
Concept | Jobs with partitioned datasets#
Watch the video or skip to the summary below.

When we build a Flow with partitioned datasets, we’re deciding what we want to build, and then Dataiku decides what to run to fulfill our request.
Partition dependencies#
To tell Dataiku what we want to build, we configure the following elements:
The input identifier
The target identifier
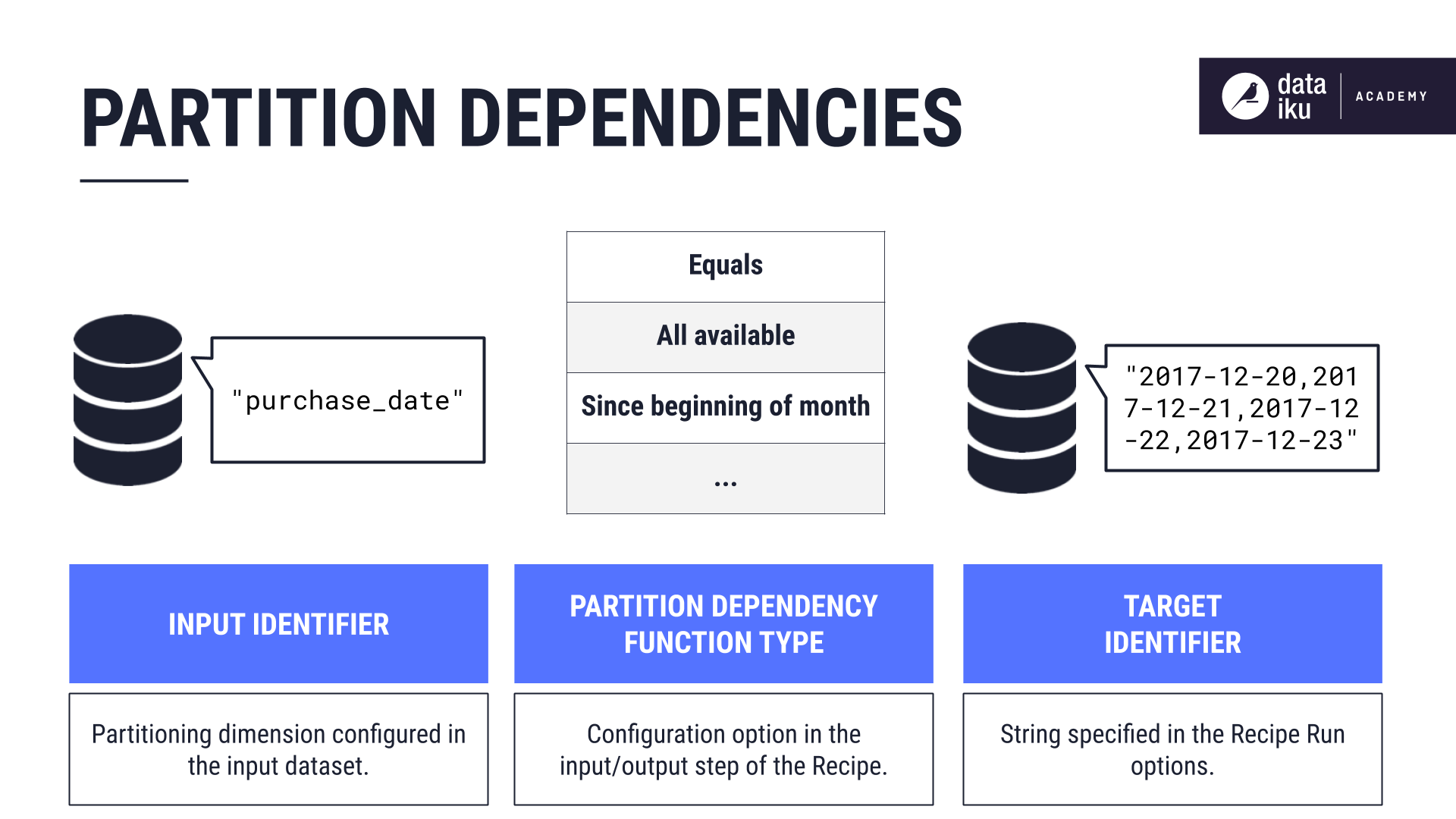
Let’s look at a few ways we could configure partition dependencies.
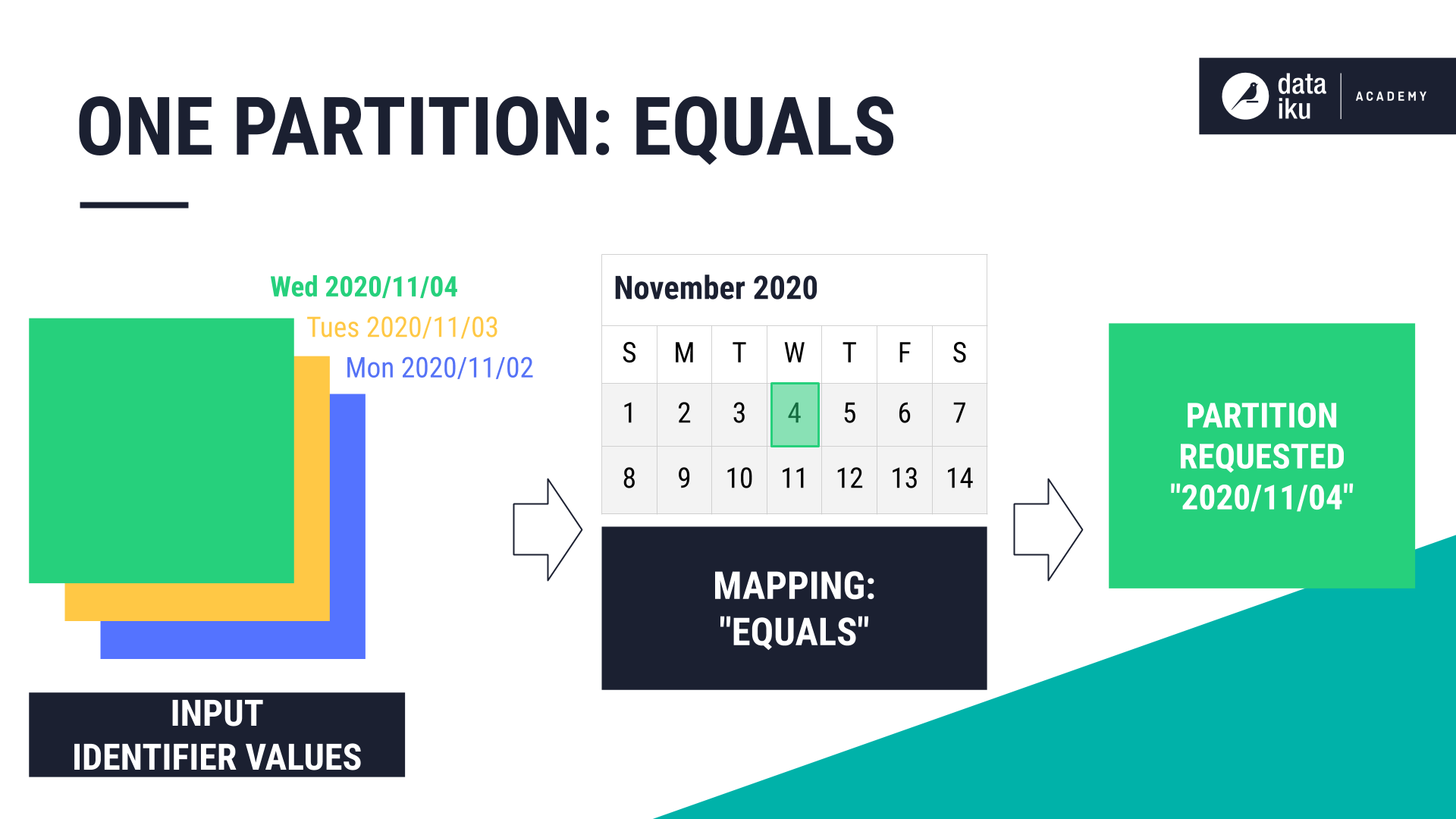
