
Concept | Model packaging for deployment#
Consider that you’ve designed a machine learning model and deployed the active version to the Flow. Next, you’ll need to package the model for deployment to production.
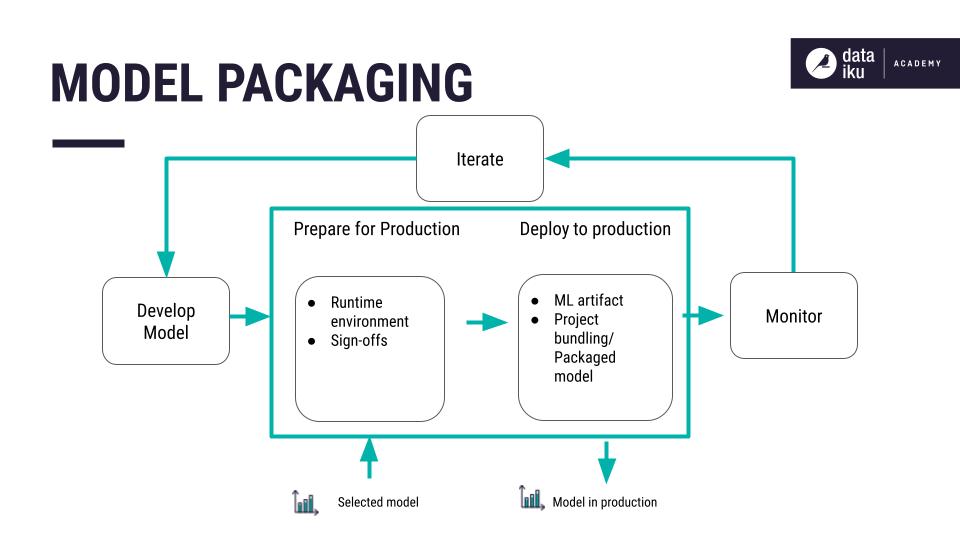
Challenges of creating a model package#
When deploying a model to production, you’re not only deploying code. You’re deploying a model package. The components of a model package, such as the model and the datasets used to train it, can have dependencies that need to be available at runtime.
By having the dependencies available at runtime, you can ensure that the model predictions made in the development environment are replicable in the production environment. Problems can arise when the versions of these dependencies are different between the development and production environments.
Important
Dataiku refers to the model package as a saved model. However, ML practitioners might also refer to it as a model artifact.
Typical package components#
Once the code and artifacts are stored in a centralized repository, you can build a testable and deployable bundle of the project.
A model package includes the following components:
Documented code for implementing the model including its preprocessing
Hyperparameters and their configuration
Training and validation data
Data for testing scenarios
The trained model, in its runnable form
A code environment including libraries with specific versions and environment variables
In Dataiku, a green diamond icon in the Flow represents the model package.
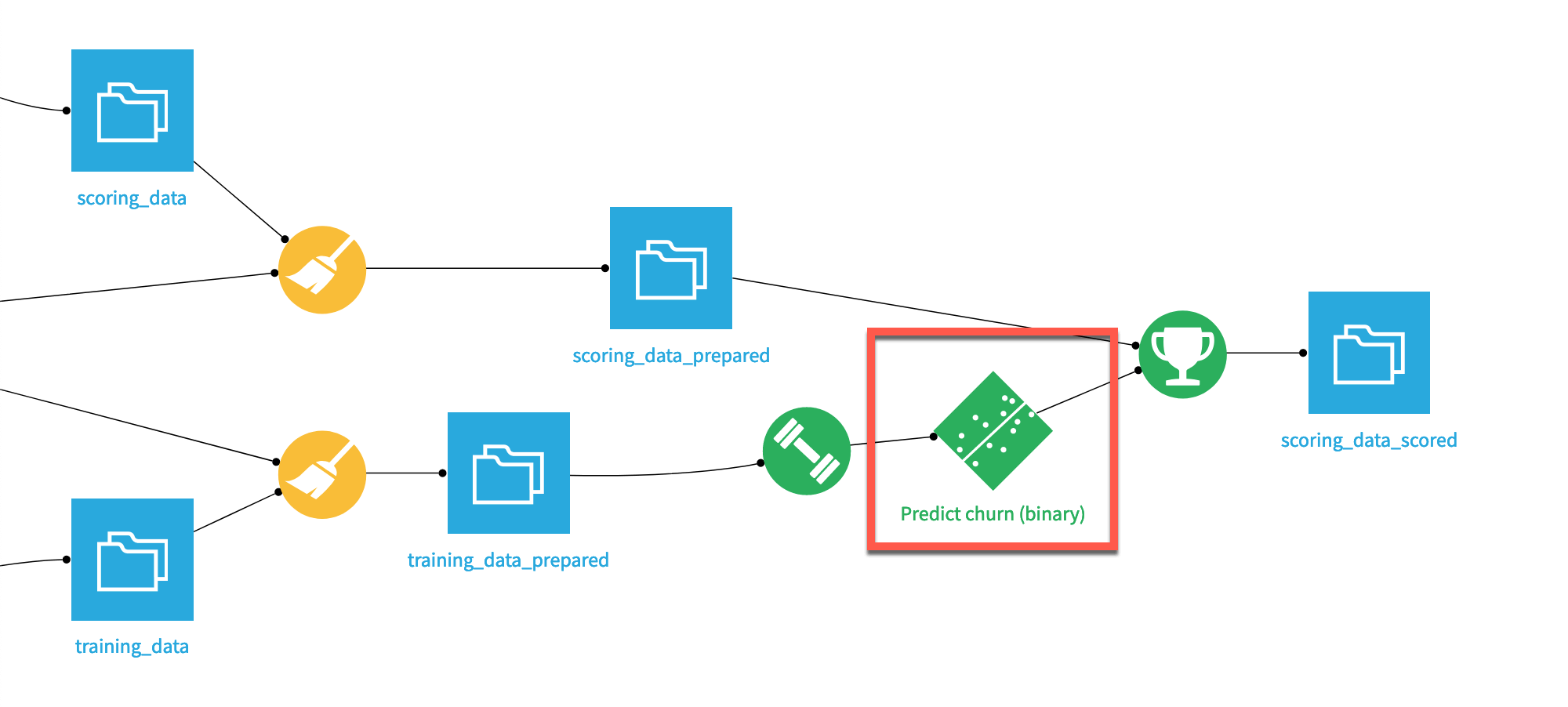
Important
A model package isn’t the same as a project bundle. A project bundle contains metadata of a saved model (and other objects). To learn more, visit Creating a bundle in the reference documentation.
