
Concept | Partitioning by pattern#
In this tutorial, we partitioned the transactions_copy dataset by day using information in the purchase_date column.
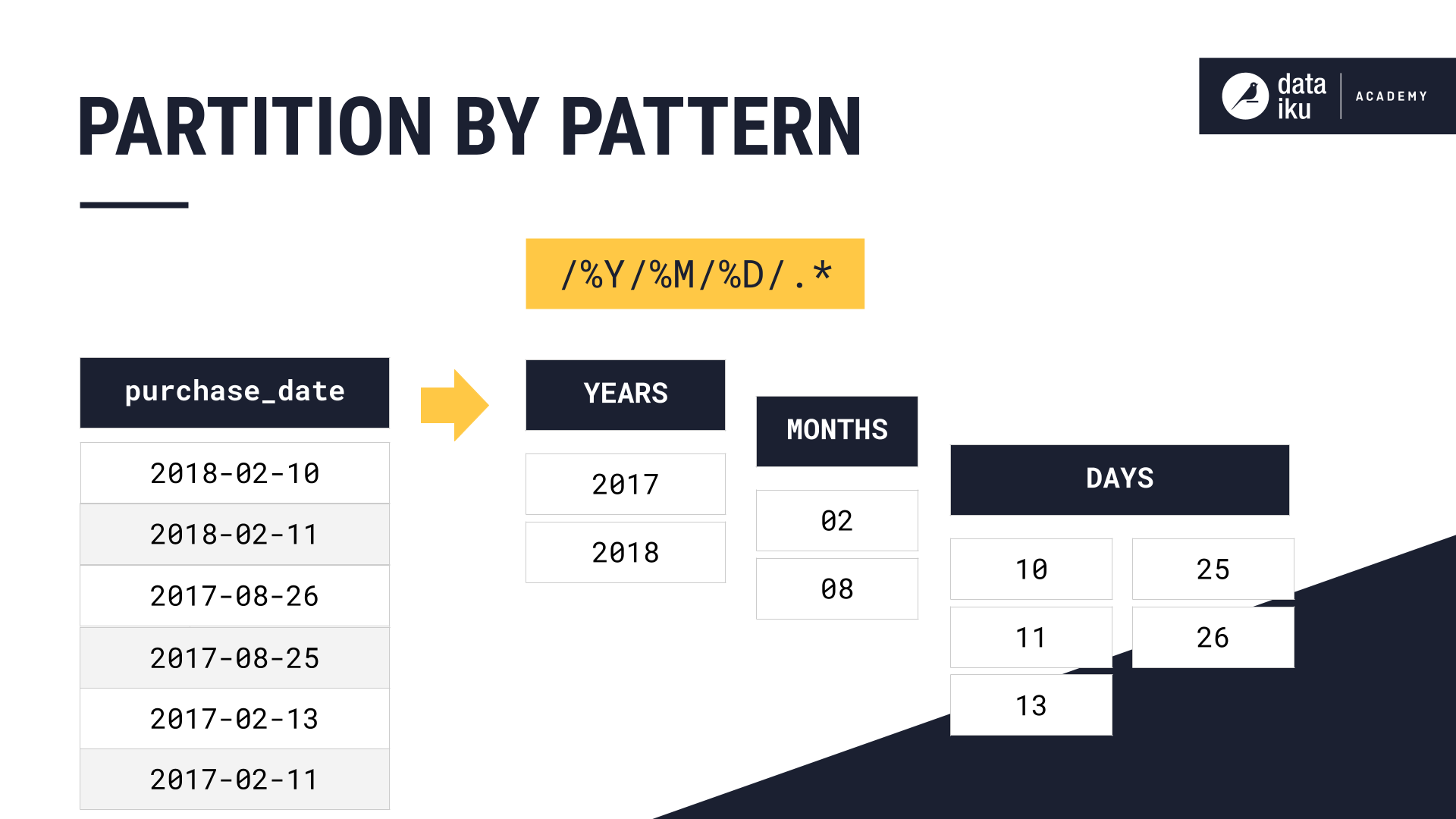
The specific pattern we used to partition the output dataset is %Y-%M-%D/.*.
How does Dataiku use this pattern to partition the output dataset?
When our dataset is stored on the filesystem, Dataiku uses this pattern to write the data on the filesystem connection. Its precision will vary depending on the granularity we use.
To partition the dataset by day, it’s necessary to specify a year (%Y), month (%M), and day (%D) pattern, because Dataiku needs all three pieces of information to identify a single day.
The / in the pattern delineates a hierarchy in the directory. For example, the pattern /%Y/%M/%D/.* tells Dataiku to create the tree structure “YEAR/MONTH/DAY/YOUR_DATA”.
Dataiku then uses this pattern to dispatch the dataset’s underlying files across the appropriate partitions. For example, let’s say our dataset contains the following rows and we’ve asked Dataiku to partition by “Day” of purchase_date using the pattern %Y-%M-%D/.*:
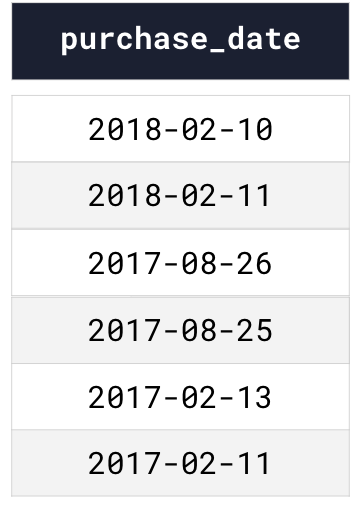
To create our partitions using this pattern, Dataiku will need to create one partition per day. To do this, Dataiku starts the hierarchy using YEAR–creating as many root values of YEAR as there are distinct years in the data. Then, each root value of YEAR will contain each distinct MONTH value. Finally, each root value of MONTH will contain each distinct DAY value. The result is:
To create a slightly simpler tree structure, you could use the pattern %Y-%M-%D/.*. This tells Dataiku to create the structure: “YEAR-MONTH-DAY/YOUR_DATA”.
With either structure, there will be as many directories as there are distinct days in the data.