Time-based dimension: Function type “Equals”#
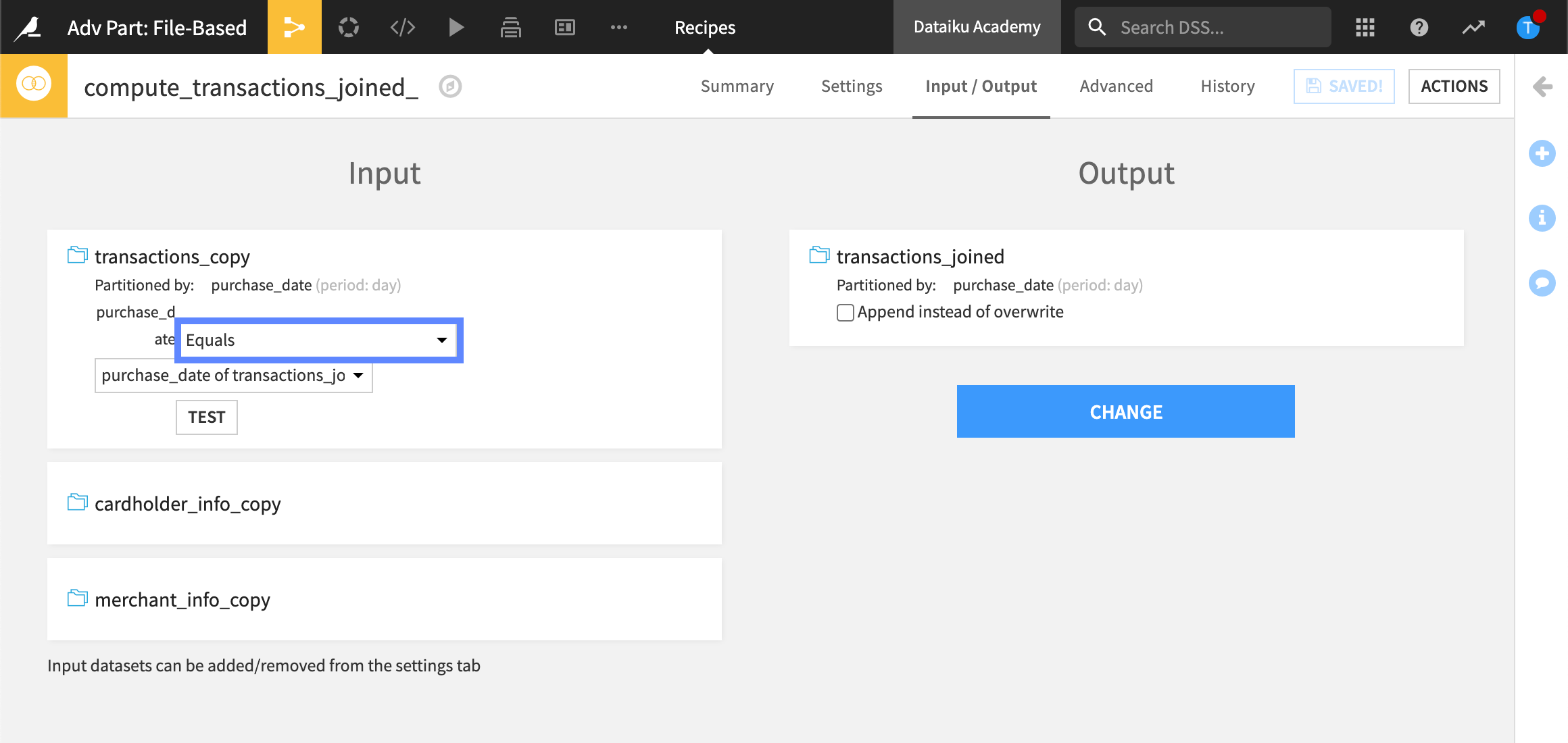
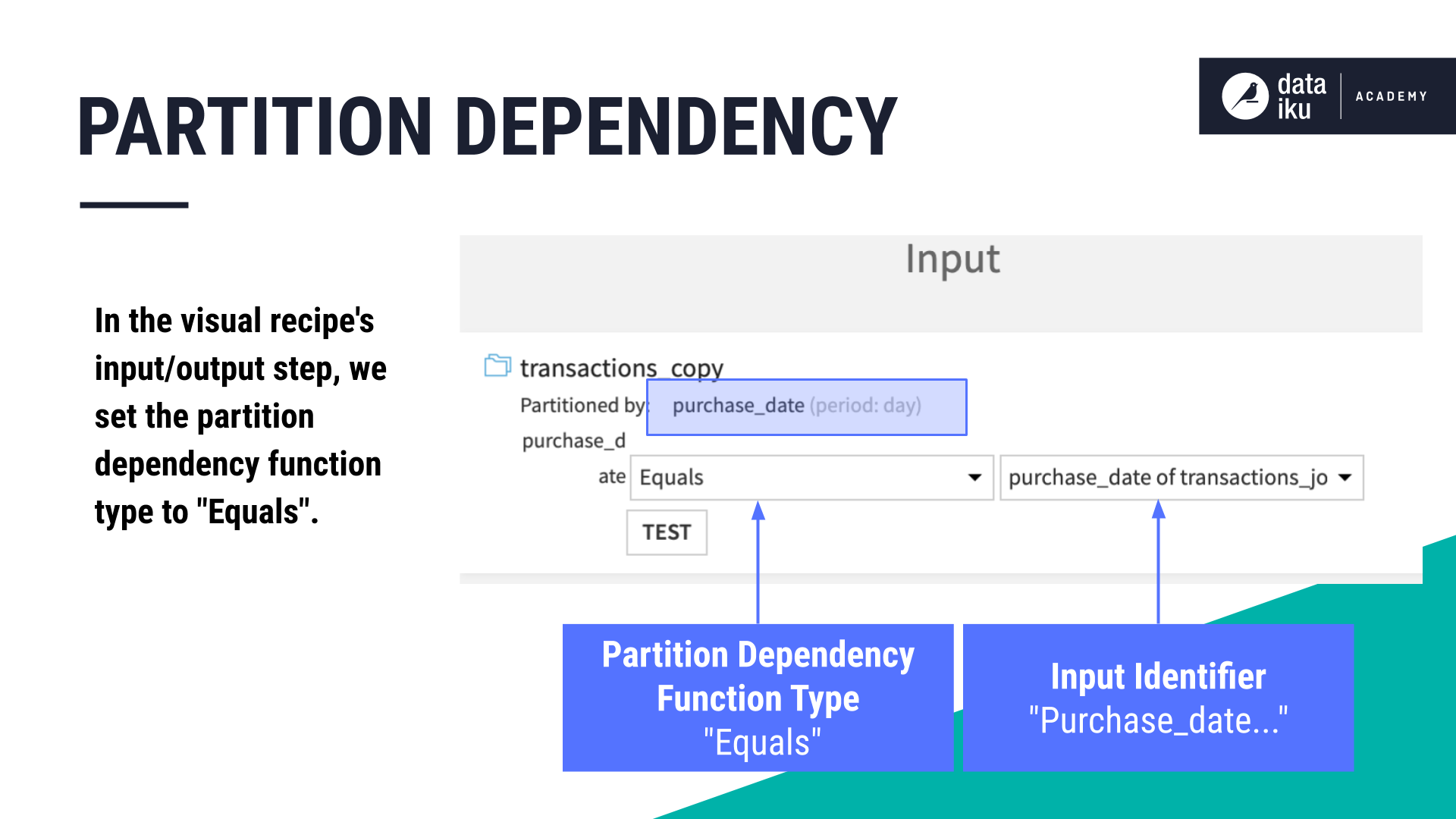
In this example, our input dataset is partitioned by Day using the column, purchase_date. Our goal is to build an output dataset made up of specific partitions using the Join recipe.
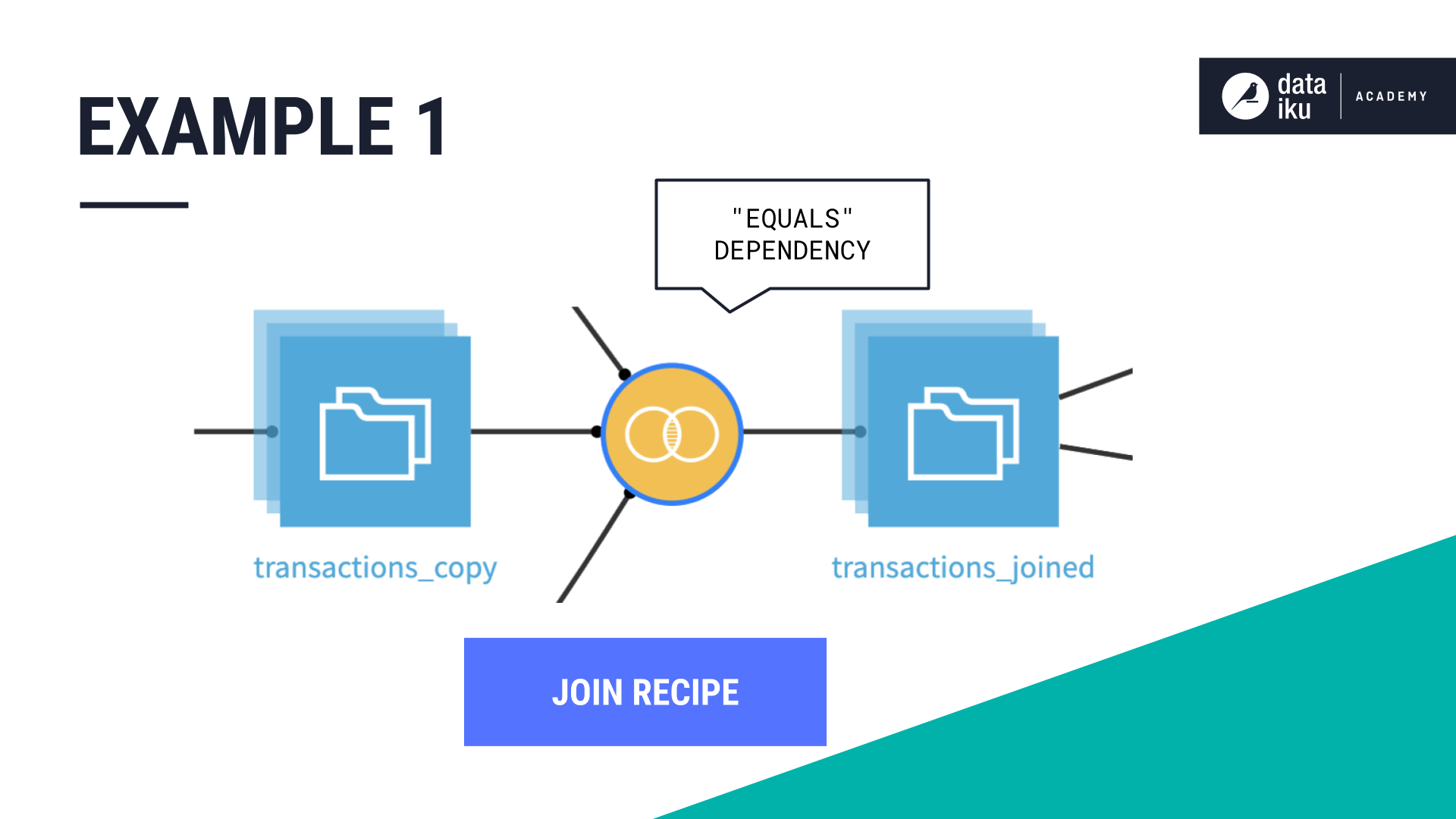
Our partition dependency function type is Equals because we want Dataiku to compute the target partition using the same partition identifier value, Day, as the input partition.