To view the active model’s components (the trained model and its metadata), double click on the saved model in the Flow, and select the active version.
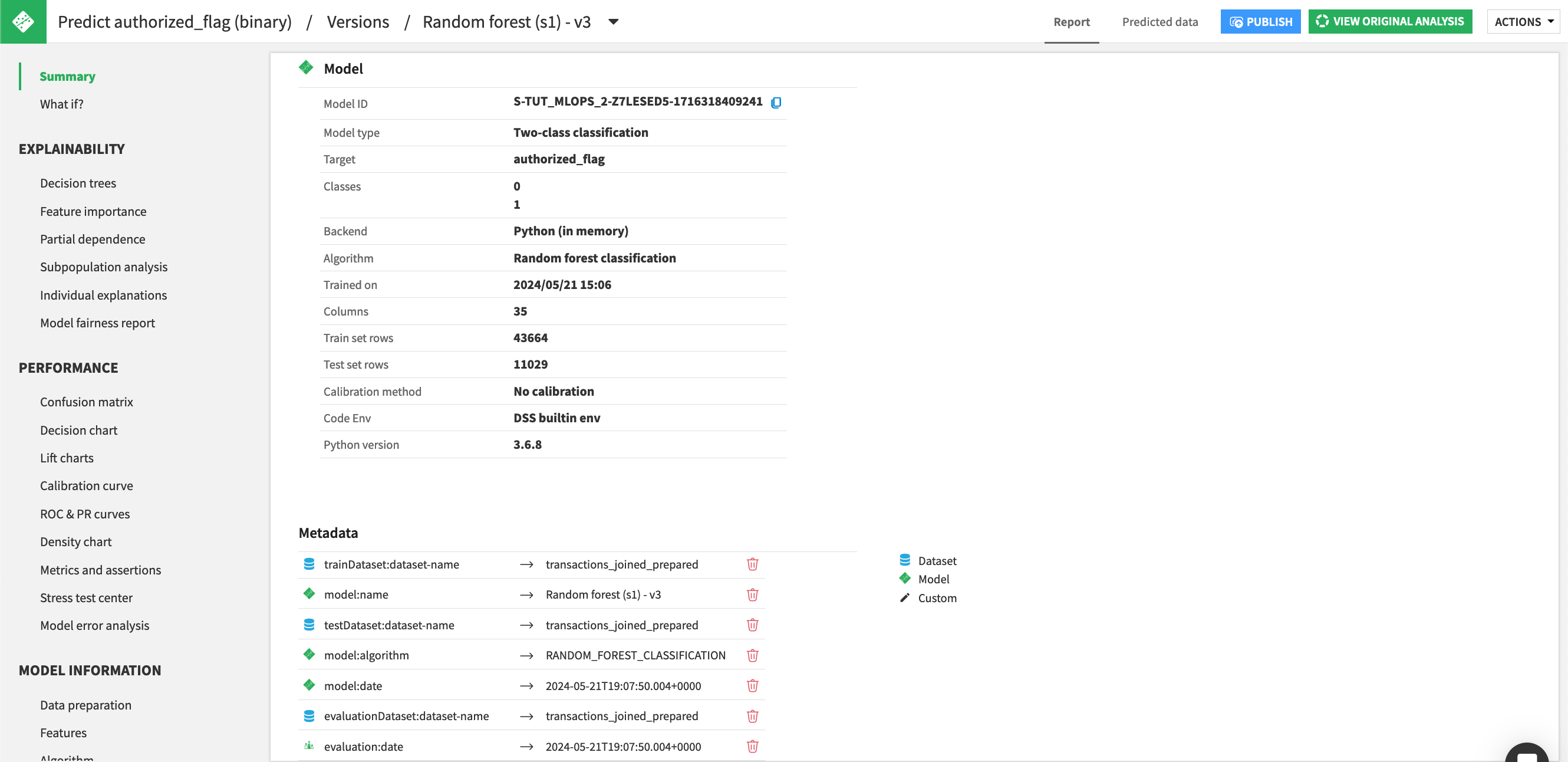
See also
If you are unfamiliar with saved models, see the ML Practitioner learning path.
Works Cited
Mark Treveil and the Dataiku team. Introducing MLOps: How to Scale Machine Learning in the Enterprise. O’Reilly, 2020.