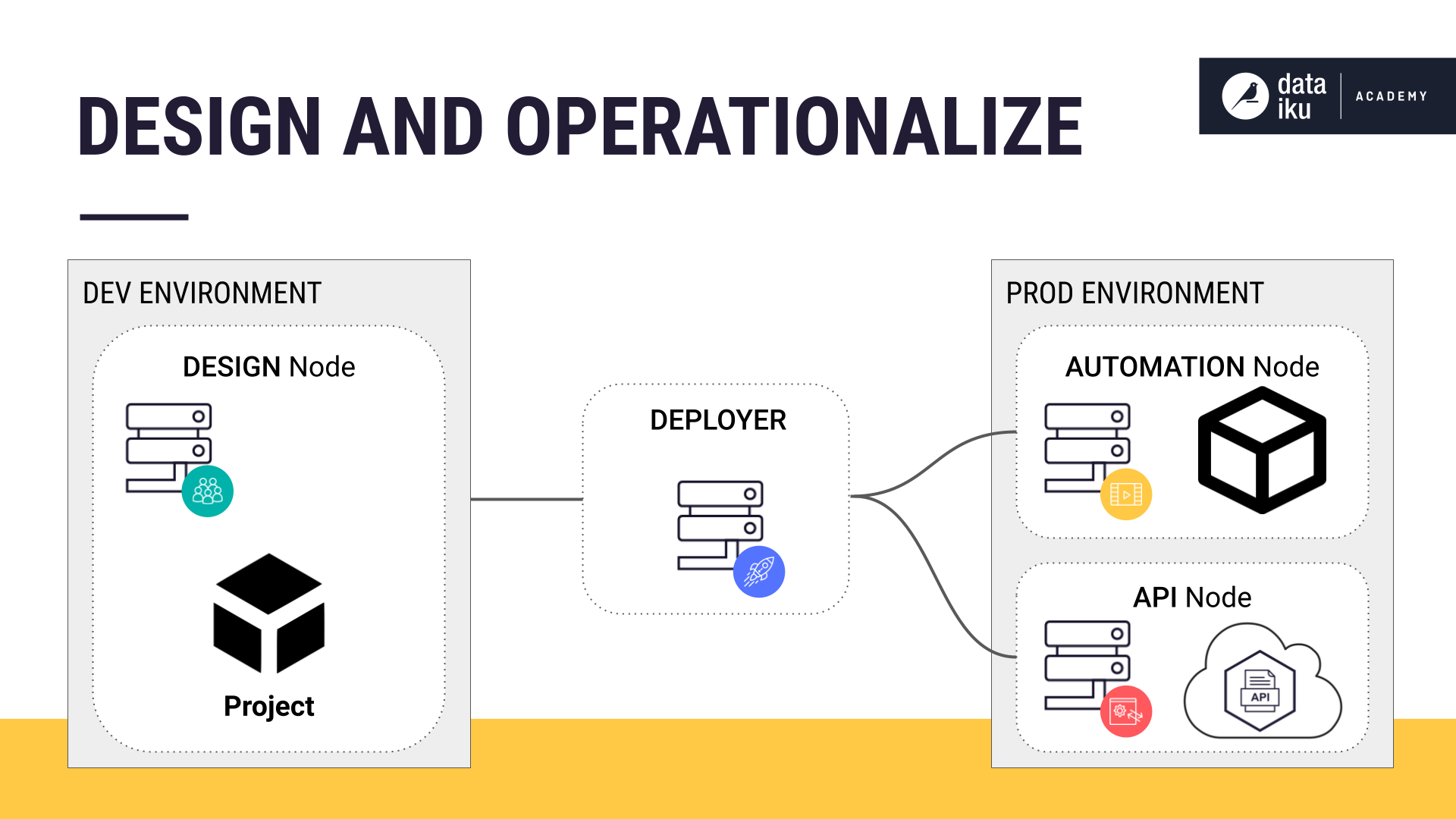
Using an example credit card fraud use case, we’ll describe the Dataiku architecture, starting with the Design node, which is where we build our project.
To illustrate, we’ll describe how to use the Deployer to deploy:
A project to an Automation node for batch processing.
An API service to an API node for real-time scoring.
