
Tutorial | ML algorithm plugin component example#
You can extend the list of algorithms available in Dataiku’s Visual ML tool by creating a custom machine learning component in a plugin.
For example, say you have a co-worker who is familiar with the fundamentals of discriminant analysis, but is uncomfortable writing the code to call the scikit-learn implementation of the algorithm. The default list of algorithms available in Dataiku does not include discriminant analysis, but we can add it as a plugin component.
Creating the plugin component#
From the Application menu, select Plugins.
Select Add Plugin > Write your own.
Give the new plugin a name like
discriminant-analysisand click Create.This create a plugin with no components.
Click +Create Your First Component and select Prediction Algorithm.
Give the new component an identifier like
linearand click Add.
Edit definitions in algo.json#
First, let’s have a look at the algo.json file. This describes the elements of the custom algorithm, including the parameters that the user will have to specify when using the algorithm.
At the top of the JSON are some basic metadata. Making changes here helps to make the algorithm easier to identify in the Visual ML tool.
Update the algorithm label to be more descriptive. On line 5, change the code to read:
"label": "Linear Discriminant Analysis",
Update the algorithm description. On line 8, change the code to read:
"description": "A classifier with a linear decision boundary, generated by fitting class conditional densities to the data and using Bayes' rule.",
Discriminant analysis can be used for classification problems. Update line 16 with the correct prediction types for this algorithm:
"predictionTypes": ["BINARY_CLASSIFICATION", "MULTICLASS"],
There are a number of parameters in the scikit-learn implementation of discriminant analysis. As a first pass at, let’s include the solver to use, the number of components for dimensionality reduction, and the tolerance threshold for rank estimation in the SVD solver as parameters our colleague can specify. We can make these available in the JSON as follows.
"params": [
{
"name": "solver",
"label": "Solver",
"description": "Solver to use.",
"type": "MULTISELECT",
"defaultValue": ["svd"],
"selectChoices": [
{
"value":"svd",
"label":"Singular value decomposition"
},
{
"value":"lsqr",
"label":"Least squares"
},
{
"value":"eigen",
"label": "Eigenvalue decomposition"
}
],
"gridParam": true
},
{
"name": "n_components",
"label": "Number of components",
"description":"Number of components (<= min(n_classes - 1, n_features)) for dimensionality reduction. If None, will be set to min(n_classes - 1, n_features).",
"type": "DOUBLES",
"defaultValue": [1],
"allowDuplicates": false,
"gridParam": true
},
{
"name": "tol",
"label": "Tolerance",
"description": "Threshold for rank estimation in SVD solver.",
"type": "DOUBLES",
"defaultValue": [0.0001],
"allowDuplicates": false,
"gridParam": true
}
]
Edit code in algo.py#
Now let’s edit algo.py. The default contents include an example of code for the AdaBoostRegressor algorithm. To make this appropriate for our discriminant analysis plugin:
Change line 3 to import linear discriminant analysis.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
Change line 24 to use linear discriminant analysis.
self.clf = LinearDiscriminantAnalysis()
Using the component in a project#
Open a project and select a dataset.
Open a new Lab and create a predictive model.
In the Algorithms panel of the Design of the predictive model, turn the Linear Discriminant Analysis algorithm on.
Specify the settings you want, then click Train.
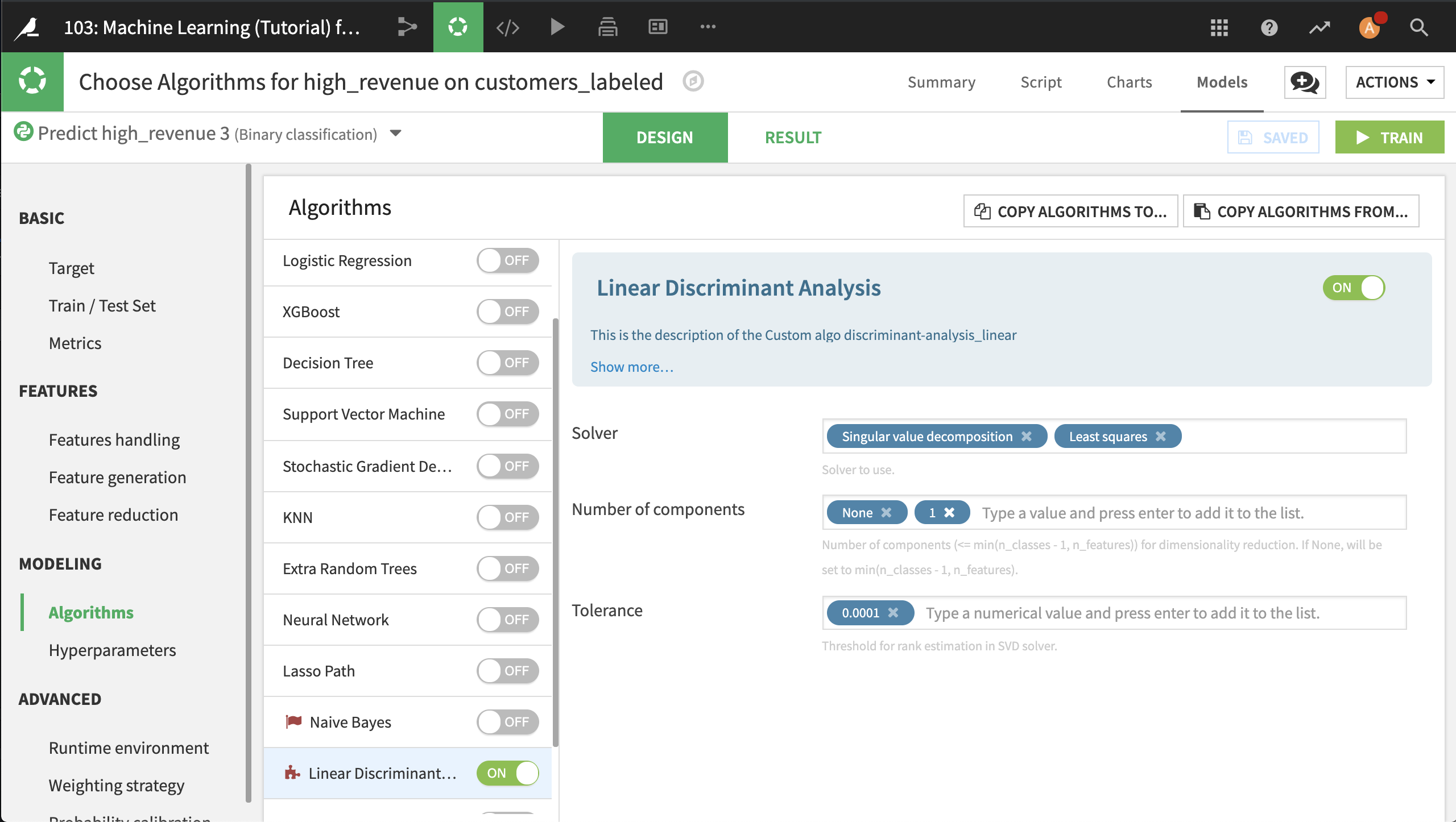
You can explore and deploy the resulting model in the same way you would any other model produced through the Visual ML tool.