
Concept | Partition redispatch and collection#
Watch the video
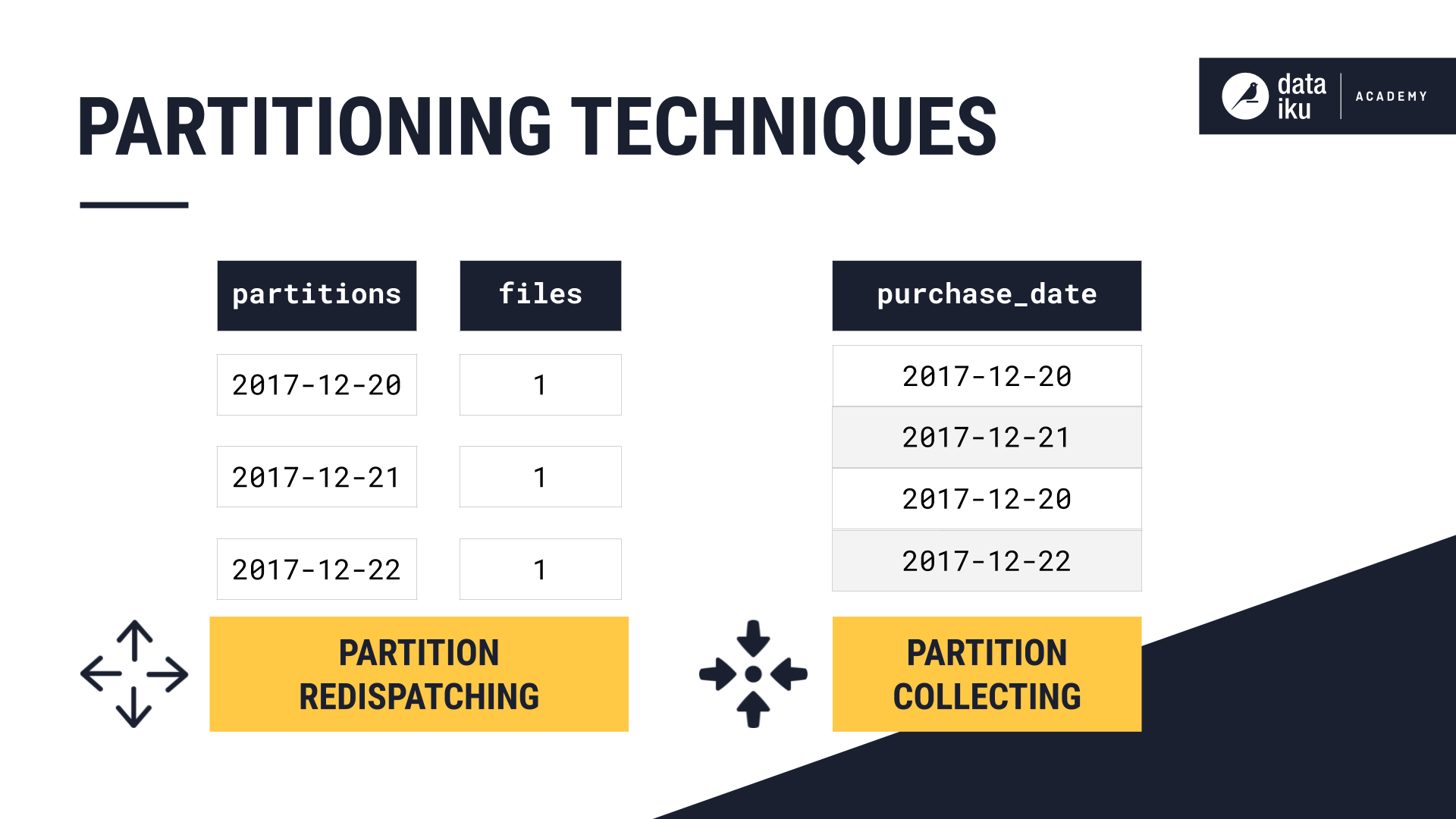
We can apply two techniques when working with partitioned and non-partitioned datasets in a Flow: redispatching and collecting.
