
Concept | Custom metrics, checks, data quality rules & scenarios#
Watch the video or read the summary below.
In other articles, we’ve explored creating metrics and checks, as well as scenarios, using only the native visual tools.
When more customization is needed than what the visual options can provide, Dataiku allows users to implement custom solutions with Python and/or SQL code. This is the same dynamic found in other areas of Dataiku, such as data preparation or machine learning.
In this article, we’ll introduce how users can code their own custom:
Metrics
Checks
Data quality rules
Scenarios (including triggers and steps)
We’ll also discuss how these customized components can be wrapped into visual plugins for easy reuse by non-coding colleagues.
Custom metrics#
We have already explored many of the built-in options for creating metrics. If, however, none of the built-in metrics achieve our exact objectives, we can create our own Python probe, or, in the case of a dataset in an SQL database, a SQL query probe.
Let’s focus on writing our own Python probe. After selecting a code environment, Dataiku provides some starter code for a process function.
The first parameter is the Dataiku dataset or folder for which we’re creating the metric.
The second is the partition ID if the dataset or folder is partitioned.
The function returns a dictionary with the name and value of the metrics.
As a simple example, let’s compute the number of records of the dataset, accessing the pandas DataFrame through the get_dataframe() function.
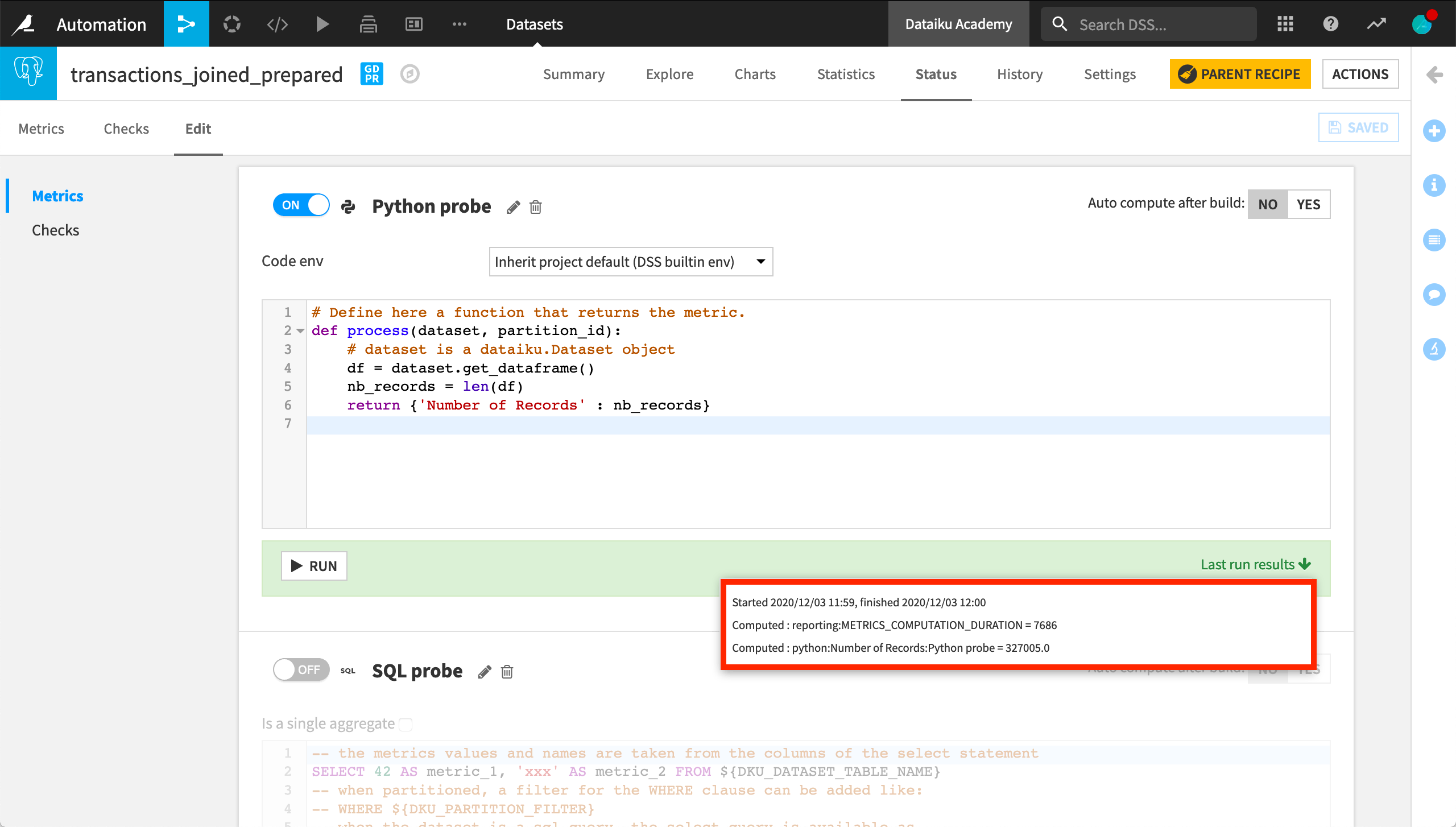
Once the function is ready, we can find our custom metric in the list of available metrics. Not surprisingly, it returns the same result as the built-in record count function.