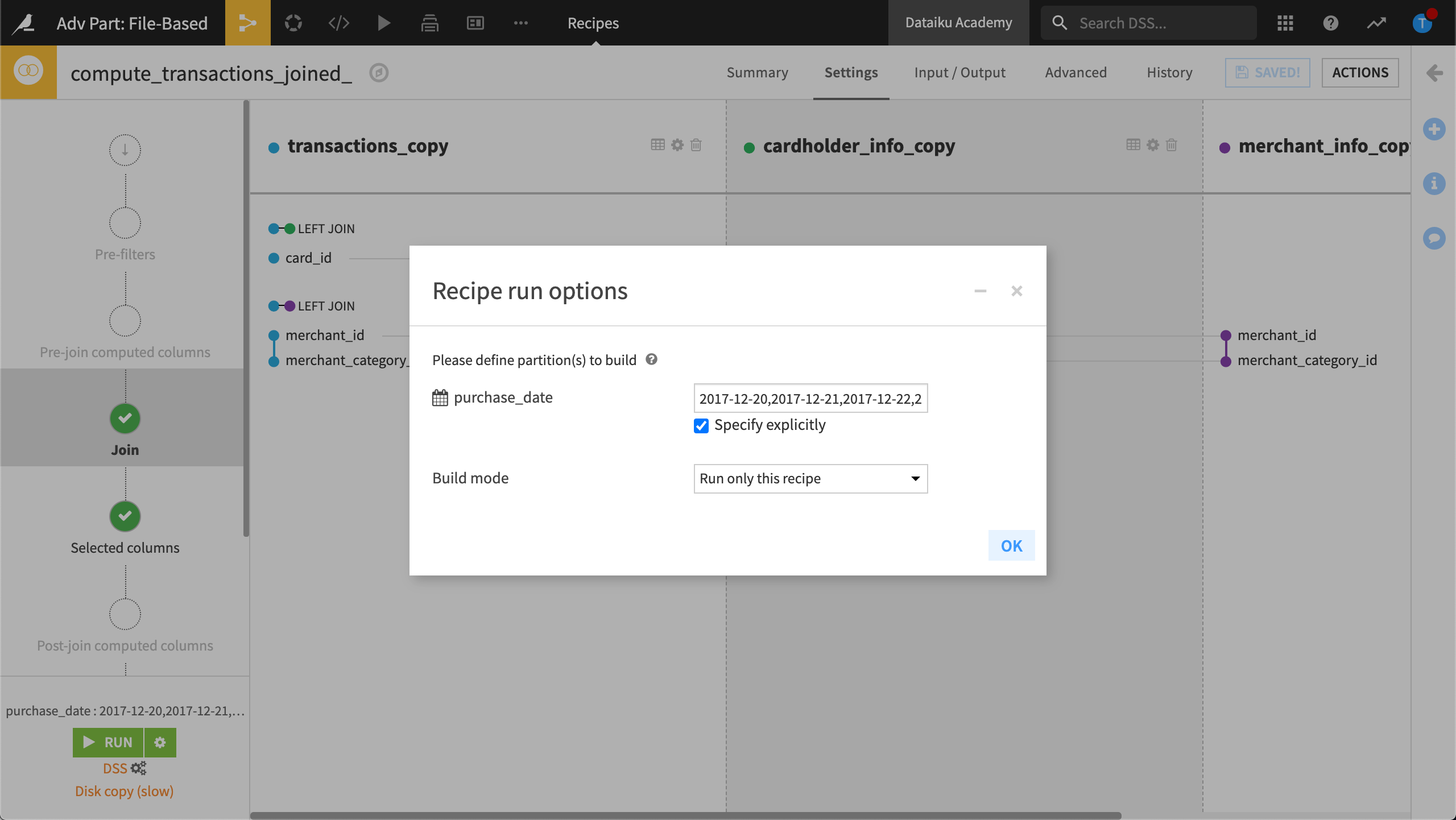
In addition, we want to build only specific partitions. Our target identifier is a string, 2017-12-20,2017-12-21,2017-12-22,2017-12-23, identifying the “days” we want to build.
Time-based dimension: Function type “Since the Beginning of the Month”#
In this example, we’re again using a Join recipe to build a dataset using the purchase_date dimension.
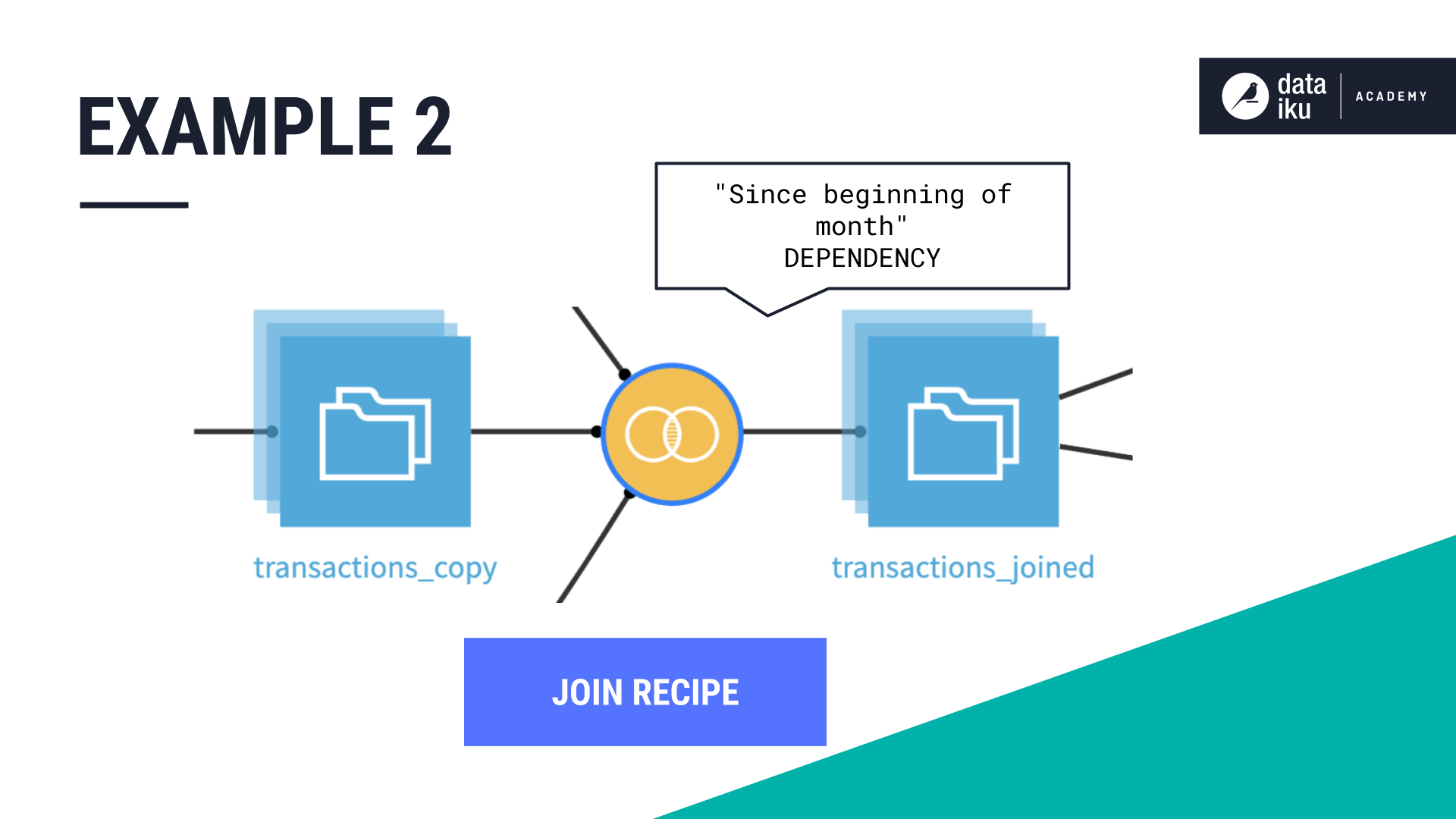
This time, we want the output dataset to contain all the partitions “Since beginning of month.”