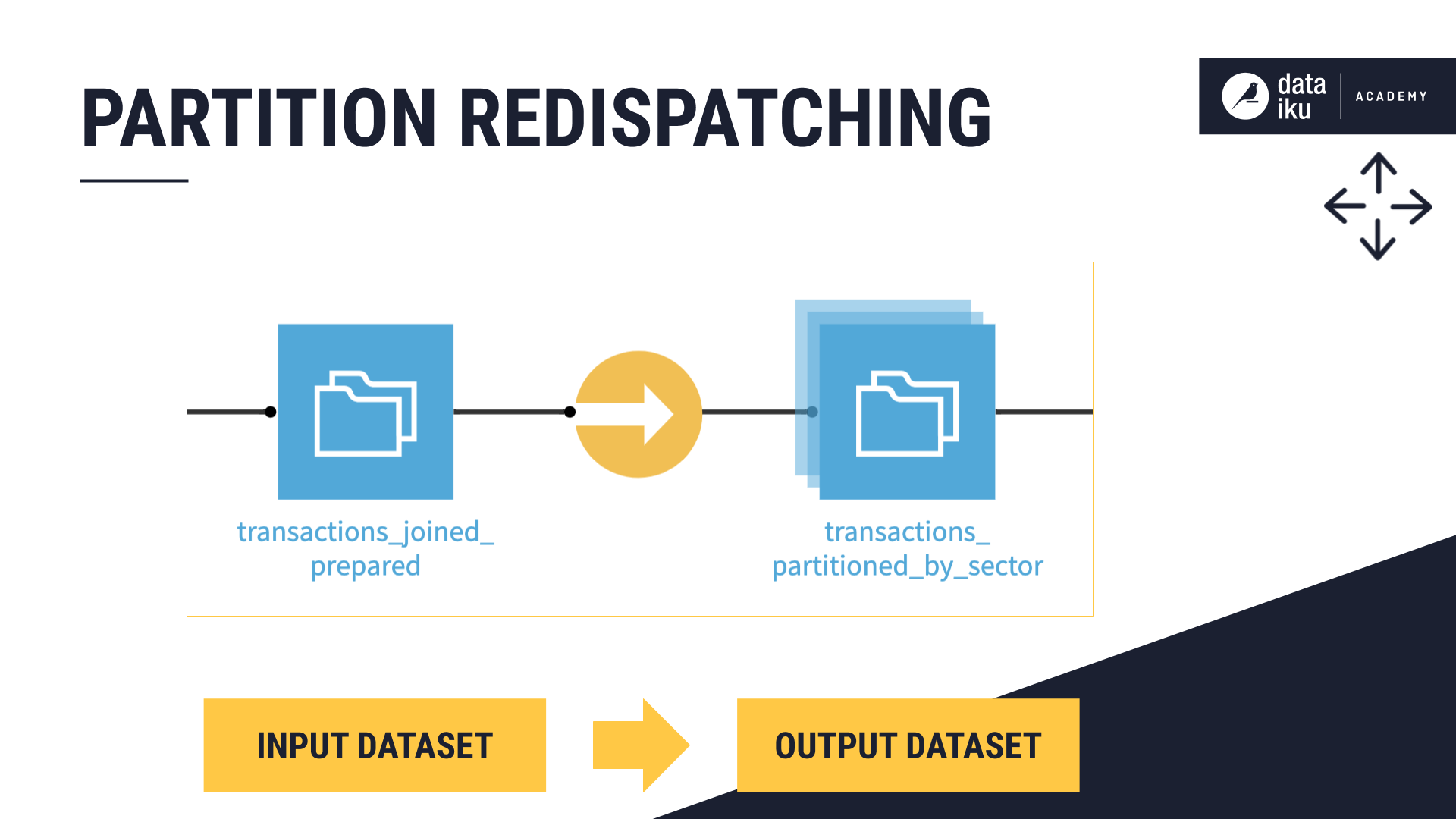
Redispatching partitions#
Redispatching allows us to partition a non-partitioned dataset in the Flow.