Custom checks#
Now let’s create a custom check using the previous custom metric. The starter code for the process function in this case suggests three input parameters:
A dictionary of the last values of the metrics.
The dataset or folder for which you are creating the check.
The partition ID if the dataset or folder is partitioned.
Let’s write a check to know if our dataset has more than 100,000 rows. To find the dictionary key corresponding to the metric, we can return to the Metrics page and check the last run result.
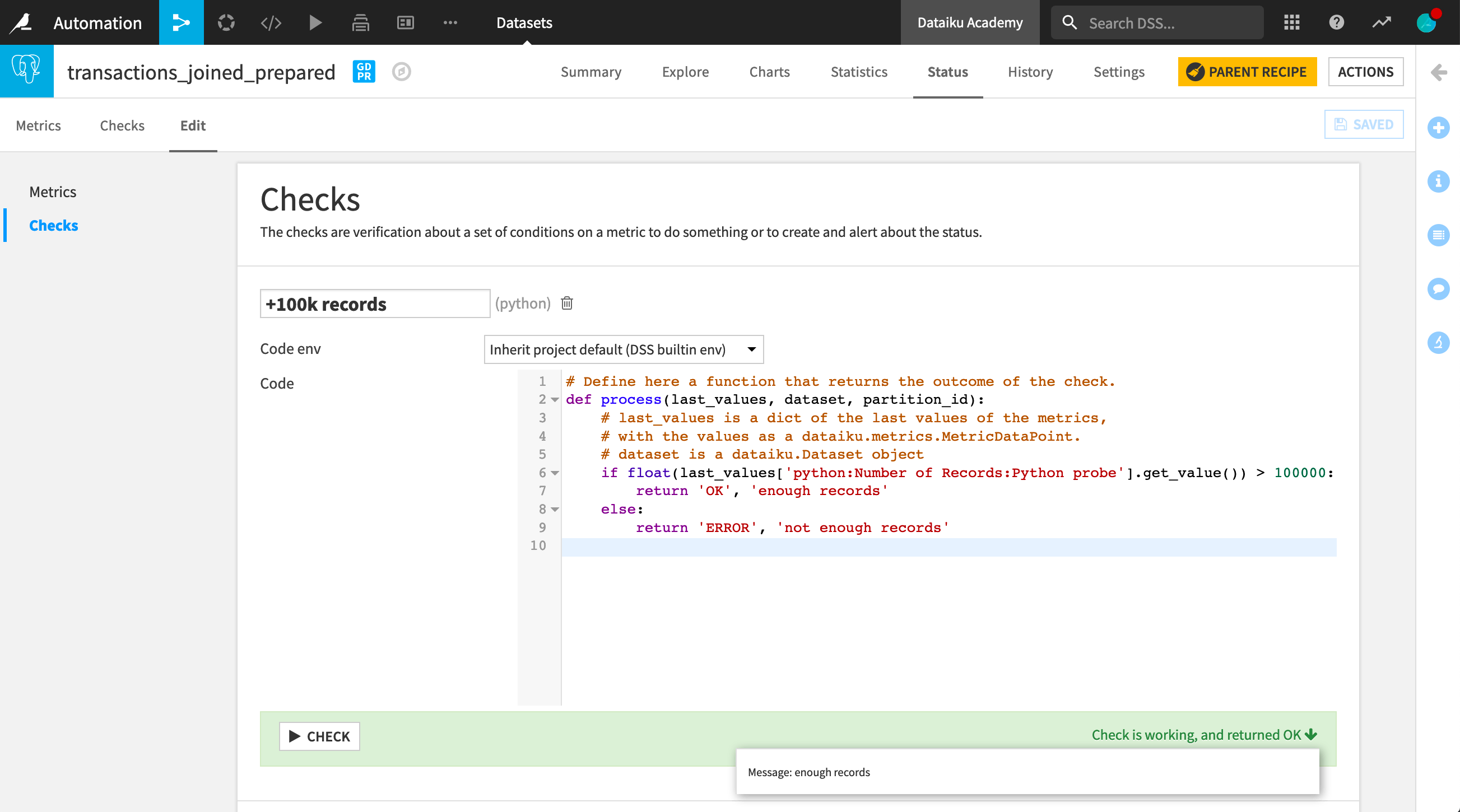
Once we’ve finished writing the check, we can run it and observe the status message. We can also display it on the Checks page as we would for a metric.