Tip
An API node isn’t the only deployment option for API services! However, it’s the simplest and so is our focus through most of the MLOps Practitioner learning path. See the reference documentation on Deploying to an external platform if you are interested in deploying to platforms like Amazon SageMaker, Azure ML, Google Vertex AI, Snowflake, or Databricks.
A project bundle for batch processing#
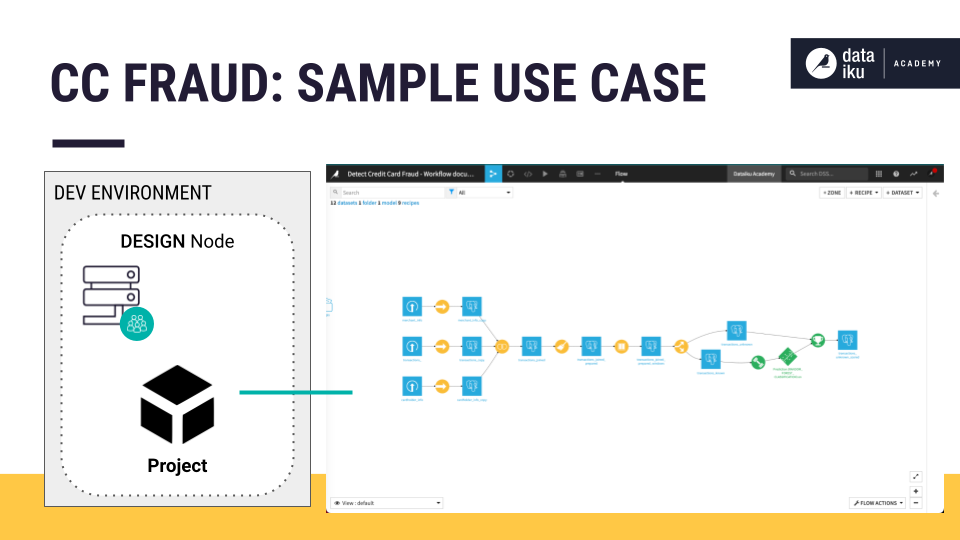
For a credit card fraud use case, we aim to batch process predictions of credit card transactions once per day. Our batch processing project lifecycle begins at the Design node.
The Design node is a shared development environment where we can collaboratively connect to, analyze, and prepare our data, creating data visualizations and prototypes. Having this sandbox allows us to fail without impacting projects and API services in production.
The Design node is also where we iteratively build our prediction model, set up metrics, data quality rules and/or checks, and create automation scenarios and dashboards.
For example, let’s say the business wants a daily dashboard showing where that day’s fraudulent transactions occurred according to the prediction model. We want to ensure the data used to create the dashboard passes quality checks before building the dashboard. One of our data quality rules might be to check for the number of unique merchant IDs or confirm the absence of new columns in the new, unknown transactions dataset.

After designing our workflow, we package our work as a project bundle. You can think of a bundle as a snapshot of the project that contains the configuration needed to reconstruct the tasks in the production environment. A bundle exports the project structure.
Once we create our bundle, we use the Deployer to deliver the project to a production environment. The Deployer is a node for deploying projects and API services. It can be set up as a standalone instance of Dataiku or as part of the Design or Automation node. We’ll use a specific Deployer component known as the Project Deployer for our batch processing use case.
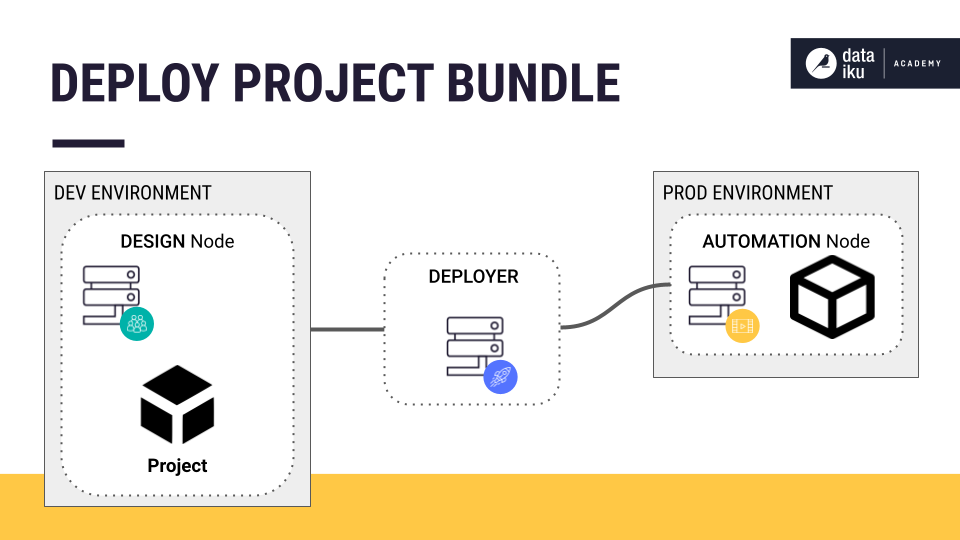
The Project Deployer deploys the bundle to the Automation node. The Automation node is an isolated environment for operationalizing batch-processed data or machine learning scoring and retraining. Redesigning still happens on the Design node, but the Automation node lets us execute data workflows in production, giving us tools to monitor performance and version different projects. The stable and isolated nature of the Automation node allows for repeatable, reliable, production-integrated processes.