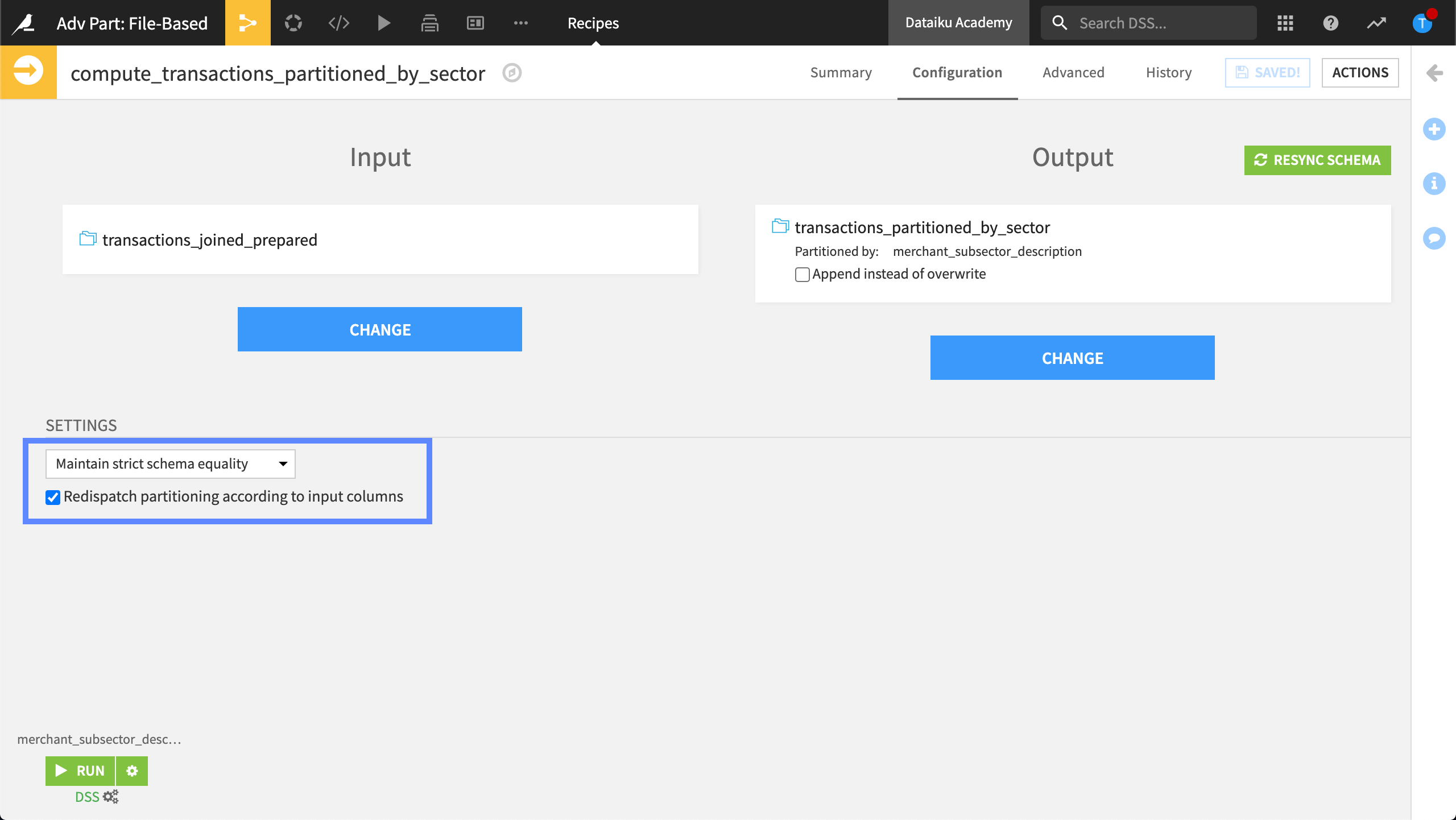
The Redispatch partitioning according to input columns option is found in the Prepare and Sync recipes.

When we select the Partition Redispatch option, Dataiku reads all the input data at once, sending each row to exactly one partition, depending on the values of its columns.

Let’s say we have a non-partitioned transactions dataset containing merchant subsector information. We could partition this dataset by merchant subsector using the Sync recipe.