Custom data quality rules#
Important
Data quality rules are available in Dataiku versions 12.6 and later. For versions 12.5 and before, use metrics and checks to verify data quality.
The custom data quality rules are located among other rules and can be found as Python code when selecting the rule type.
Let’s create a rule that indicates if the number of rows in a dataset is sufficient for our use.
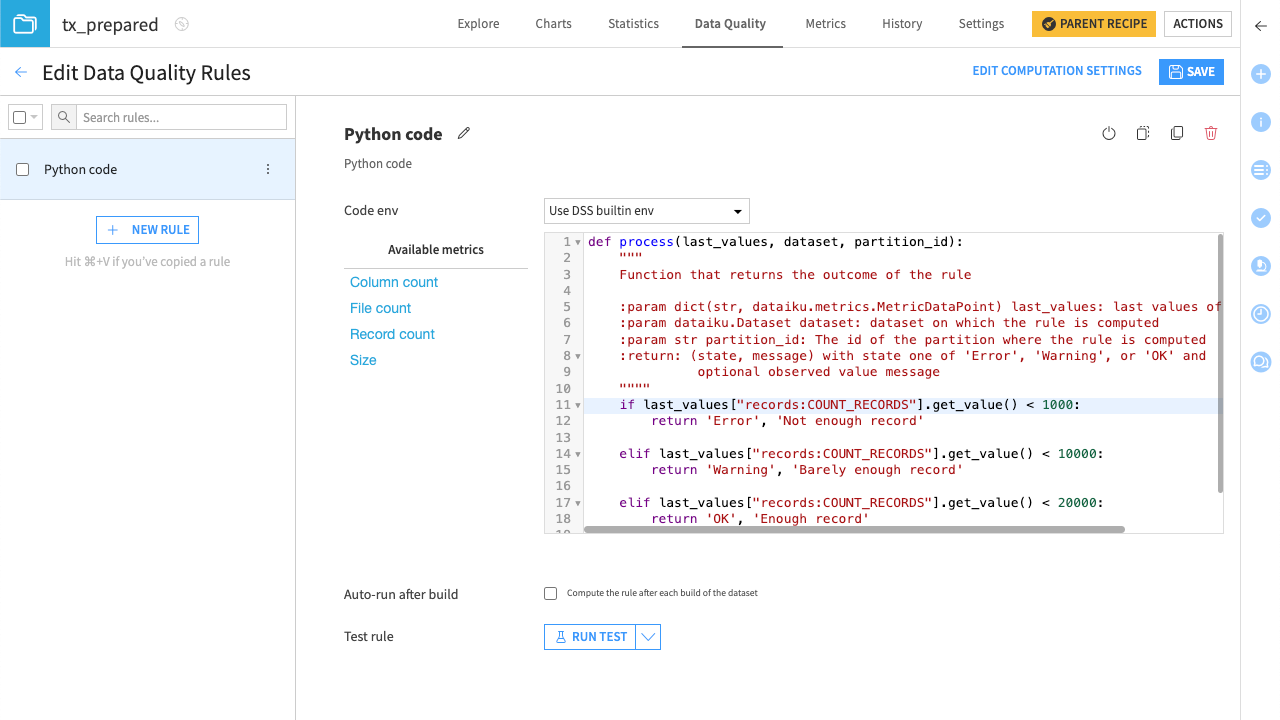
Once the rule is set, you can run tests on it.