Once we’ve deployed our project, we can start monitoring it. For example, the business can monitor the location of transactions predicted to be fraudulent from the previous days’ purchases using an interactive dashboard.
An API service for real-time scoring#
Dataiku’s architecture also supports another type of deployment: real-time scoring. Under a real-time scoring framework, we process our predictions in real-time. Our goal in this example is to flag potentially fraudulent credit card transactions as the bank receives them individually.
To start, we use the Design node to train our model. Then we create an API endpoint from the model we want to deploy. We package this endpoint in an API service using the API Designer. For our use case, our API endpoint will be the prediction model.
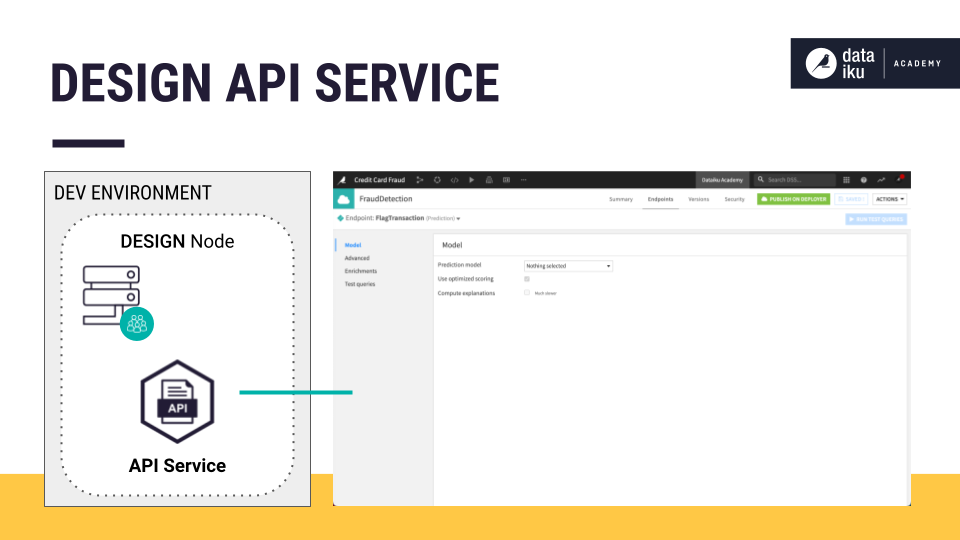
Once we run tests, we push a version of our API service to the Deployer. In the Deployer, we will be able to see that we have both Projects and API Services available for deployment.
To deploy our API service, we’ll be using another component of the Deployer known as the API Deployer. The API Deployer pushes our API service to the API node. The API node is a horizontally scalable and highly available web server. It operationalizes ML models and answers prediction requests.