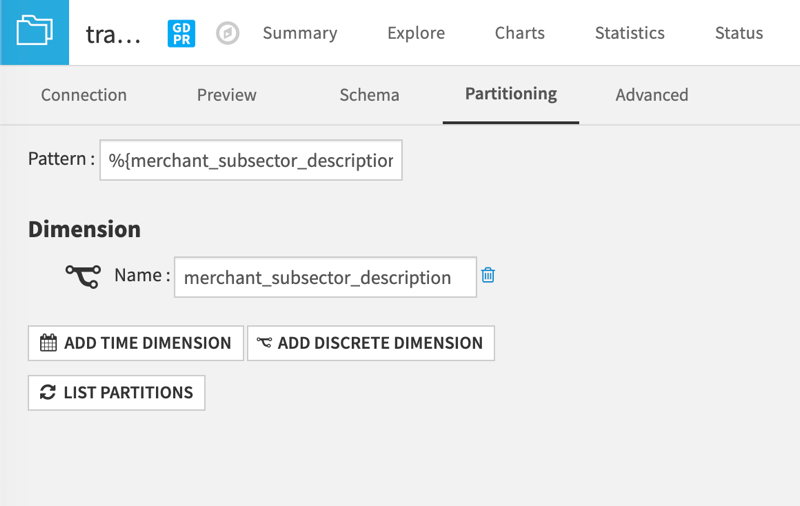
After adding the Sync recipe and naming the output dataset, we need to activate the partitioning. We accomplish this by selecting to add a discrete dimension in the Partitioning tab of the dataset’s Settings page.
Now we can finally build our partitions. To do this, we open our Sync recipe again and select the redispatching option.
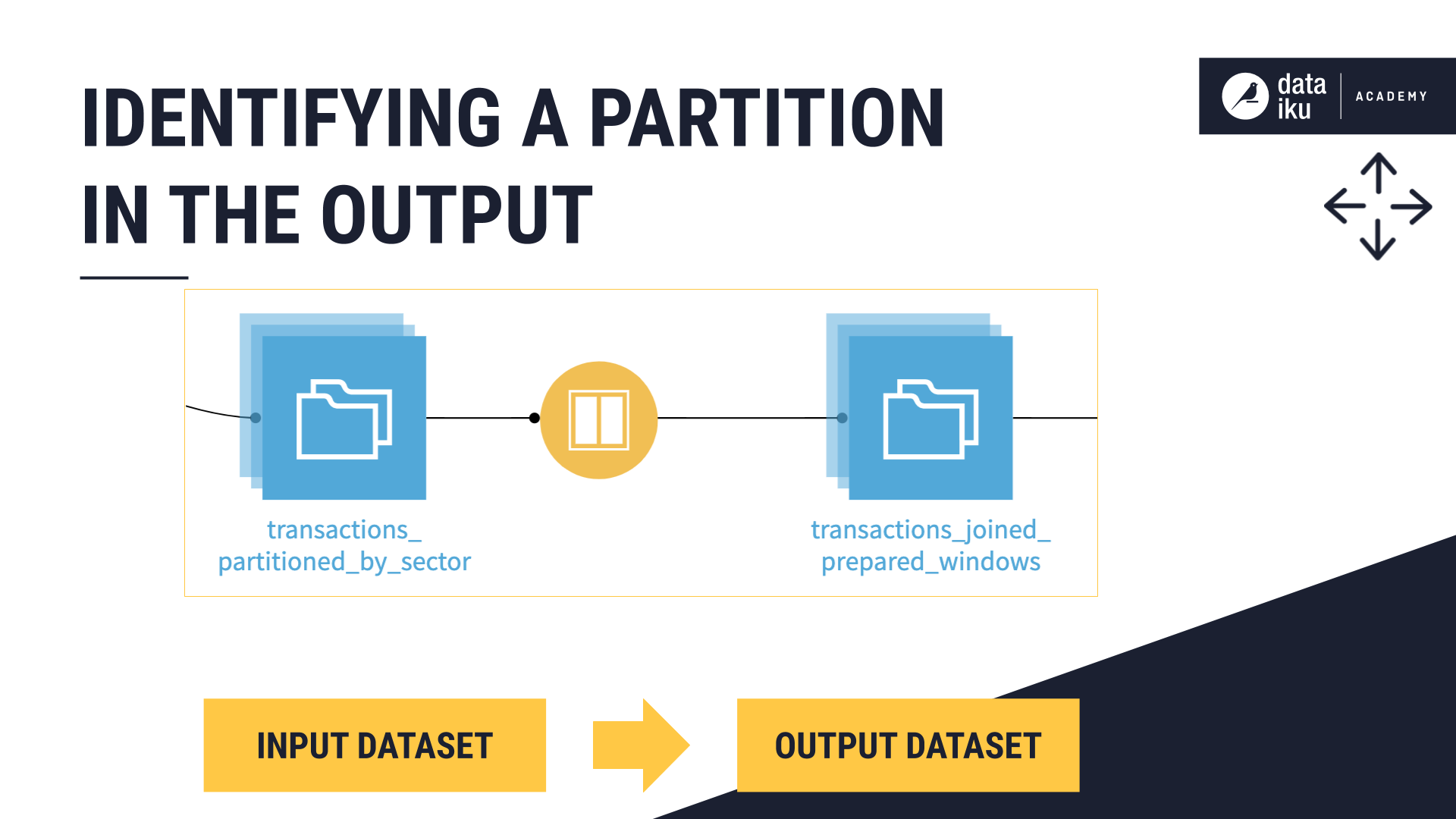
Target identifier#
If we want to specify the target identifier, or the partition identifier in the Recipe Run options, we’ll have to use an input dataset that already has partitioning dimensions defined.