Custom scenarios#
Now let’s look at custom scenarios, including custom steps and triggers. We have the option of creating a scenario with our own Python script. But let’s first look at creating custom triggers and steps with the built-in, step-based scenario option.
Custom triggers#
We’ve already explored built-in triggers based on time or a dataset change. With a dataset stored in an SQL database, it’s possible to run an SQL query at some specified interval, and launch the scenario if the query output changes.
For example, we may want to activate the scenario only if the maximum purchase date in our transactions dataset changes.
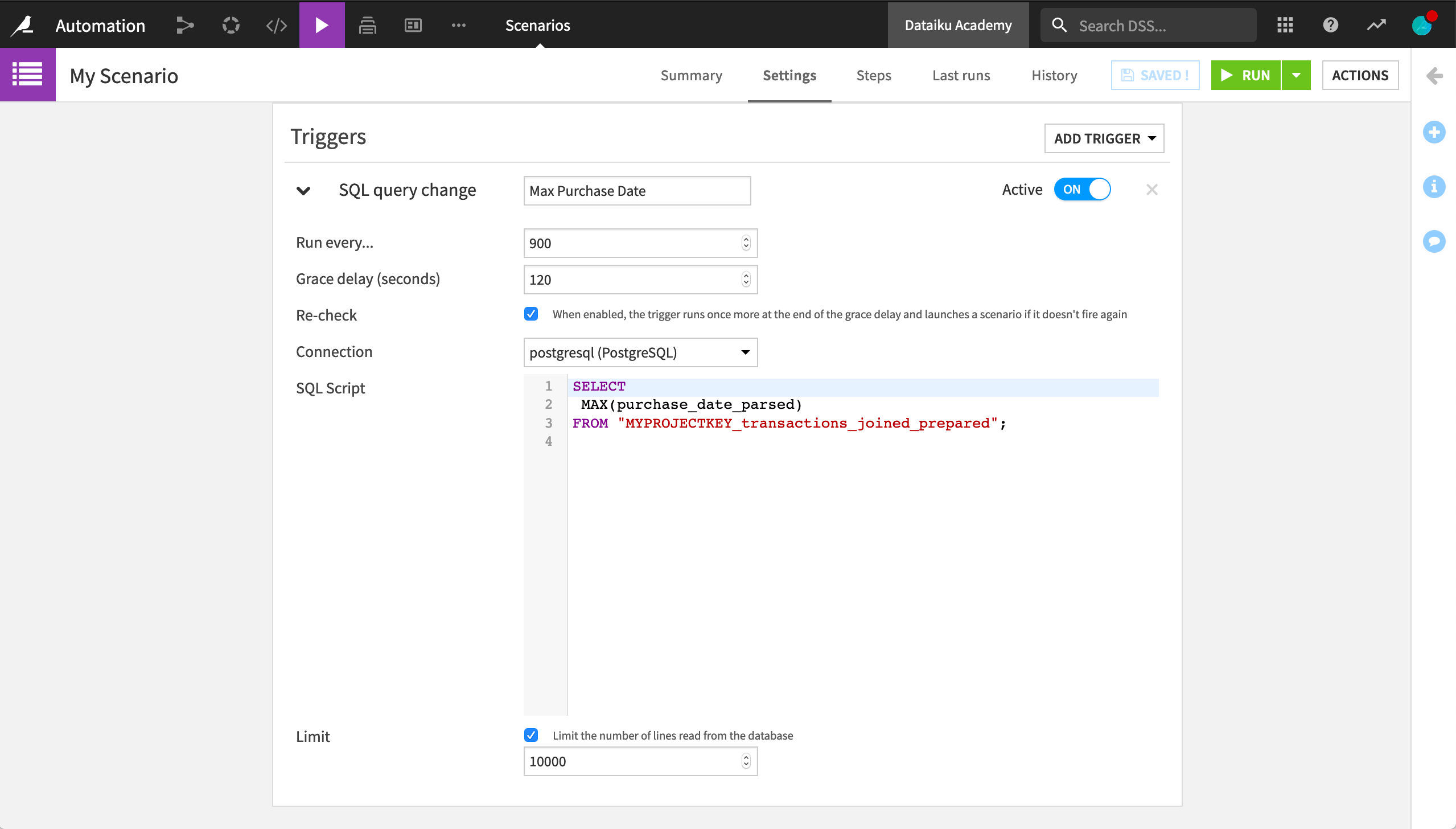
Note
In actual usage, MYPROJECTKEY would be replaced with the actual project key.