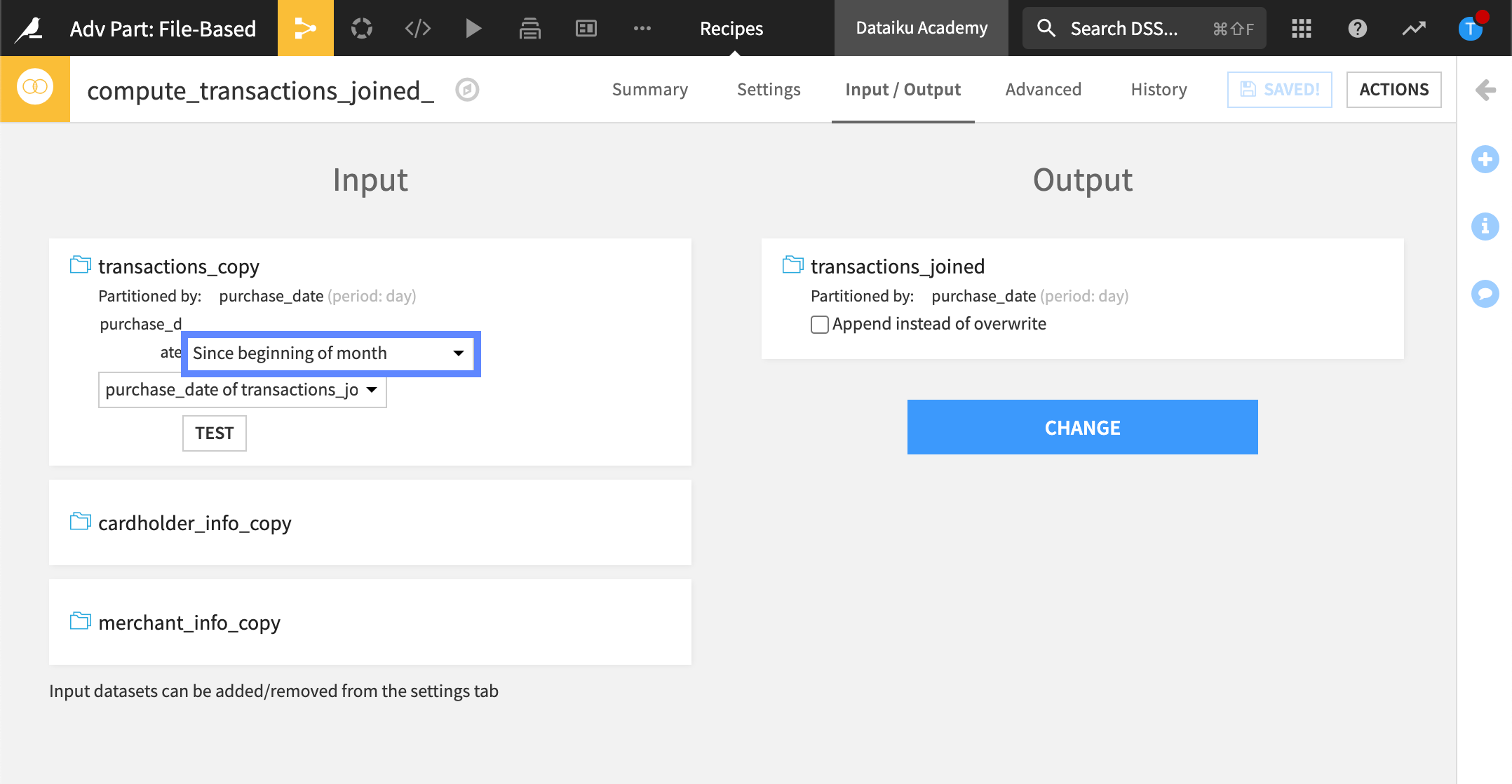
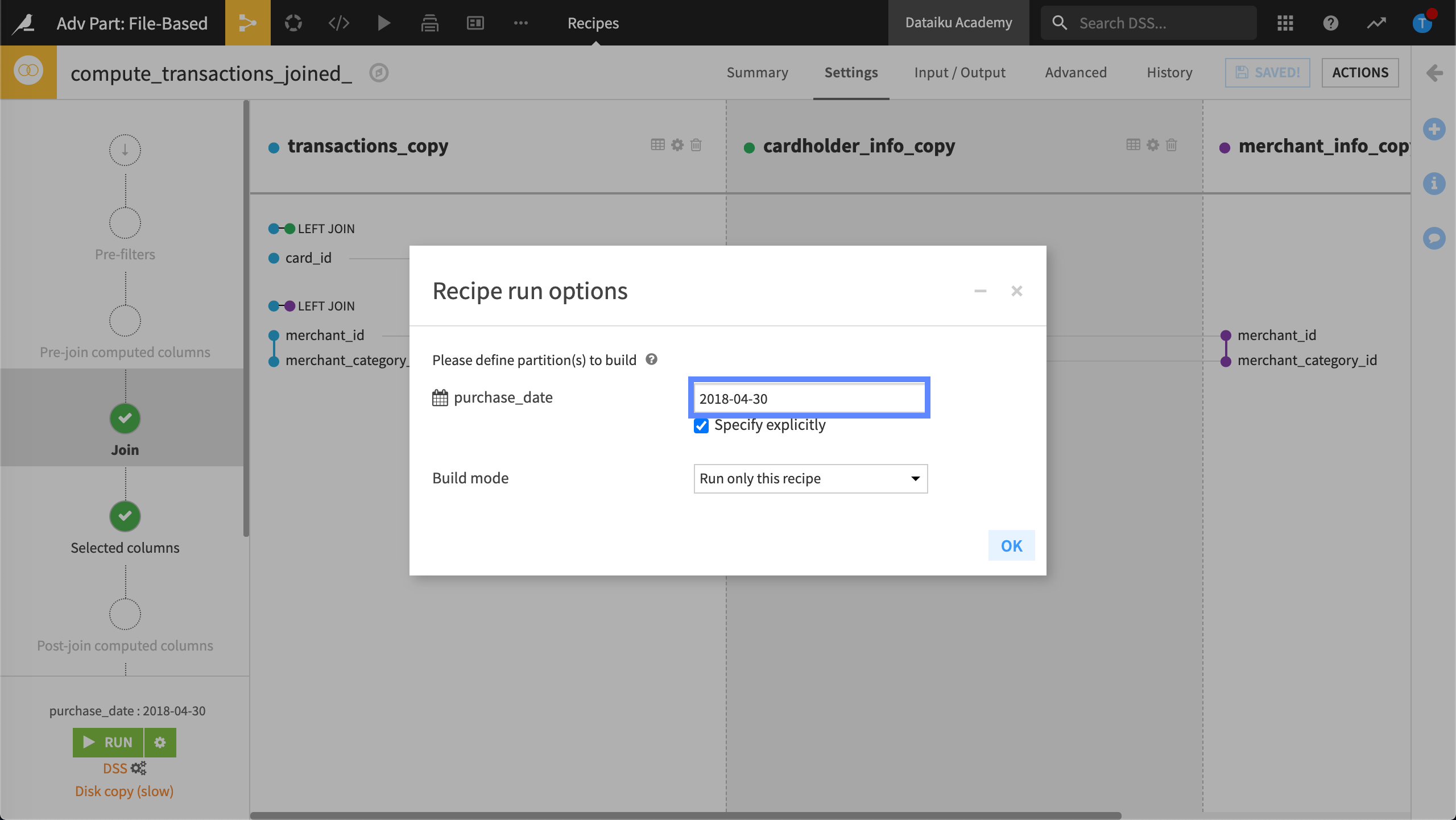
In addition, we’ve targeted a specific date, 2018-04-30.
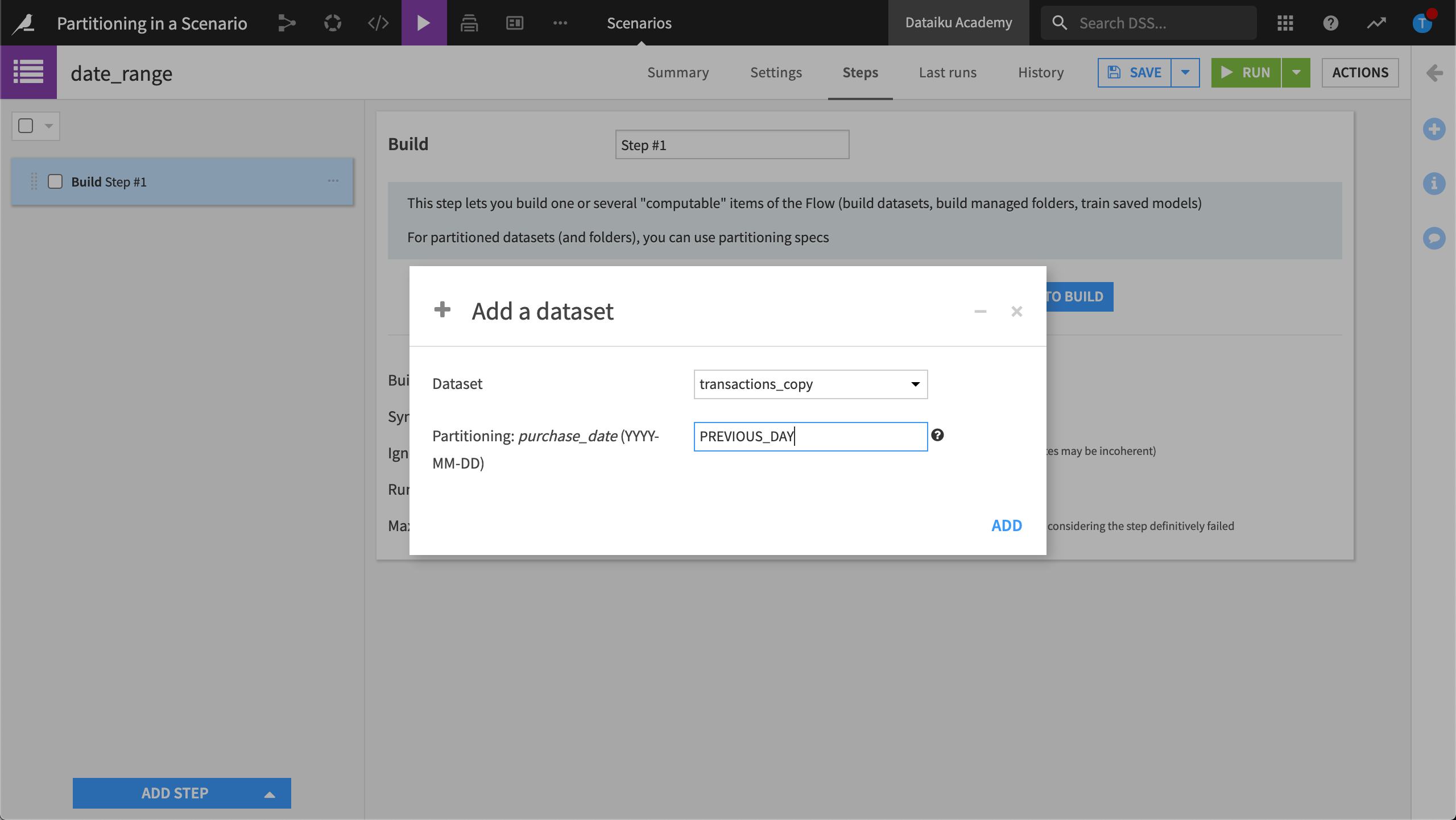
We could also use a scenario to configure the target identifier using a keyword, such as PREVIOUS_DAY.
Discrete-based dimension: Function type “Equals”#
In this example, we’re using the Window recipe to build a dataset using the merchant_subsector_description dimension.