In this example, we’ll use a Window recipe to build a new output dataset.
In the Settings step of the recipe, we’ll specify three subsectors, by typing the string value, gas/internet/insurance.
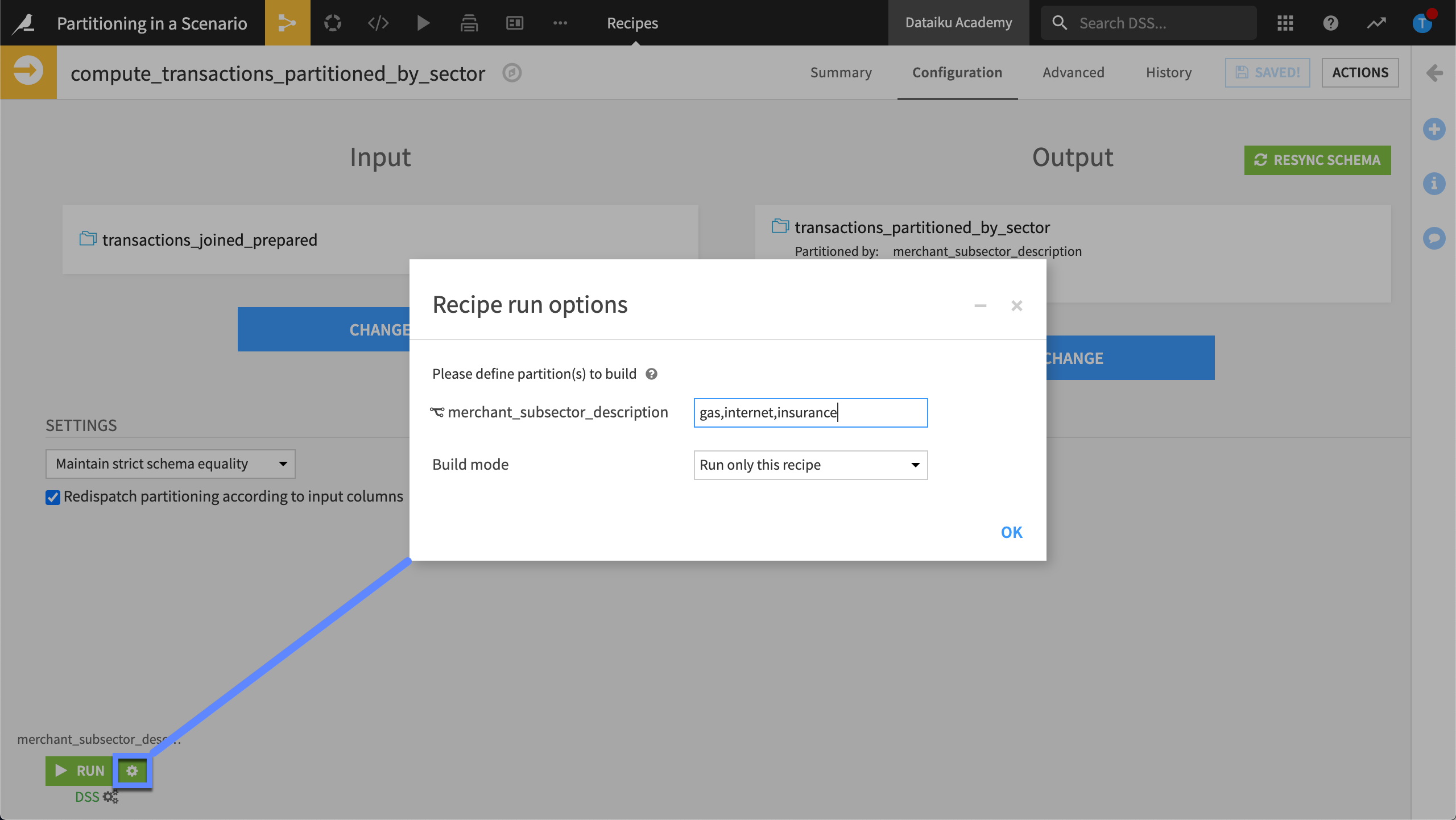
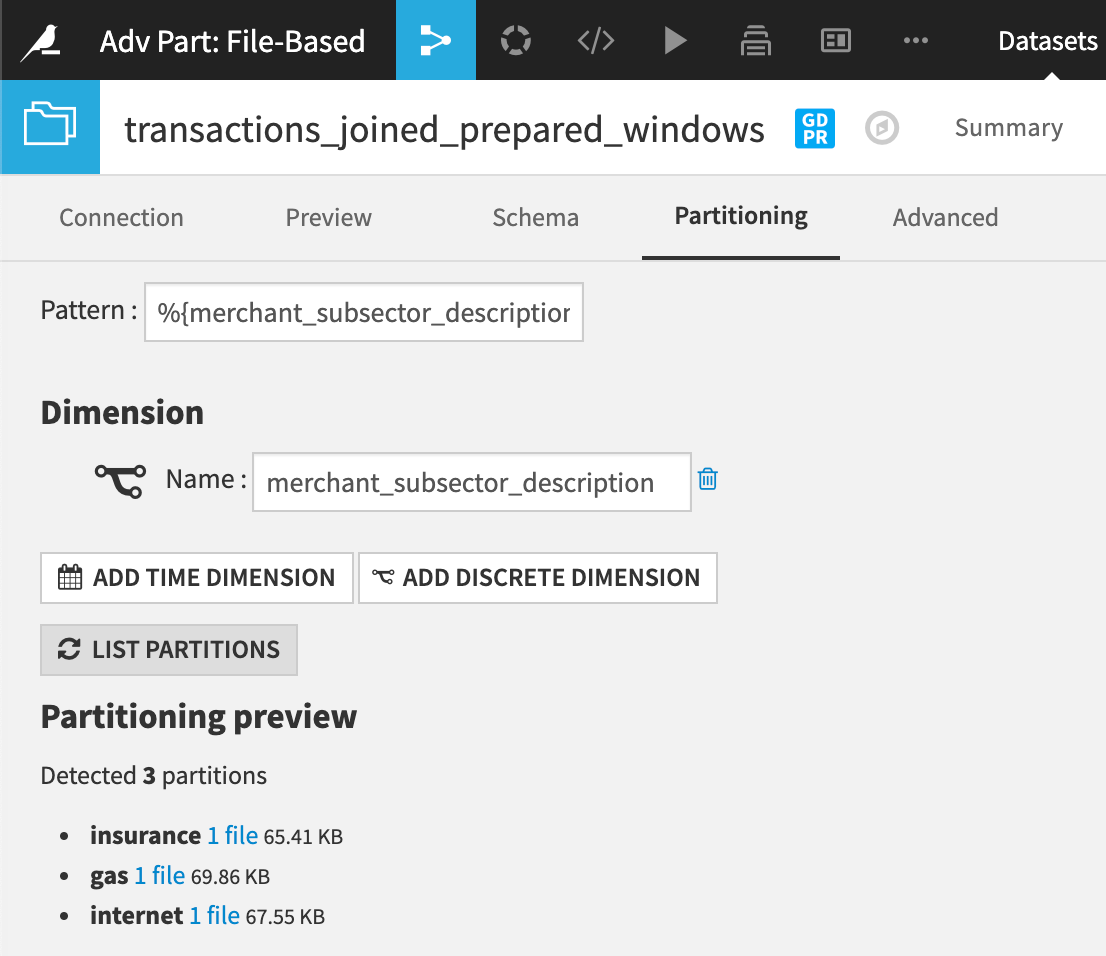
This recipe will build the gas, internet, and insurance partitions of the input dataset, giving us three partitions in the output dataset.
Collecting partitions#
Collecting partitions allows us to build a non-partitioned output from a partitioned dataset in the Flow. Partition collecting can be thought of as partition redispatching in reverse. We can apply this technique when we want to go from a partitioned dataset to a non-partitioned dataset.