Triggers can also be fully customized with Python code. All we need is a trigger class and the fire method. For example, we can implement a trigger that launches a scenario once a day, if it’s a working day in a specific country, such as France. We’ll use the datetime and workalender Python libraries so we need a code environment that includes them.
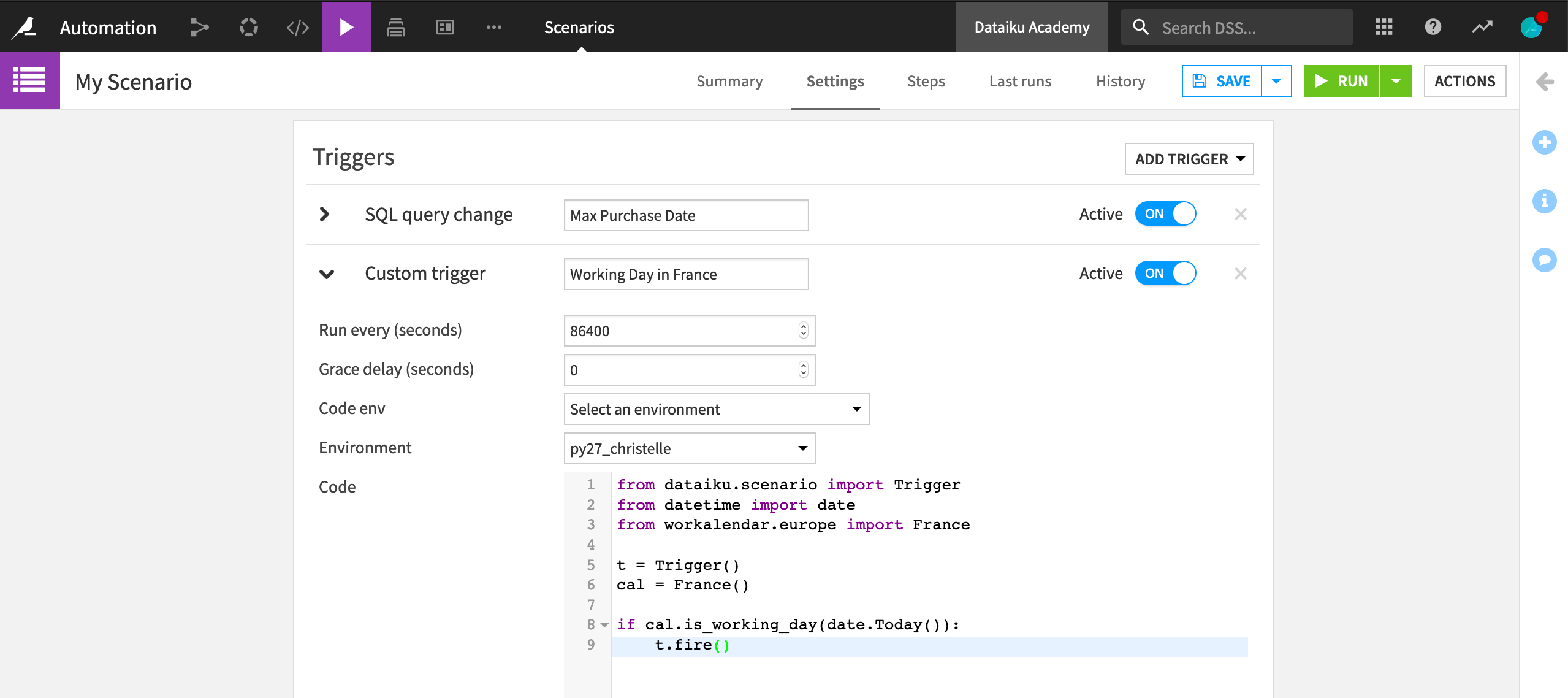
Custom steps#
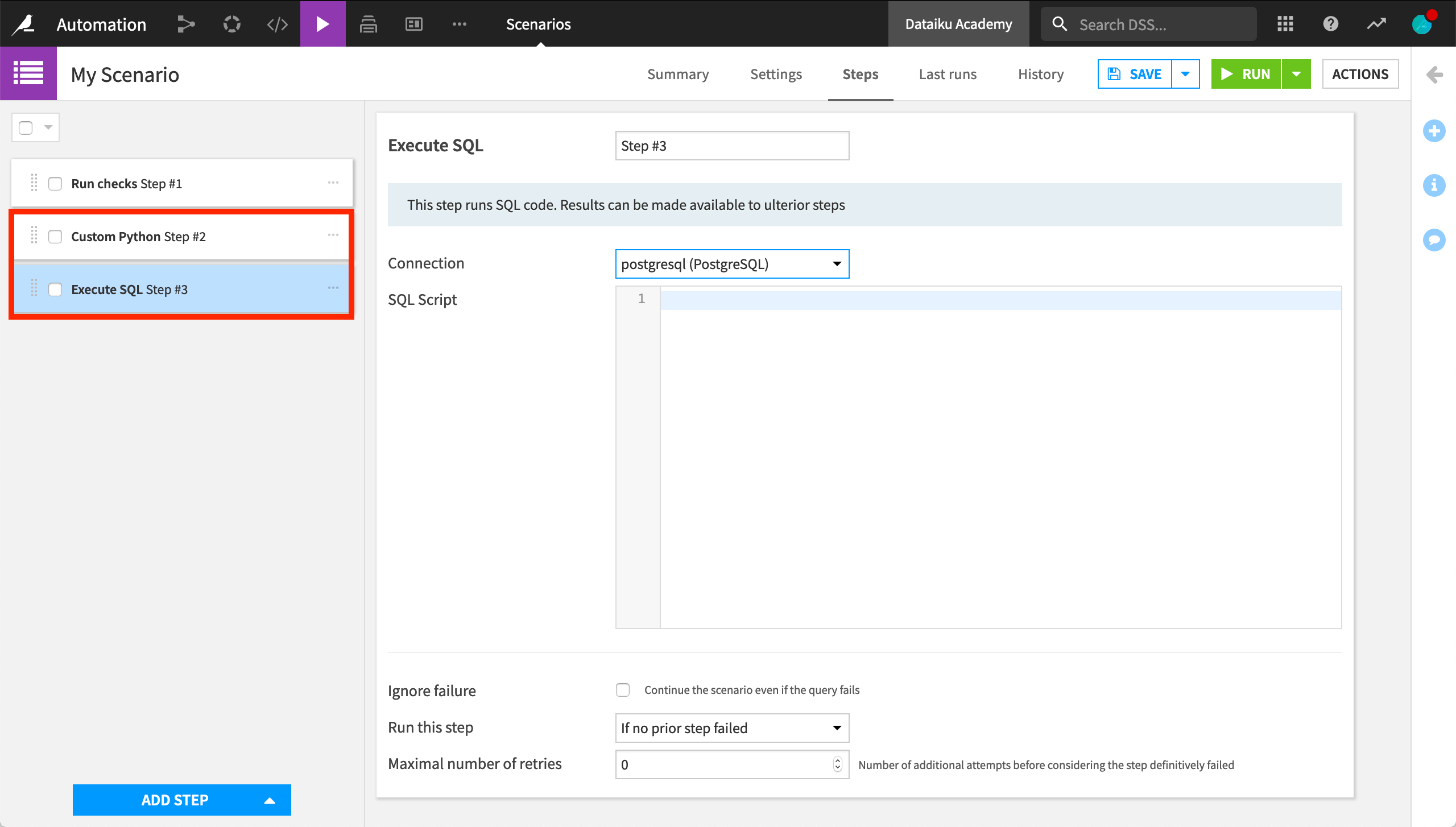
Once we have our custom trigger, we can add steps as we would to a normal scenario. Perhaps, for example, we want to add a Run checks step so that our custom check will run once every working day in France.
We can also add custom steps to a step-based scenario. For example, we can add a step that runs a Python script in the context of a scenario. Or, we can have a step that executes one or more SQL statements on a Dataiku connection. The output of the query, if there is one, is available to subsequent steps as variables. This is one example of how combining both custom and built-in steps in a scenario can be beneficial.