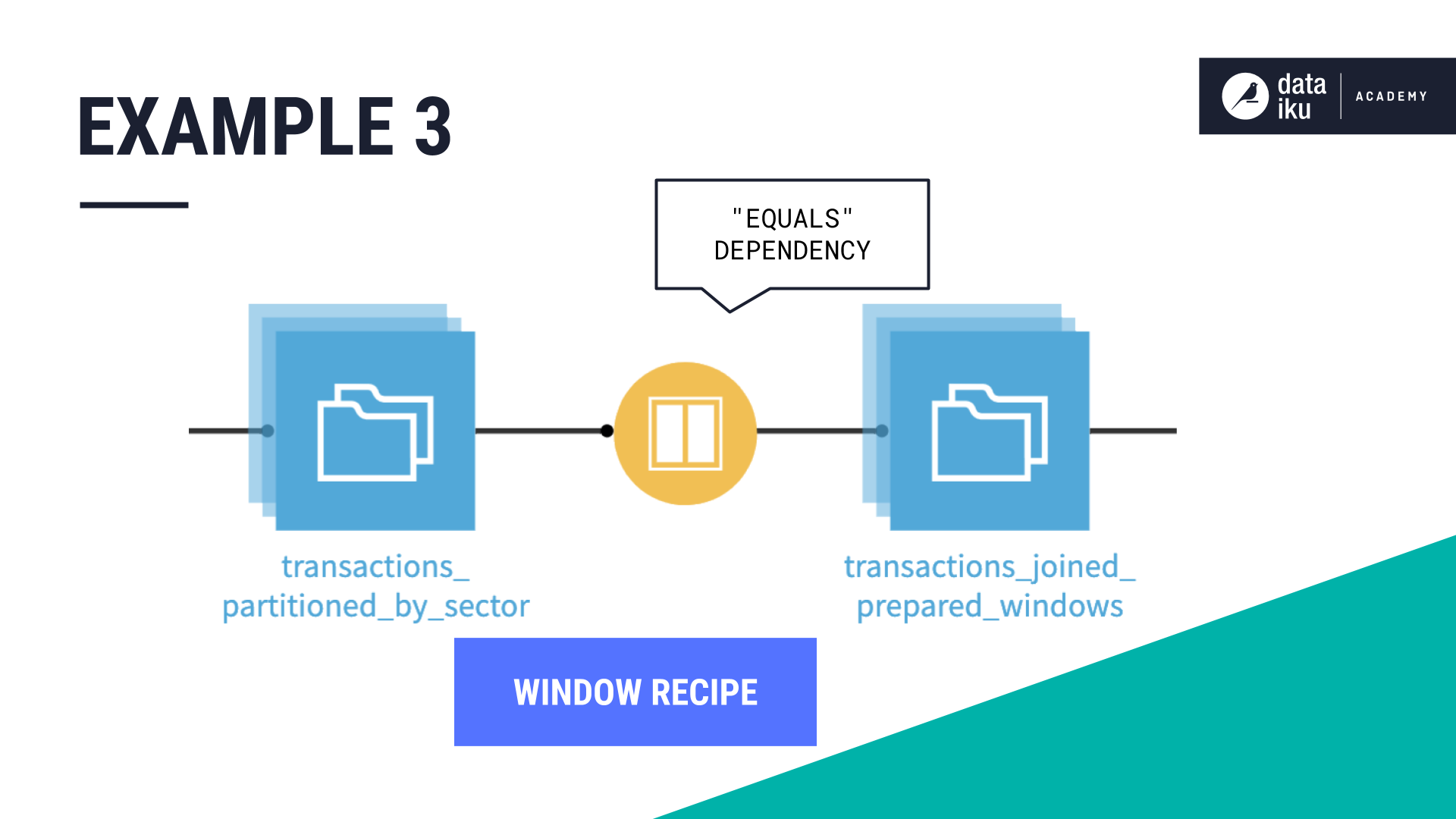
Our partition dependency function type is Equals because we want Dataiku to compute the target partition using the same partition identifier value, merchant_subsector_description, as the input partition.
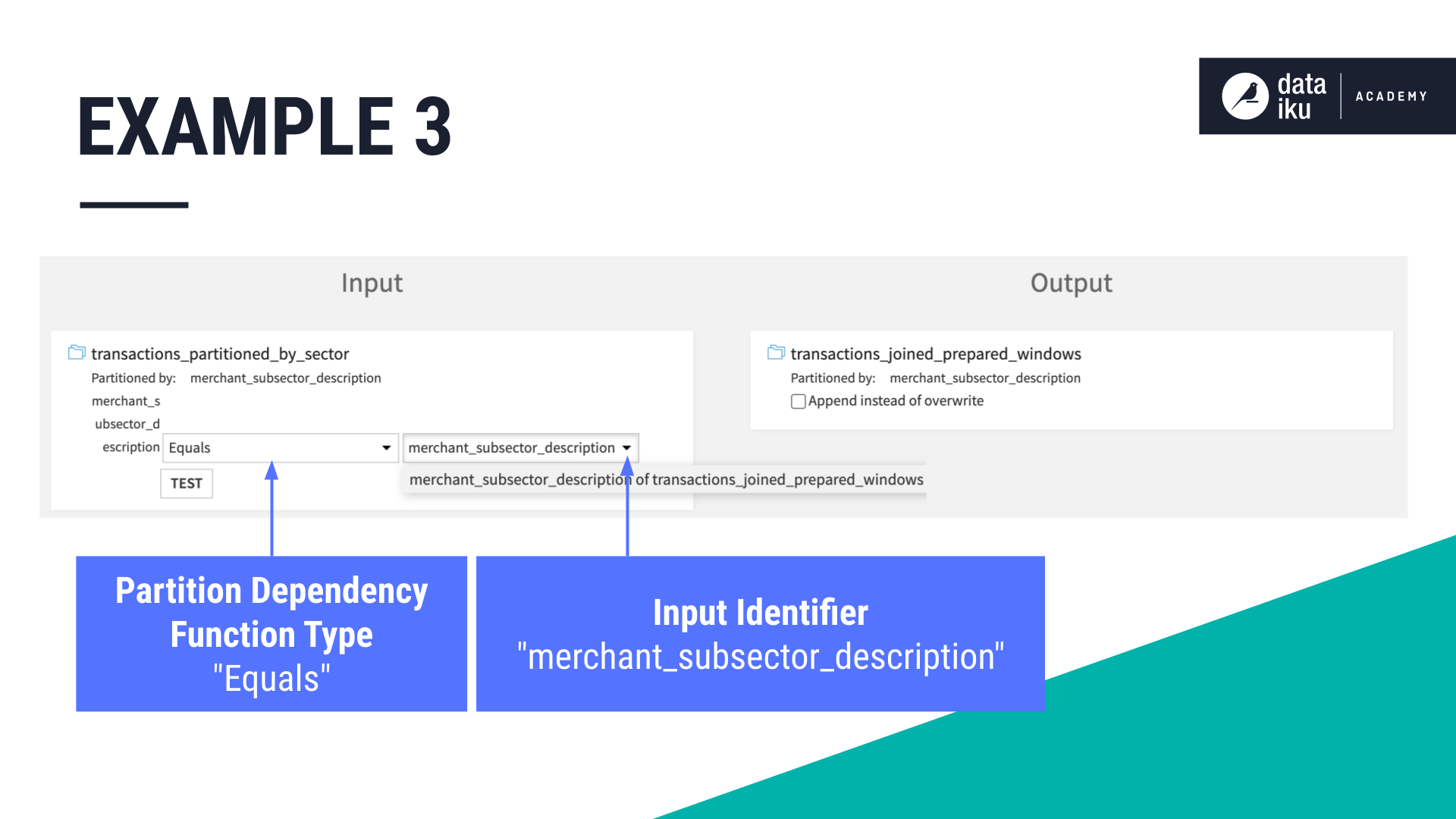
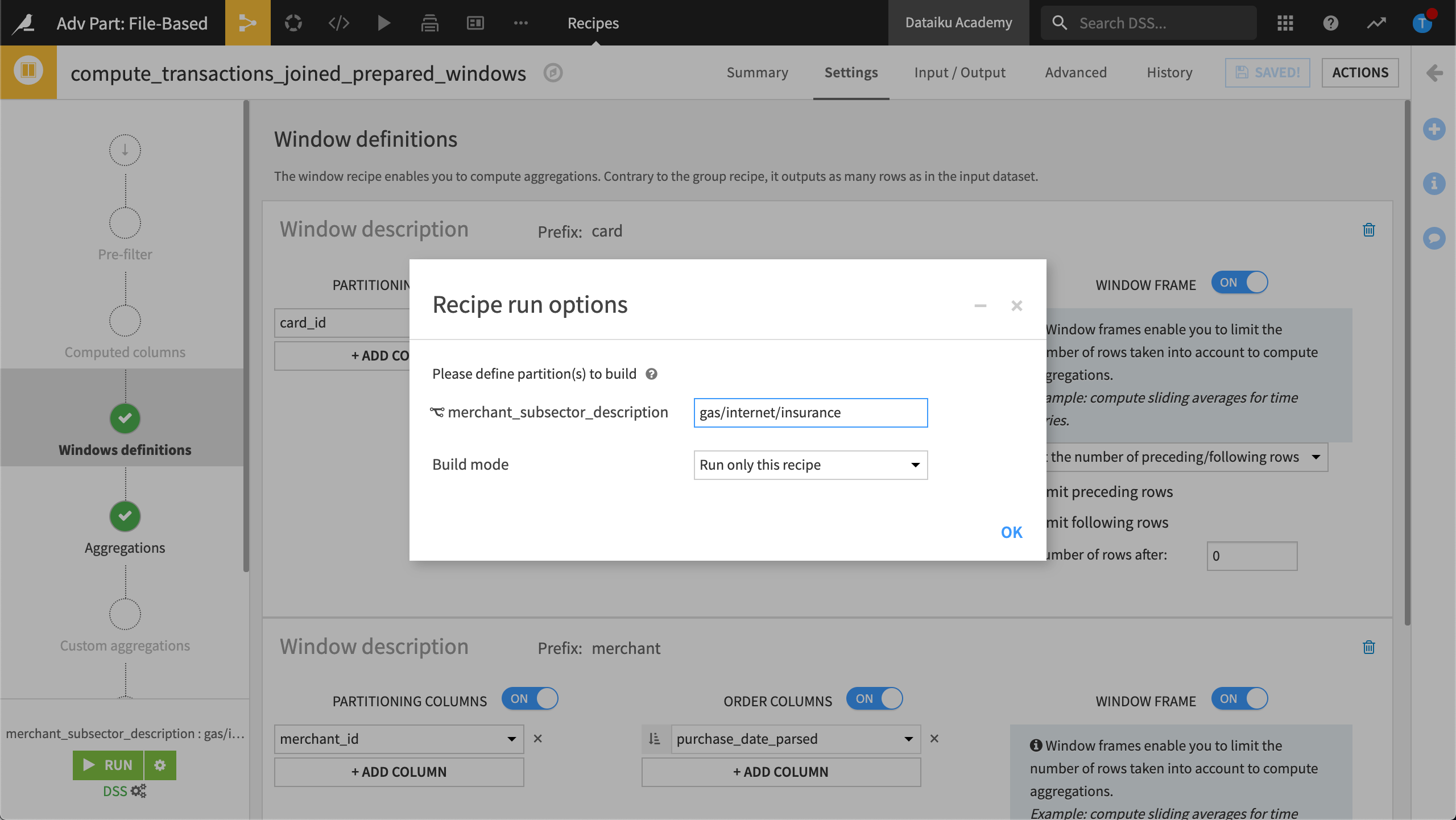
In addition, we’ve targeted specific partitions, gas/internet/insurance.