This technique isn’t an option found in a recipe. Instead, we can apply it through the use of specific partition dependency function types.
To clarify, we’ll use an example. Let’s say we now want to “collect” our merchant subsector partitions and create a non-partitioned output.
To do this, we add a Prepare recipe, name our output dataset, and create the recipe. In the Input/Output step, we select All Available as the partition dependency function type.
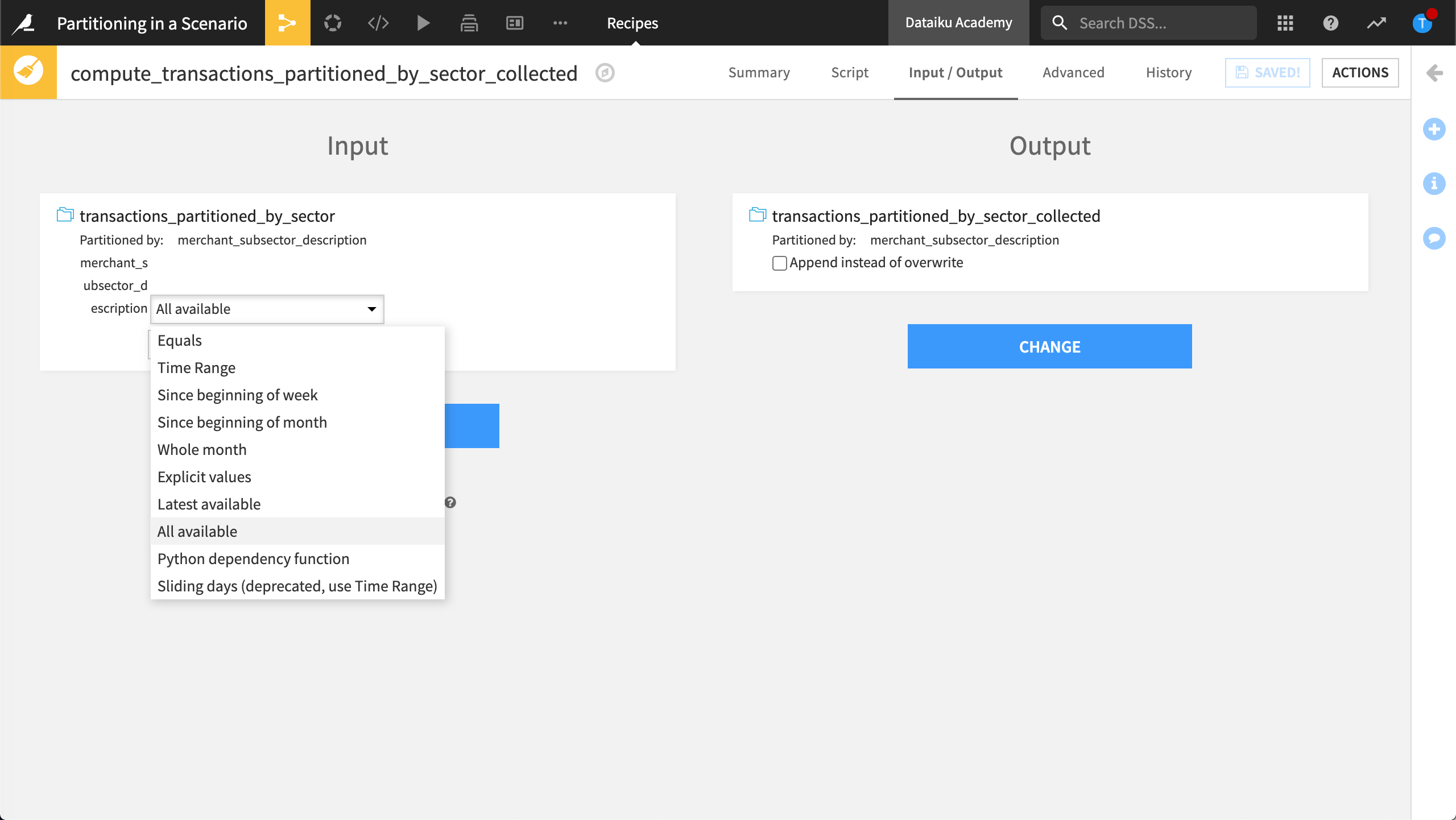
All Available means all available input partitions will be processed when we run the recipe and “collected” into a single partition.