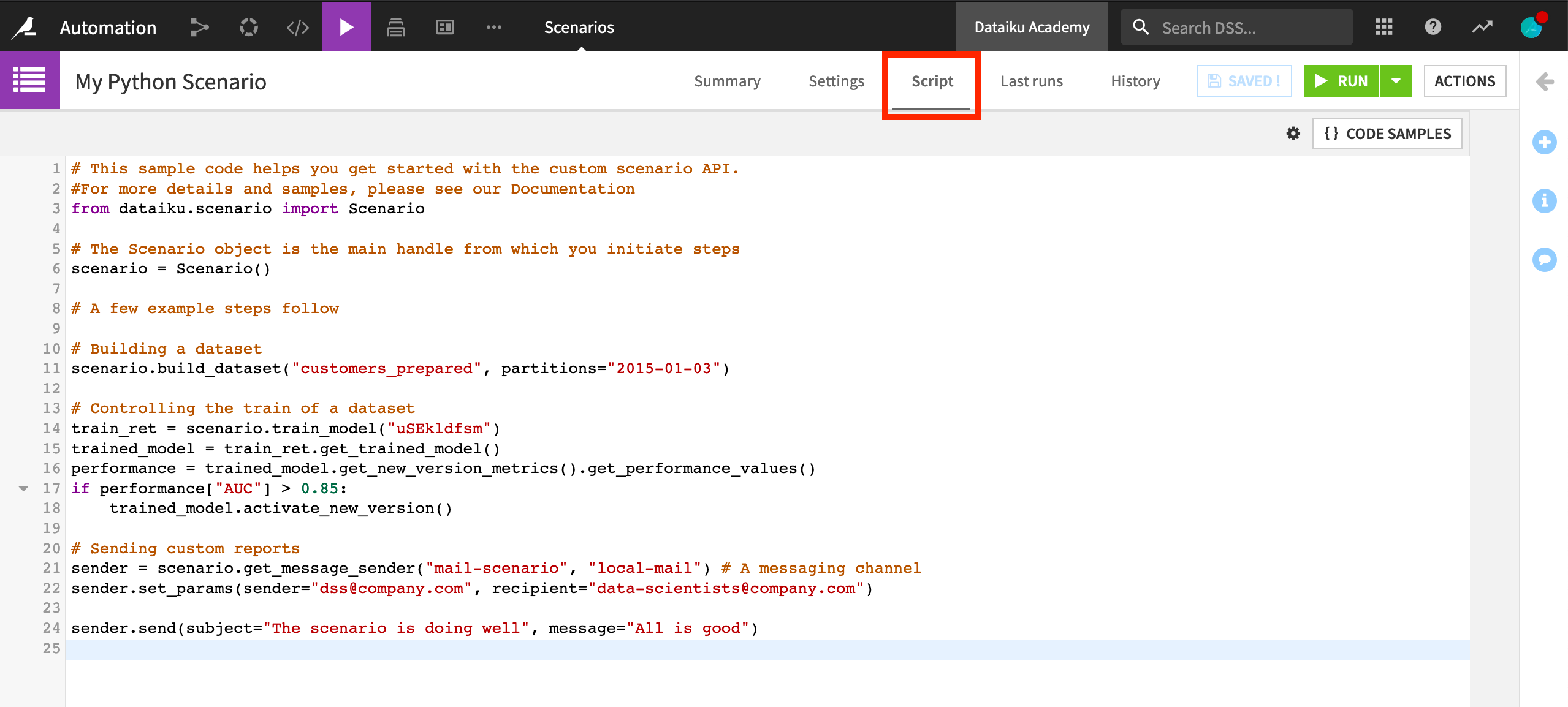
Python scenarios#
Instead of a custom step within a step-based scenario, we also have the option of an entirely custom Python scenario. Here, we can see the Script tab has replaced the Steps tab. The Script tab provides some sample Python code to get started with the scenario API.
Plugin metrics, checks, and scenarios#
We have now introduced how it’s possible to code our own metrics, checks, and scenarios. However, we can also package these custom-coded elements as plugins, thereby extending the functionality of Dataiku.
Wrapping a visual interface on top of custom code can help enable wider reuse, particularly by non-coding colleagues. We could create custom metrics and checks, and then make them accessible to colleagues as a plugin.