In these examples, we specified what we want to build by configuring the partition dependencies.
Let’s look at three examples to demonstrate how a partitioned job runs.
Job behavior and activities#
Request one partition from three input partitions: Function type “Equals”#
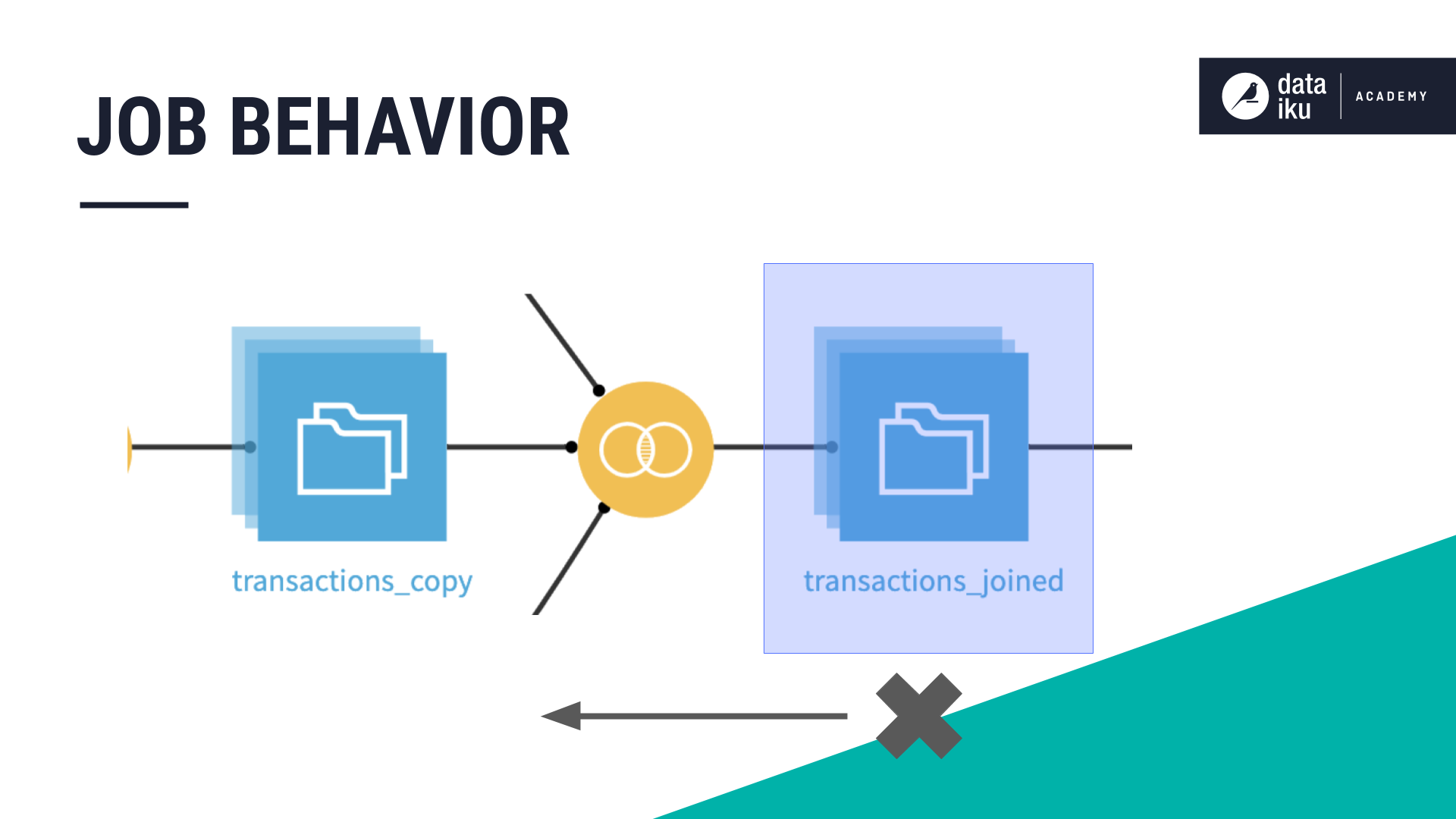
In this example, our input dataset contains three partitions. We’re requesting one output partition. To build the requested partition, Dataiku runs one activity. A job can have more than one activity, and an activity is the run of a recipe on a specific partition.
We’ve selected Equals as the partition dependency function type. The dimension is already defined because there is only one partition dimension in the input dataset to choose from. If our input dataset was partitioned by more than one dimension, Dataiku would display more than one input identifier option.
In the Recipe Run options, we’ll specify the target identifier, 2020-11-04, before running the recipe.
Before Dataiku can run the job, it does the following:
It starts with the dataset that needs to be built.
It then looks at which recipe is upstream to gather the partition dependency information.
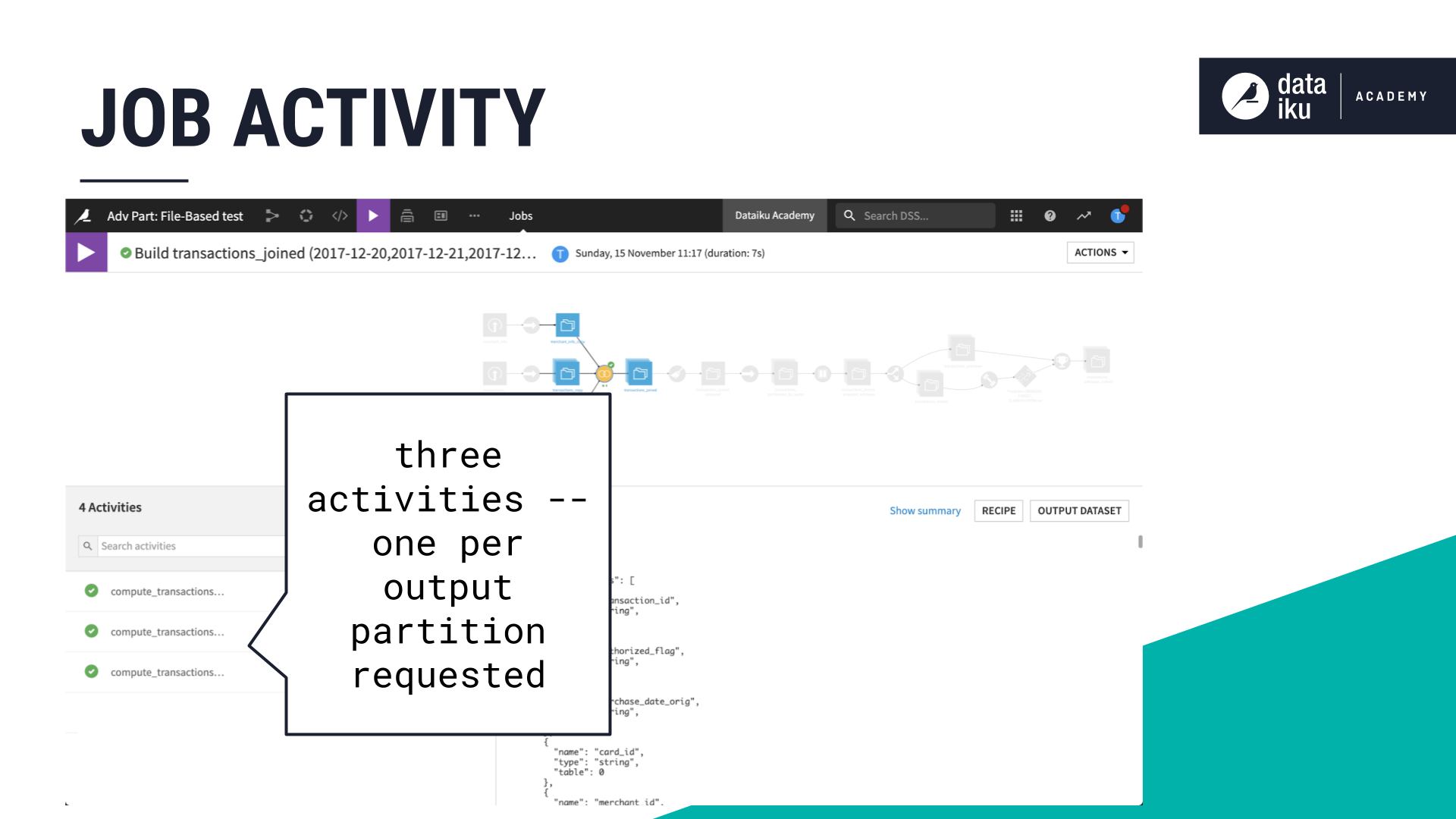
Once Dataiku computes the partition dependencies, it can then build the Flow. Since we requested to build one partition, there is one activity.

Request three partitions from three input partitions: Function type “Equals”#
If we were to request three partitions, instead of one, using Equals, with the same three input partitions, Dataiku would run three activities–one per partition–to build three partitions.
Request one partition from several input partitions: Function type “Since Beginning of Month”#
To use an example with a different type of mapping, let’s say we want to request one partition, using Since beginning of month. Using 2020-11-04 as the requested partition gives us four total input partitions.