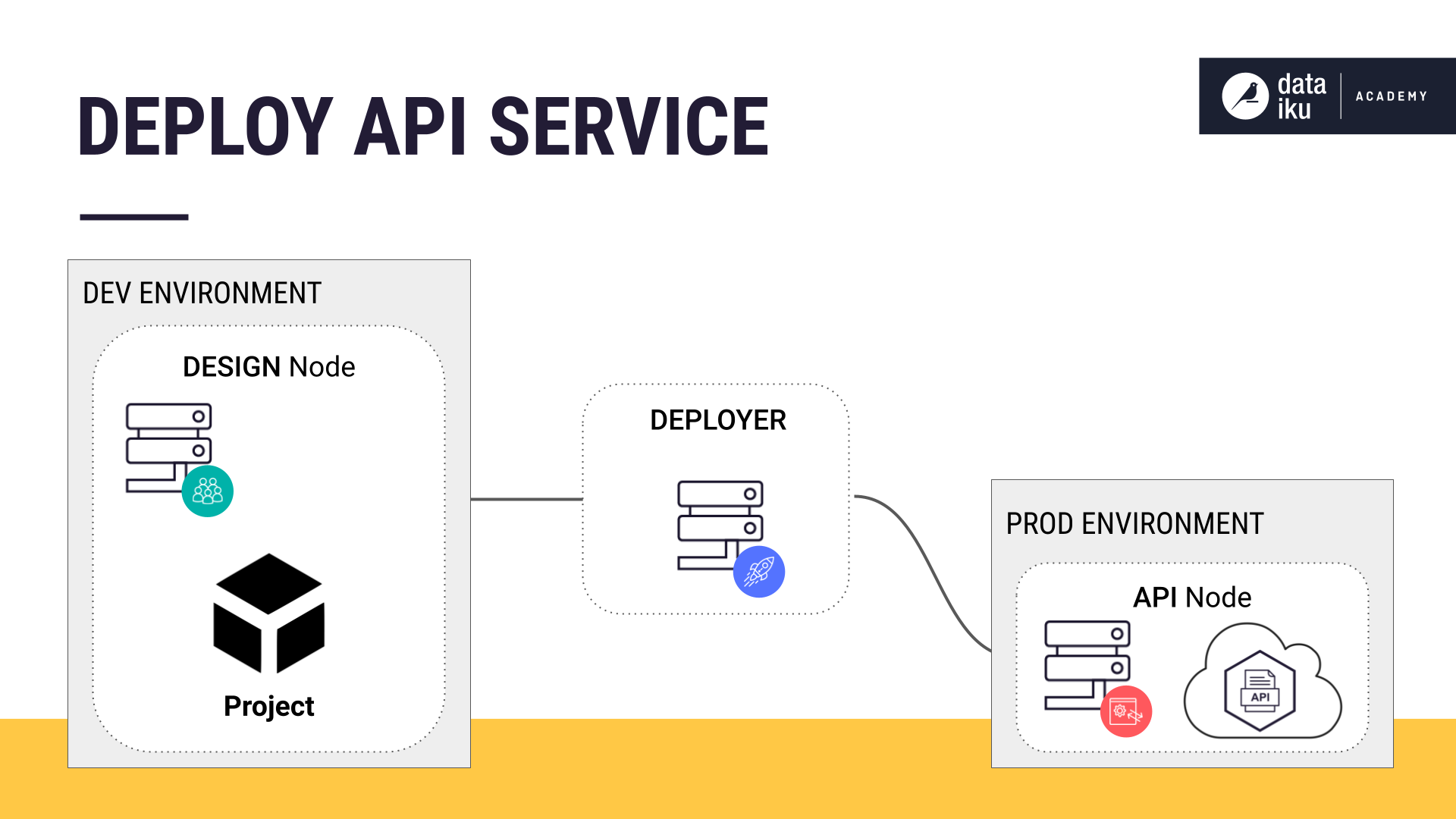
Once we’ve deployed our API service to the API node, we can monitor the real-time predictions.
Note
For the purpose of simplification, the MLOps Practitioner learning path focuses primarily on deploying models created with Dataiku’s visual ML tool. However, Dataiku also supports deployment of many other types of models, such as MLflow Models or External Models.
Summary#
In summary, Dataiku is an end-to-end platform where analysts not only design, but also operationalize projects and models.
The architecture of Dataiku allows you to deploy models and gives you the ability to monitor and maintain models and redeploy them.
In addition, Dataiku supplies tools to perform monitoring tasks, such as tracking model quality or pipeline health.
Important
One additional node that extends these capabilities even further is Dataiku Govern. Learn more in the AI Governance Specialist learning path.
See also
Learn more about batch and real-time deployment in the reference documentation on Production deployments and bundles and API Node & API Deployer: Real-time APIs, respectively.
Works Cited
Mark Treveil and the Dataiku team. Introducing MLOps: How to Scale Machine Learning in the Enterprise. O’Reilly, 2020.