The ML-assisted labeling plugin, for example, enables active learning techniques in Dataiku. One component of this plugin is a scenario trigger to automate the rebuilding of a model that assists in determining which sample is labeled next. Another component is a scenario step to compute metrics on the unlabeled data.
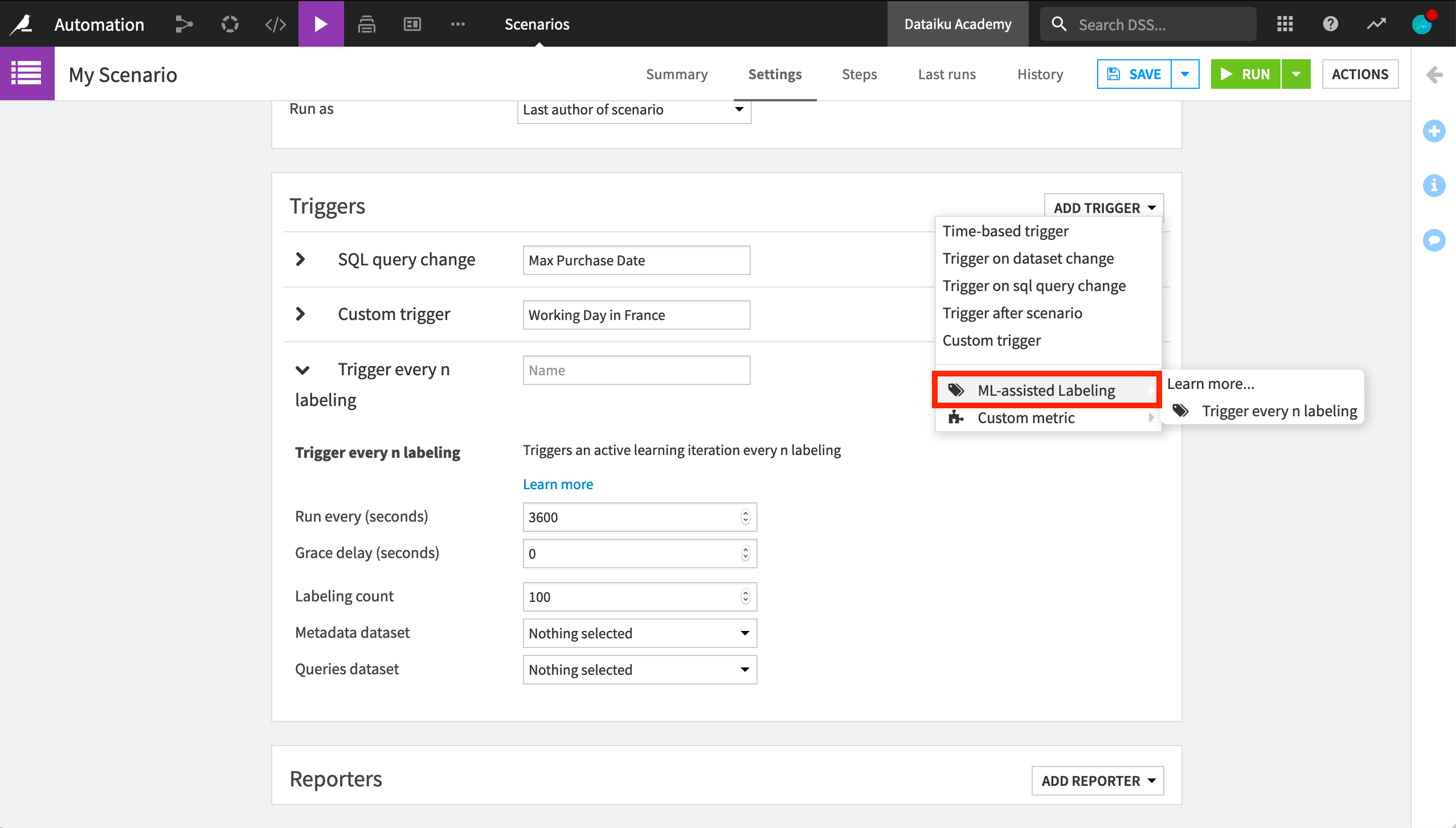
What was once custom code now has a visual interface that anyone can use.
Next steps#
You can extend your learning on custom automation in the reference documentation on Automation scenarios.