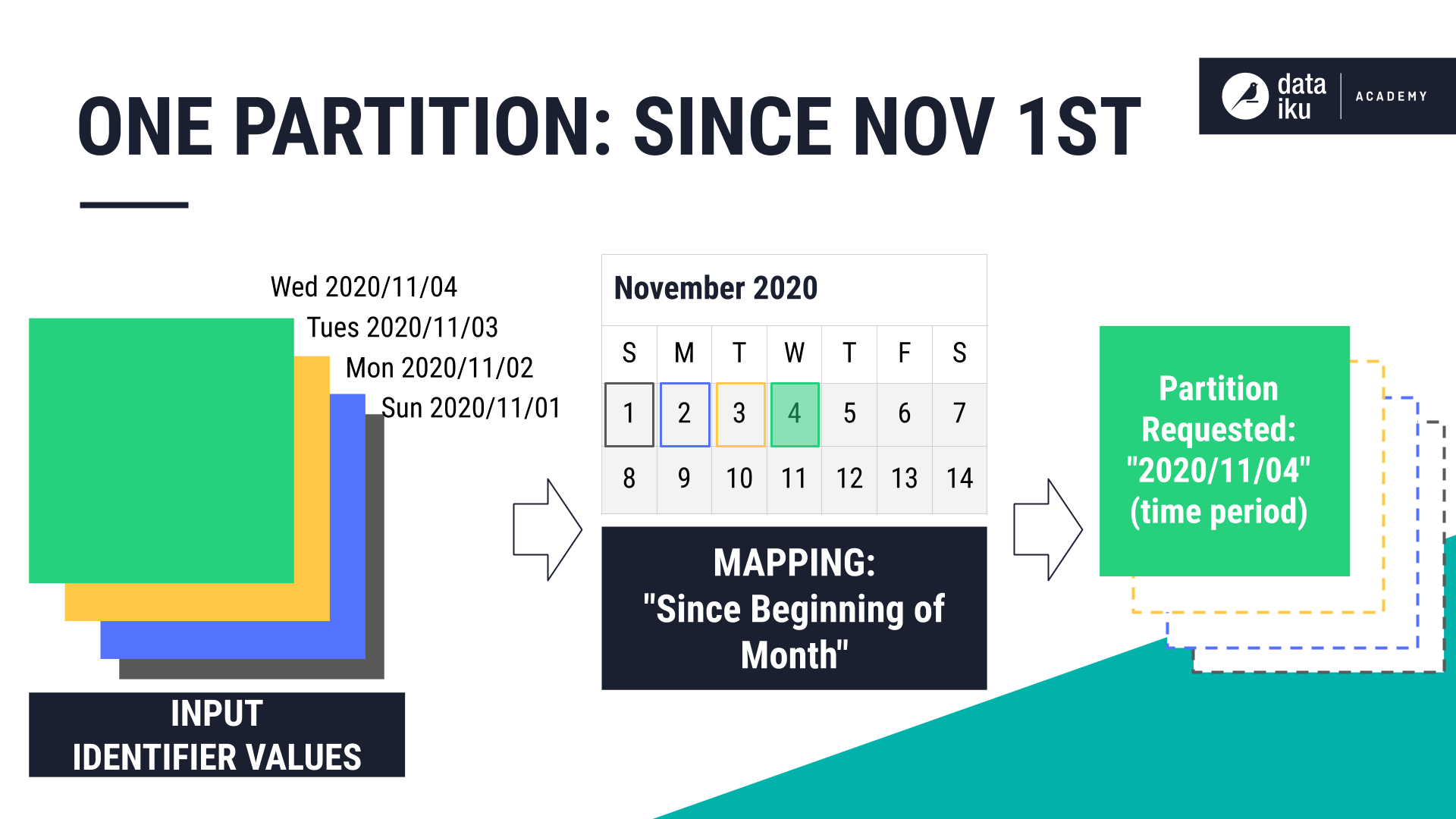
To build this job, Dataiku runs one activity to build one output partition that combines the four input partitions.
Even if there were 30 upstream partitions, Dataiku would still only generate a single, downstream partition with this particular mapping.
Building a Flow with multiple partitioned datasets#
Let’s consider how Dataiku might build a Flow where we have four datasets and three recipes.
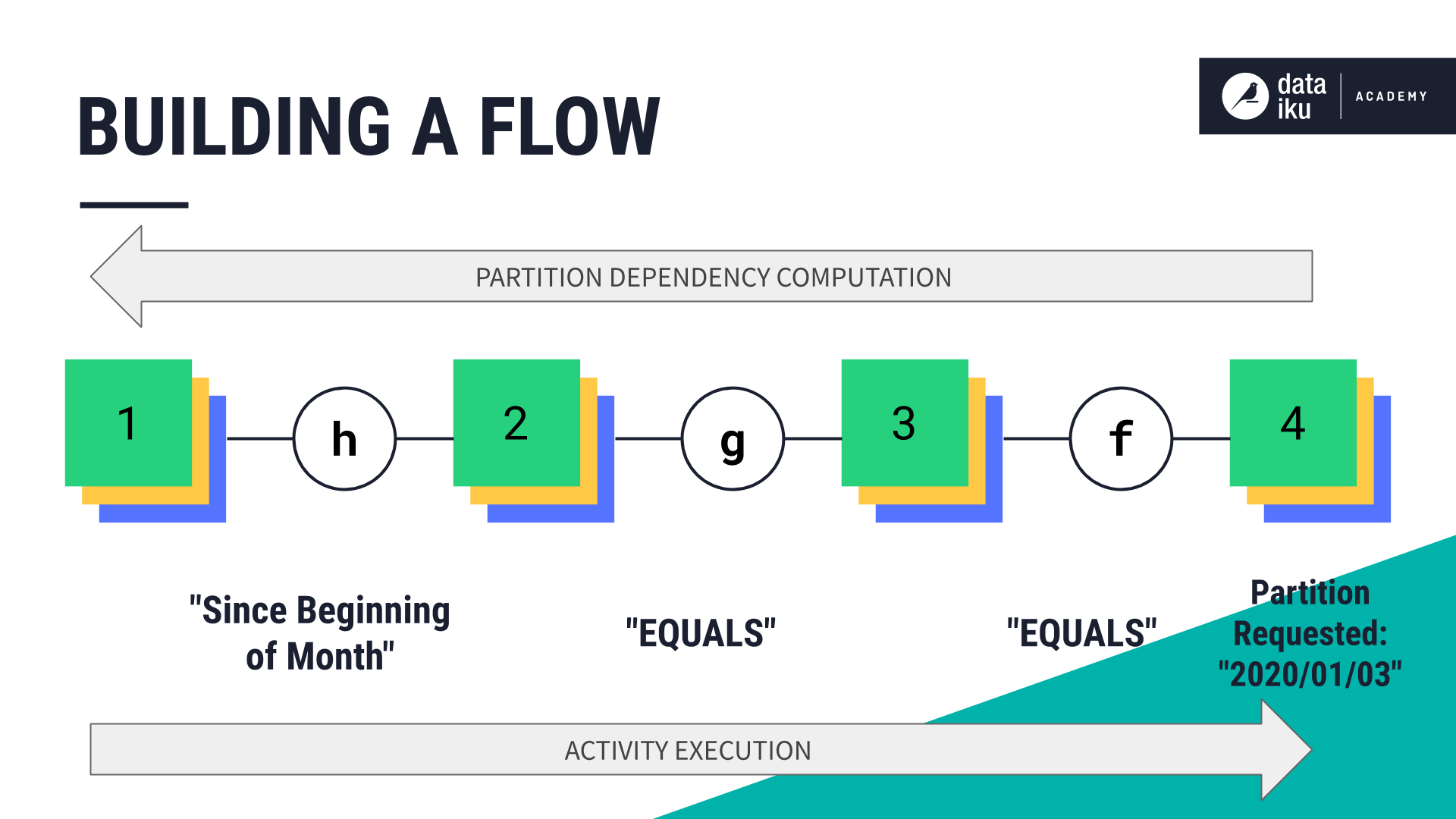
Each dataset in our Flow is partitioned by day. In this diagram, recipes are represented by letters of the alphabet while datasets are numbered. The goal is to build the partition “2020-01-03” in the last dataset in the Flow.
To do this, Dataiku starts from the last dataset and works backwards to compute the partition dependencies. For example, since recipe \(f\) is upstream of the final partition to be built, its partition dependencies are computed first.
Once all the partition dependencies are computed, the job activities begin using a “forward” execution in the Flow. Starting with the second dataset, the first job activity builds the partitions needed to build the partition requested, which, in turn, builds an output dataset that’s needed downstream.
A third job activity builds the partitions needed to build the output of recipe \(f\).
Exploring a Flow with multiple partitioned datasets#
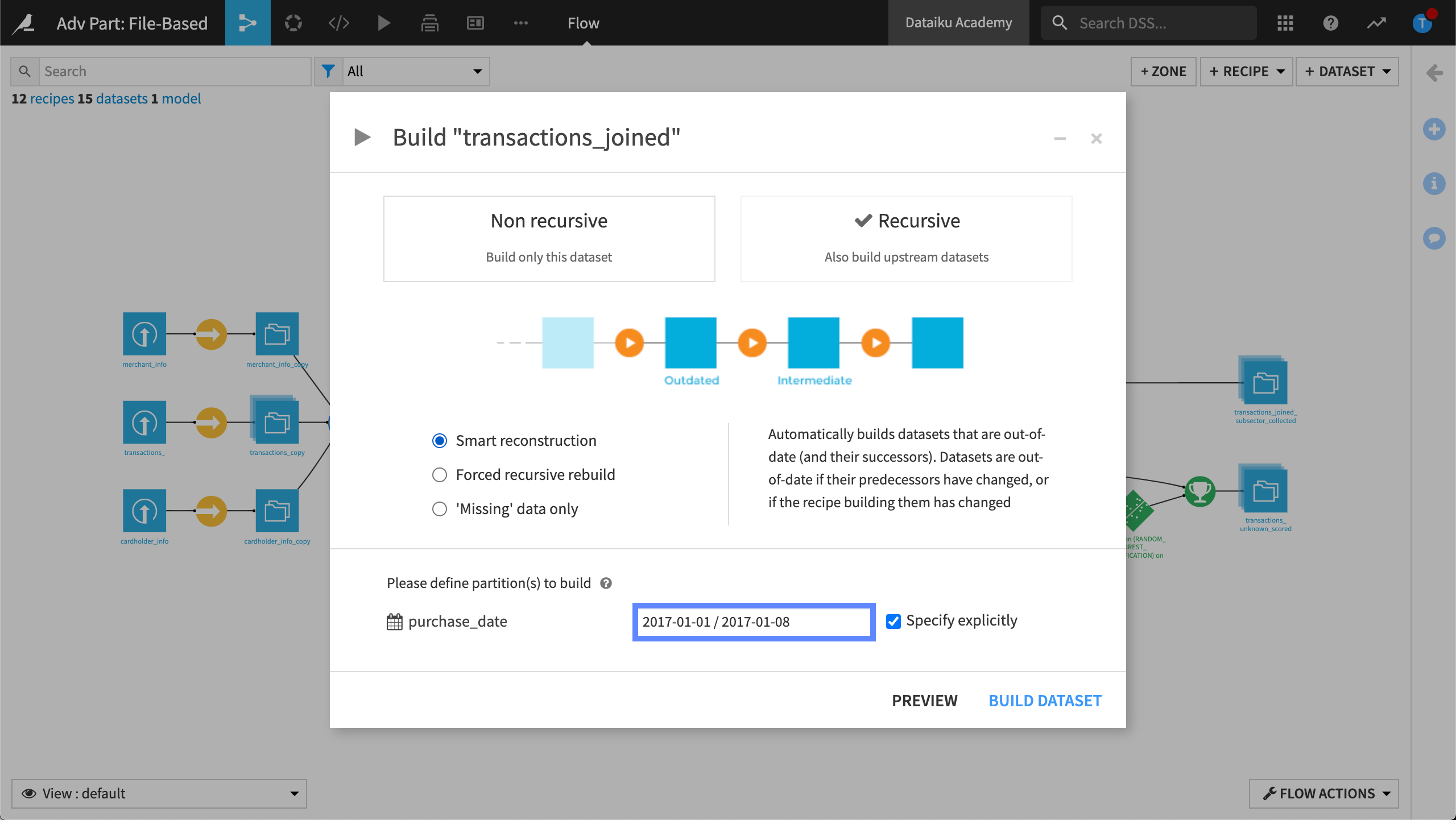
Build configuration#
When we select to build a dataset in the Flow or run a recipe, Dataiku displays the build configuration. We can choose between a non-recursive or a recursive job–the behavior remains the same. The difference is that Dataiku is asking us to select the partition or partitions we want to work with. This is similar to the option displayed in a visual recipe’s configuration window.