Similarly, we could create a non-partitioned dataset that contains only the latest partition. To do this, we set the partition dependency function type to Latest Available.
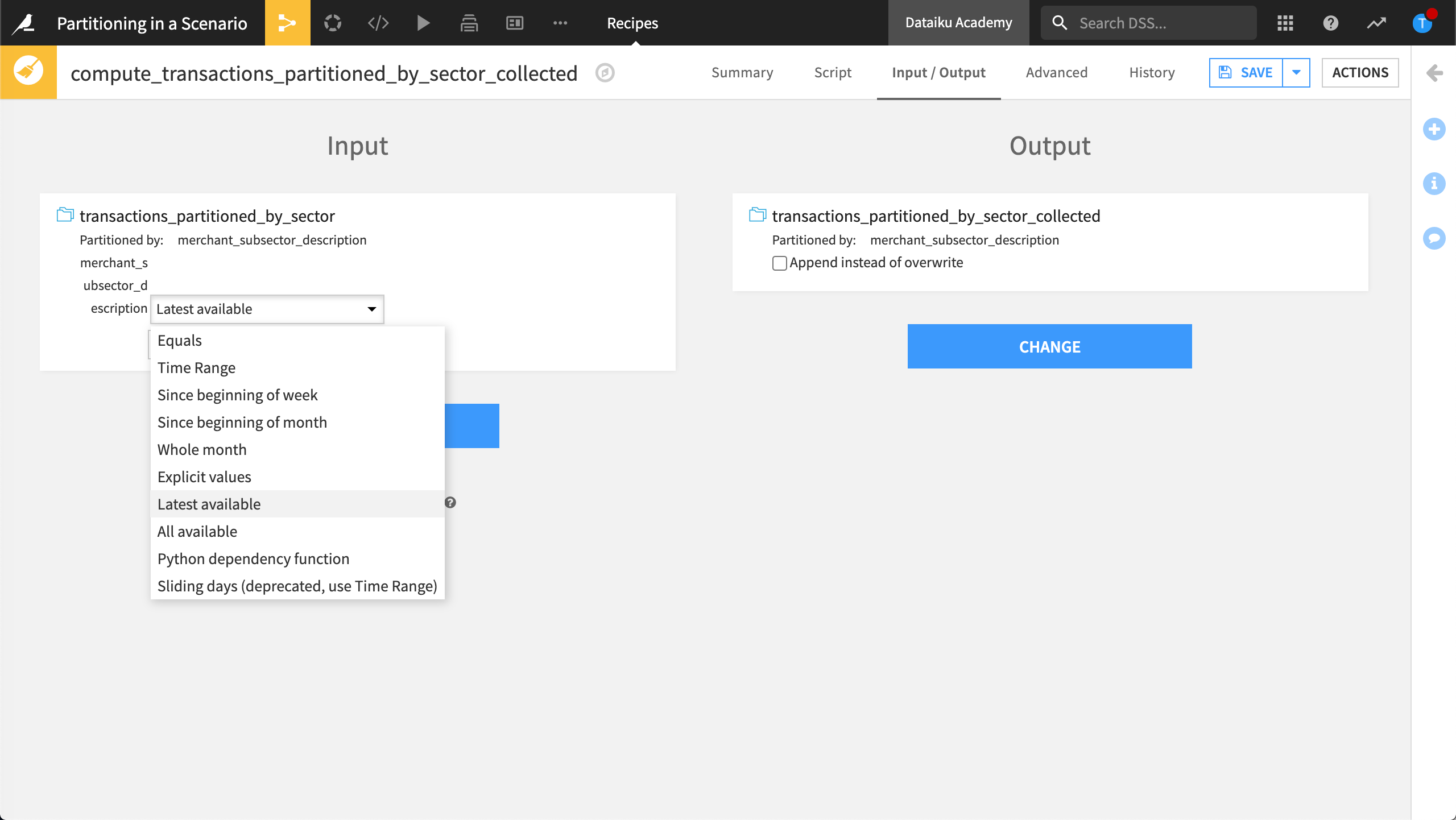
Dataiku would collect only the latest partition. Since this dimension isn’t time-based, the latest partition collected is the last alphabetically.
Next steps#
In this lesson, we learned about partition redispatching and collecting. Now you can try applying your knowledge to many different partitioning situations in a Flow.