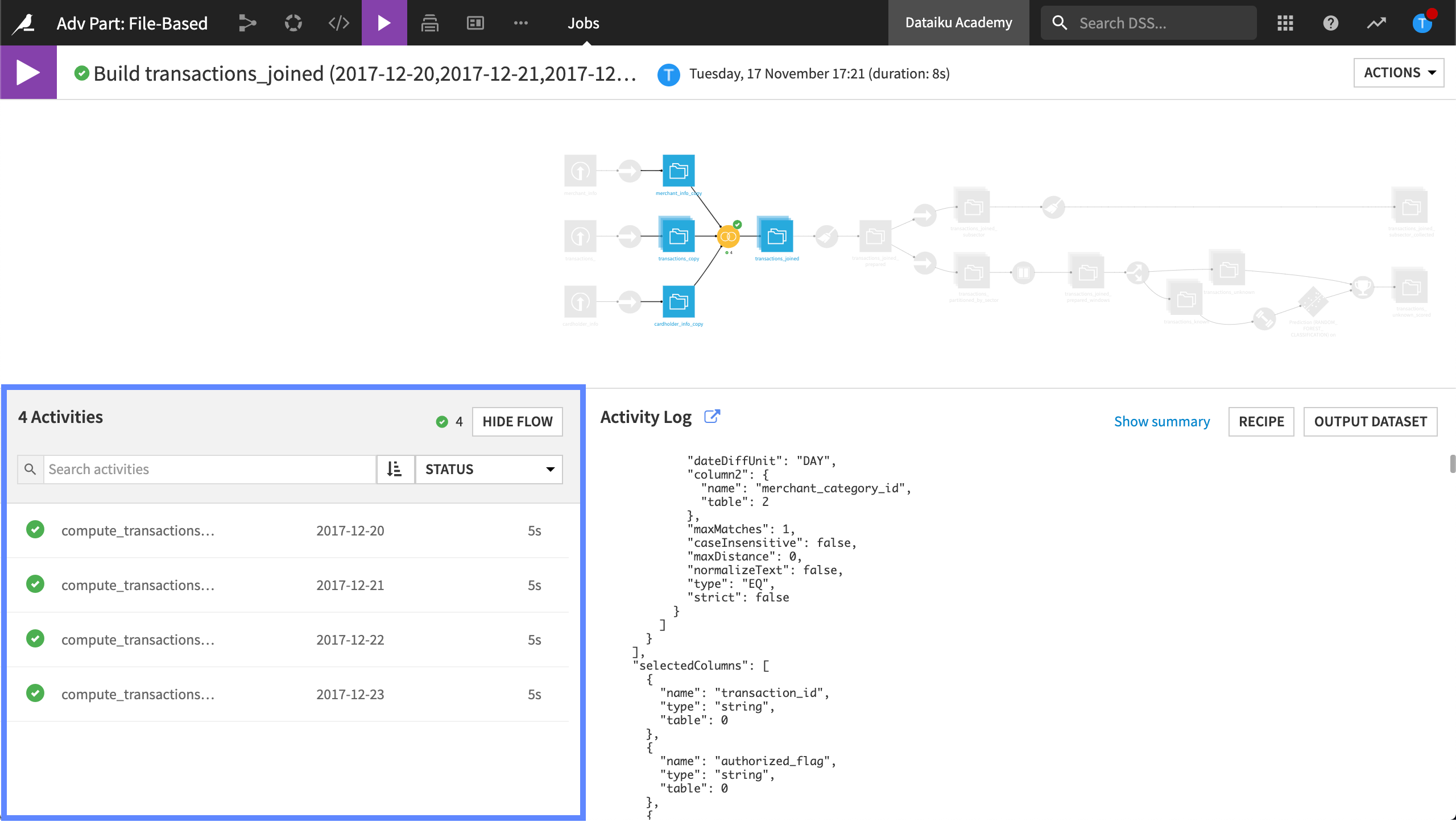
When we view a partitioned job, we can see the activities. Each activity informs us about the partition it was building.
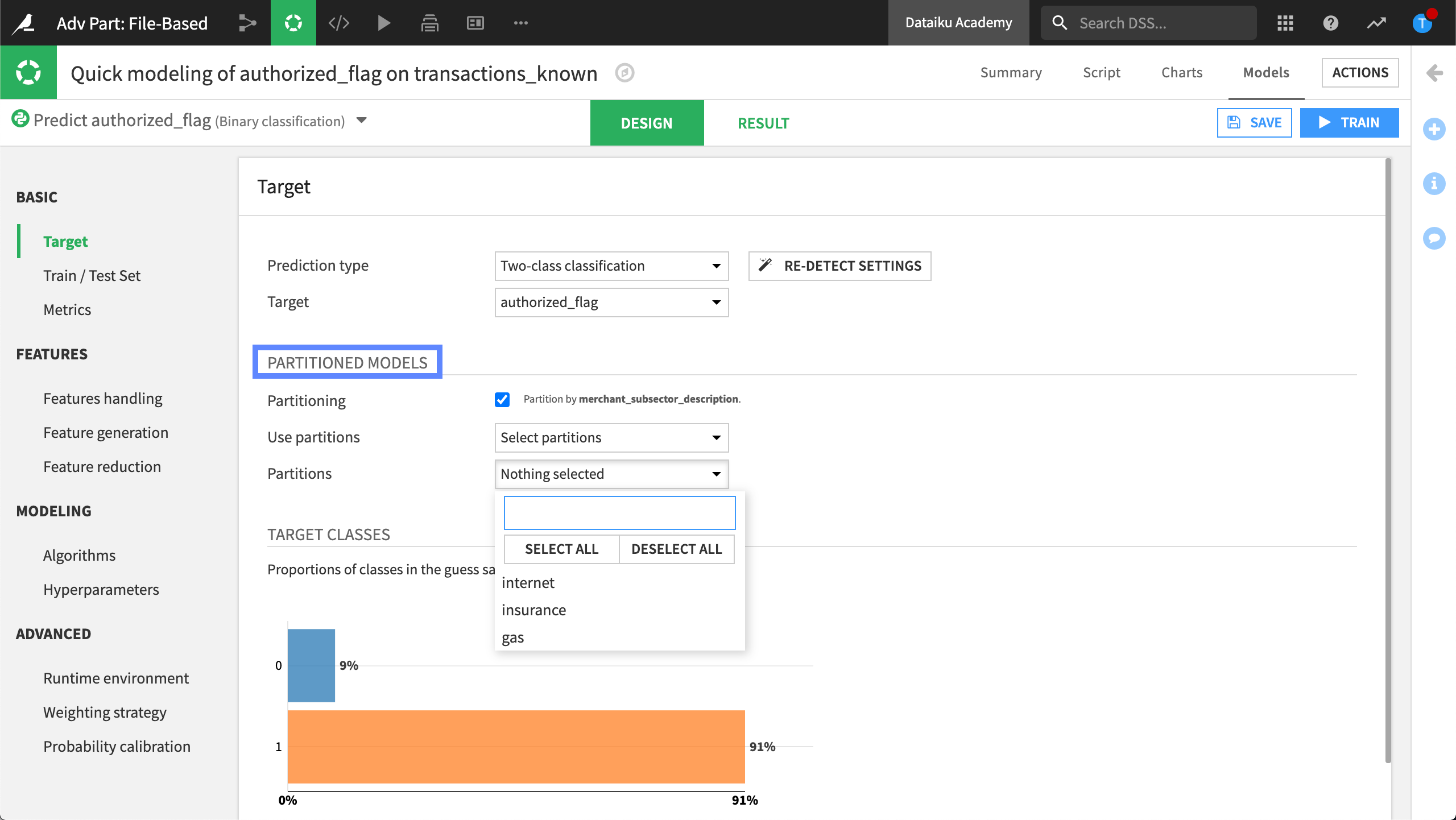
Build a partitioned model#
When building a machine learning model, we can use the target panel of the design pane to tell Dataiku to use a partitioned dataset. Using this feature, we can train our machine learning models on a specific partition of the dataset.
In addition, using the Train/Test Set Panel of the Design Pane, we can subsample the set on which the splitting will be performed. Using this feature, we can decide to use all partitions or a specific partition.
Next steps#
Visit the Dataiku reference documentation to find out more about working with partitions, including partition identifiers, and partition dependencies. For examples of ways to use keywords, visit Variables in scenarios.